
ICC KYOTO 2024のセッション「AIの最新ソリューションや技術トレンドを徹底解説(シーズン7)」、全11回の⑦は、米国在住、エンジェル投資家として知られるNSV Wolf Capital 柴田 尚樹さんが登場。NSVの投資先を含めると、生成AI関連のデータソースは約1,000社あるそうです。そして話題は日本企業のLLMアプリ開発の実態と「AI Agent」へ。大好評の解説は必読です。ぜひご覧ください!
ICCサミットは「ともに学び、ともに産業を創る。」ための場です。そして参加者同士が朝から晩まで真剣に学び合い、交流します。次回ICCサミット FUKUOKA 2025は、2025年2月17日〜 2月20日 福岡市での開催を予定しております。参加登録は公式ページをご覧ください。
本セッションのオフィシャルサポーターは Notion です。
▼
【登壇者情報】
2024年9月2〜5日開催
ICC KYOTO 2024
Session 11C
AIの最新ソリューションや技術トレンドを徹底解説(シーズン7)
Supported by Notion
(スピーカー)
青木 俊介
チューリング株式会社
取締役 共同創業者
柴田 尚樹
NSV Wolf Capital
Partner
砂金 信一郎
Gen-AX株式会社
代表取締役社長 CEO
山崎 はずむ
株式会社Poetics
代表取締役
(リングサイド席)
上地 練
株式会社Solafune
代表取締役CEO
小田島 春樹
有限会社ゑびや / 株式会社EBILAB
代表取締役社長
柴戸 純也
株式会社リンクアンドモチベーション
執行役員
武藤 悠輔
株式会社 ALGO ARTIS
取締役 VPoE
(モデレーター)
尾原 和啓
IT批評家
▲
▶「AIの最新ソリューションや技術トレンドを徹底解説(シーズン7)」の配信済み記事一覧
エンジェル投資家であり、NSV Wolf Capitalの柴田さん

柴田 なるべくサクッとお話ししたいと思います。
柴田 尚樹といいます。先ほどからご紹介いただいているように、普段はアメリカにいます。
▼
柴田 尚樹
NSV Wolf Capital
Partner
NSV Wolf Capitalにて、パートナーとして、シリコンバレーの新興VCへのファンド投資、スタートアップへの直接投資を担う。エンジェル投資家として50社以上のスタートアップへ投資実績あり。楽天執行役員、東京大学助教を経て、スタンフォード大学の客員研究員として渡米。米国シリコンバレーでAppGroovesを起業。「決算が読めるようになるノート」を創業(2022年に事業譲渡)。東京大学大学院工学系研究科技術経営戦略学専攻 博士課程修了(工学博士)。著書は『MBAより簡単で英語より大切な決算を読む習慣』(日経BP)、『テクノロジーの地政学』(日経BP)
▲
私はもともとエンジニアでアメリカで起業もして、1つ小さい会社を売って、1つはシャットダウンして、去年(2023年)は1年間ほぼ無職でした。
その間ゴルフを100ラウンドくらいしたり、エンジェル投資をたくさんしたりして過ごしていました。

日本の人からすると私は、決算が読めるようになるノートのシバタナオキだと思うので、もし読んでいただいた方がいらっしゃれば、事業譲渡して私はもう書いていないのですが、ぜひそういう形で覚えておいていただければと思います。
今日の話は全部アメリカの話で、1年半くらいで約60社にエンジェル投資をしました。

最初はなかなかうまくいかなかった部分もあるのですが、だんだんここに書いてあるような皆さんが聞いたことのあるようなVCと……
尾原 シャレにならないぐらい良い筋のところと一緒に投資しているということですね。
柴田 はい、そうですね。
ずっと個人で投資していてもよかったのですが、個人でやるとお金がないのでVCをやろうということで、自分でファンドを作ろうかなとも思ったのですが、ちょうど私がやりたかったモデルをやっているVCがありました。
それがNSV Wolf Capitalで、Partnerとしてジョインすることになりました。
尾原 そうですね、NSV Wolf Capitalの校條(めんじょう) 浩さんはチップの時代のシリコンバレーの頃からのVCなので、本当にシリコンバレーインサイダーの古参の方ですよね。
柴田 そうですね。
NSV Wolf Capitalの投資戦略
柴田 少しだけ紹介させていただくと、NSV Wolf Capitalは普通のVCとは違って、まず我々がFund of Fundsで新興のマイクロVCに投資をするのです。

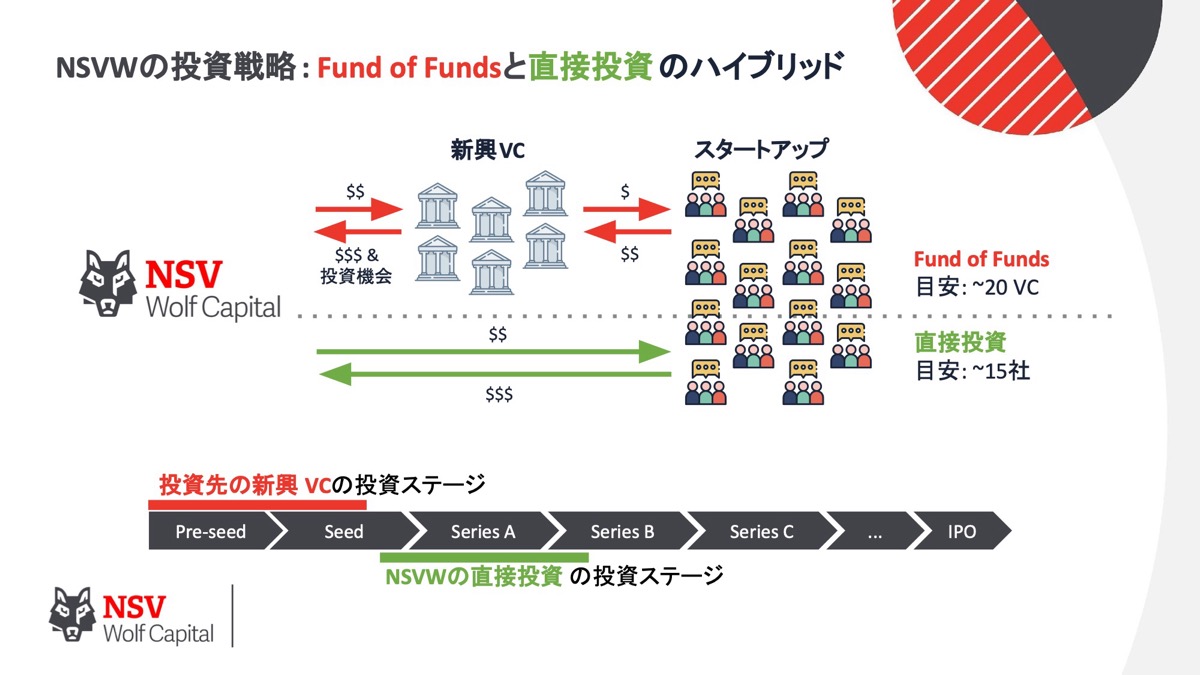
だいたい20ぐらいのマイクロVCに投資します。
それぞれのVCが50社ぐらいに投資するので、1,000社分ぐらい間接ポートフォリオのデータが入ってきます。
その中でマイクロVCはだいたいプレシードやシードのごく初期に投資をするので、大半の会社はだめになってしまいますが、生き残った会社にNSV Wolf Capitalから直接投資をするという普通のVCとは違うやり方です。
こちらのスライドにあるのは私がいいなと思ったモデルで、なぜいいかというと、VCは通常1つのファンドあたり30〜50社です。
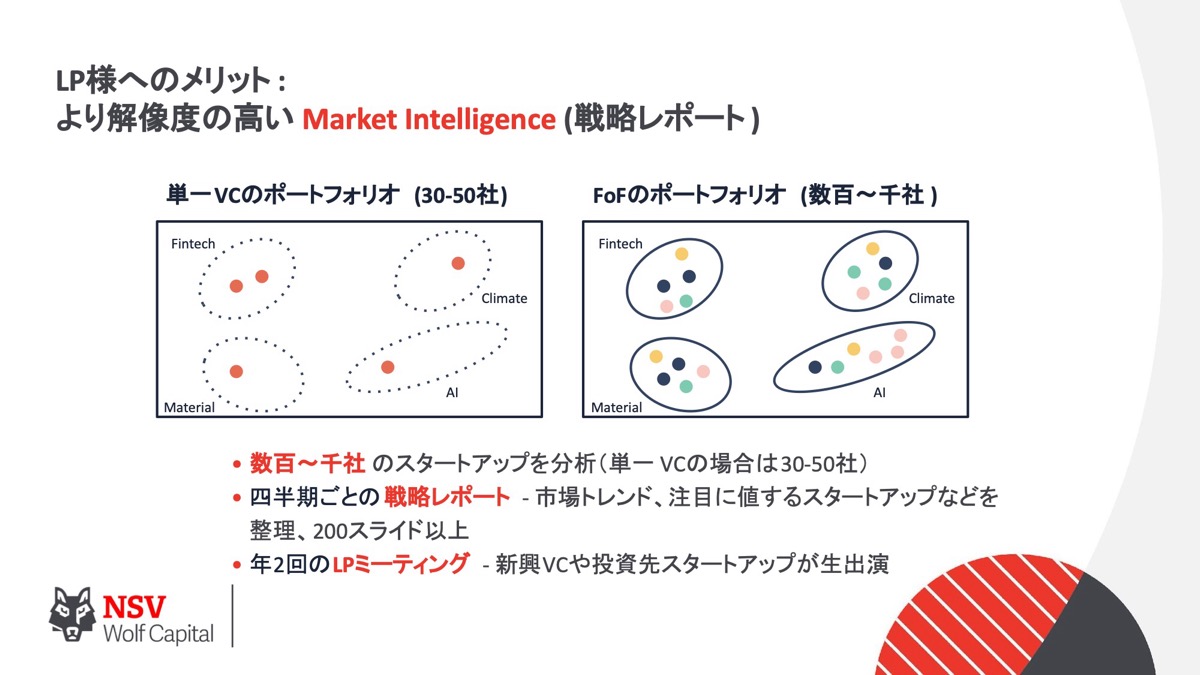
しかも、ある会社に投資をすると、その会社の競合会社に当然投資できません。
投資した会社を通じてマーケット情報が得られるのですが、僕らはたくさんのVCに投資をするので、それぞれの事業、ドメインごとにかなり解像度の高いデータが取れます。
最近はLeonis CapitalというVCに投資をしましたが、2人ゼネラル・パートナーがいて、もともと投資をしていたジェイ(・ジャオ)と、元OpenAIのジェニー(・シャオ)です。

この2人のような人たちがいると、インサイダー投資案件が大量に入ってくるわけですよ。
こういうキレがあるというか、何かに特化している、何か一芸に秀でているVCとたくさん付き合って、その人たちにいろいろ教えてもらいながら一緒に投資をしています。
尾原 特に生成AIは先ほど見ていただいたように、意外とAIそのものはたくさん出てきてコモディティ化しているので、先にこの事業のデータを握るかとか、こういうSaaSでモジュール化するかみたいなことで、意外とステルスでアメリカでは表に出なくなっているのですよね。
柴田 そうなんですよ。
NSV Wolf CapitalのAIポートフォリオ
柴田 ここにあるのが、我々の投資したVCが投資したスタートアップです。
間接ポートフォリオだと思ってください。

だいたいAI系で、今あるファンドから378社ぐらい投資をしていて、そのうち100ミリオン以上調達しているのが36社です。
社名の下の数字はバリュエーションではなく資金調達額なので、相当大きい会社にいろいろ入っていますので、モデル的にはすごくいいと思っています。
私は生成AIをかなりたくさん見ていまして、自分でエンジェル投資もしていたので、そちらは150社くらい見ていますし、先ほどのNSV Wolf Capitalの投資分では300社ぐらい見ています。
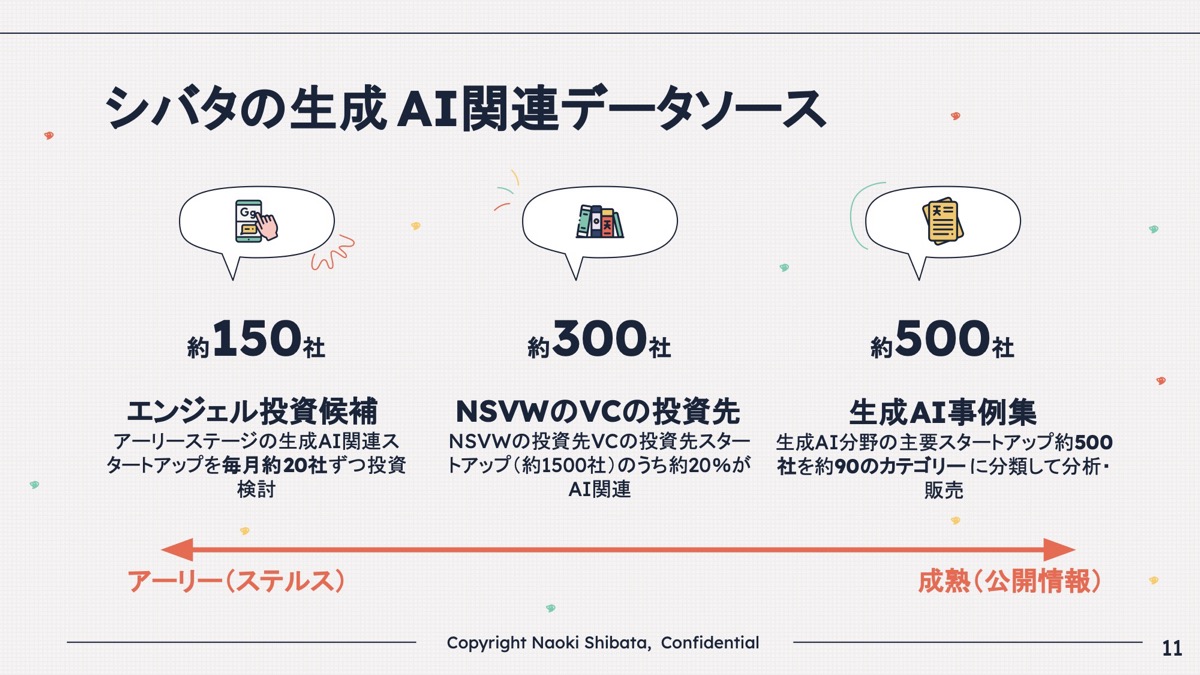
あとは日本の企業の方から非常に問い合わせが多かったので、生成AI事例集を作ってnoteで販売し始めました。合計すると1,000社ぐらいアーリーステージからレイターステージまで見ていることになります。
今は青木さんと山崎さんのように自分で事業をしているわけではないのですが、生成AIの事例だけはおそらくかなりたくさん見ているかなと思います。
レイヤーで分けると、5つのレイヤーになると思います。
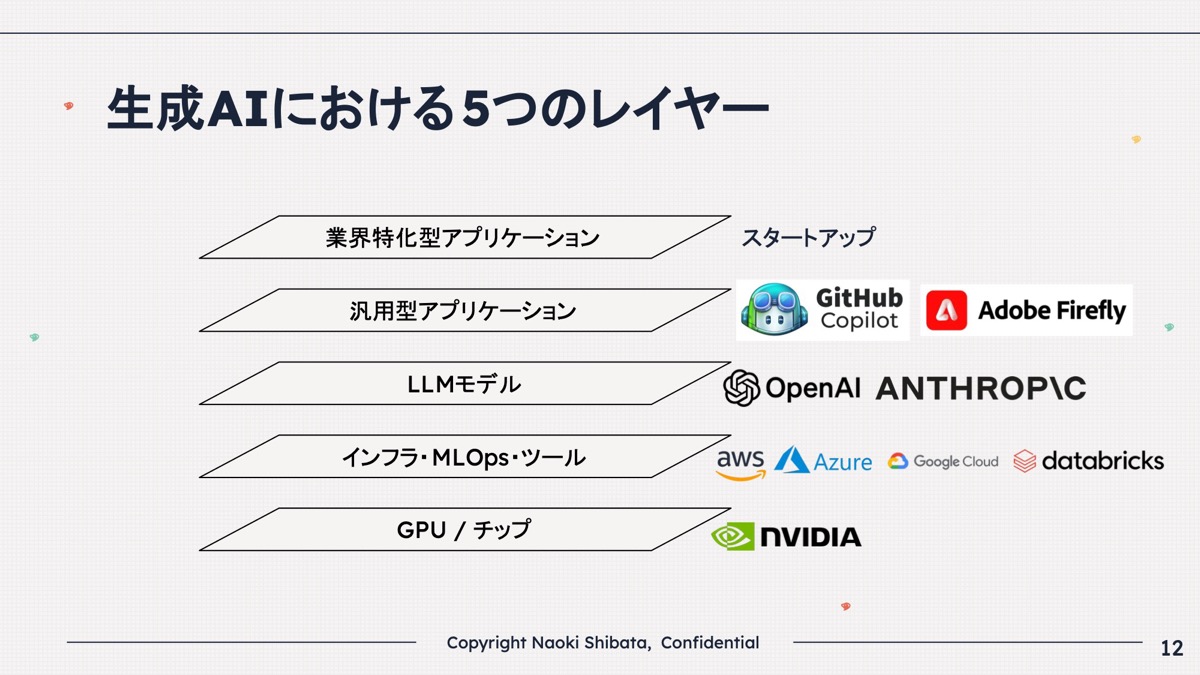
下からチップ、インフラ、LLMモデル、汎用型アプリケーション、業界特化型アプリケーションです。
今日はこの後、この会場でもう1つセッションがあって、事例の話はそこでしたいと思います。
(Session 12C グローバル市場の動向 – 世界はどう動いているのか? どんなサービスがホットなのか?)
日本企業がLLMアプリ、AIを導入する流れを解説
柴田 日本の企業の方がLLMのアプリを作ったりAIを業務に導入していったりするときに、どういう感じで進むのか、意外と非常に評判が良いので、その話をしたいと思います。

ちなみに皆さん、理系、文系の2つに仮に分けたとして、自分は文系だという方はいらっしゃいますか?
(会場を見渡して)文系の方が多いので、なるべくエンジニアでない方にもわかるように話をしたいと思います。
AI導入やLLMアプリを作る時、このような感じで進化しているなと思います。
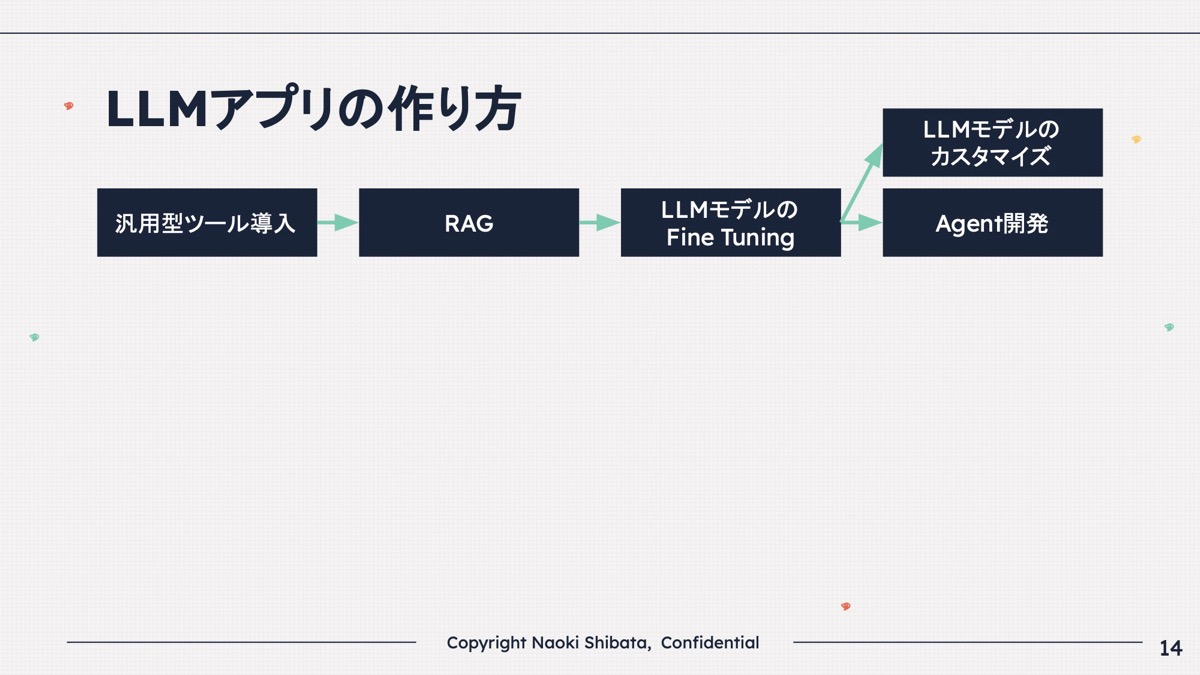
もちろんこれではないパターンもありますが、スタートアップも大企業も、だいたい皆さんこういう感じで進んでいくというのが、なんとなく見えてきました。
①汎用型ツール導入
柴田 まずは当然ですが、業務改善のために生成AIを導入しようとなります。
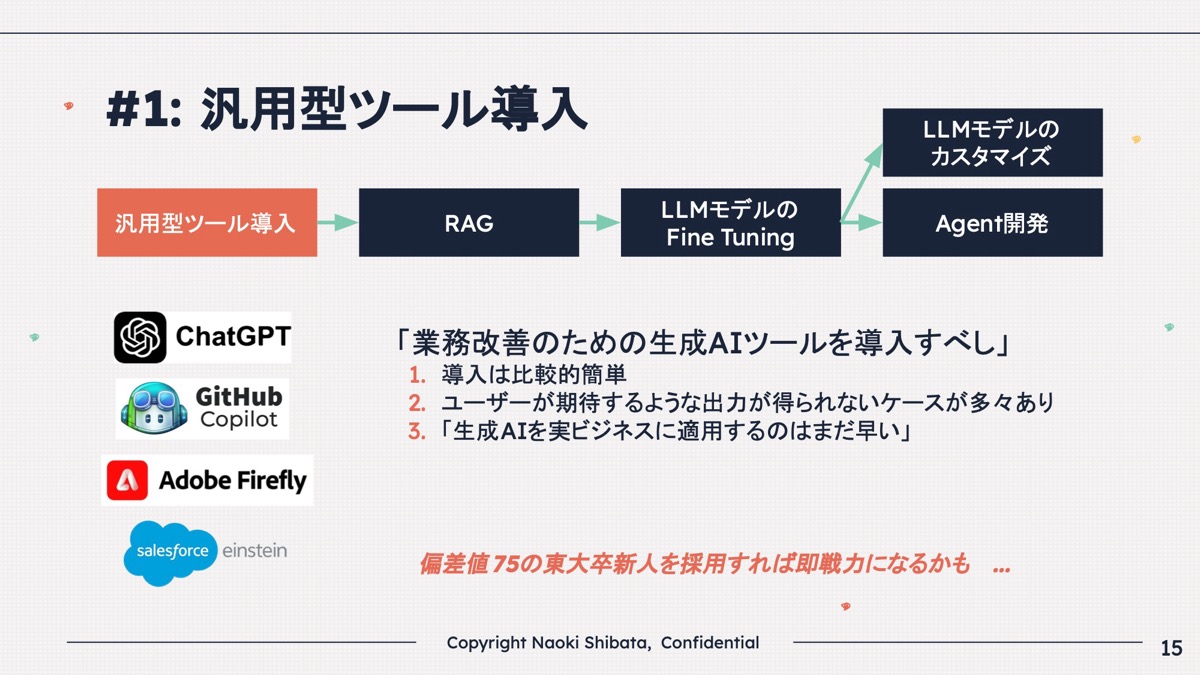
要は「ChatGPTを社内で使えるようにしましょう」みたいな話ですが、ChatGPTなどの汎用型ツールを導入すると、それっぽい質問をしたらそれっぽく回答してくれるじゃないですか。
でも実際に特定の業務のことを聞くと、もちろんわからないわけですよ。
ここで詰まったりする人も多いのですが、よく考えてほしいのは、偏差値75の東大卒の新人を採用したときに、「即戦力になるかも!」と思うのと同じく汎用型ツールを導入するのですが、東大卒の新人は即戦力にならないですよね?
②RAGを導入
柴田 次に何をやるかというと、じゃあRAGで頑張ろうという話をみんなするわけです。
▶RAG(野村総合研究所)
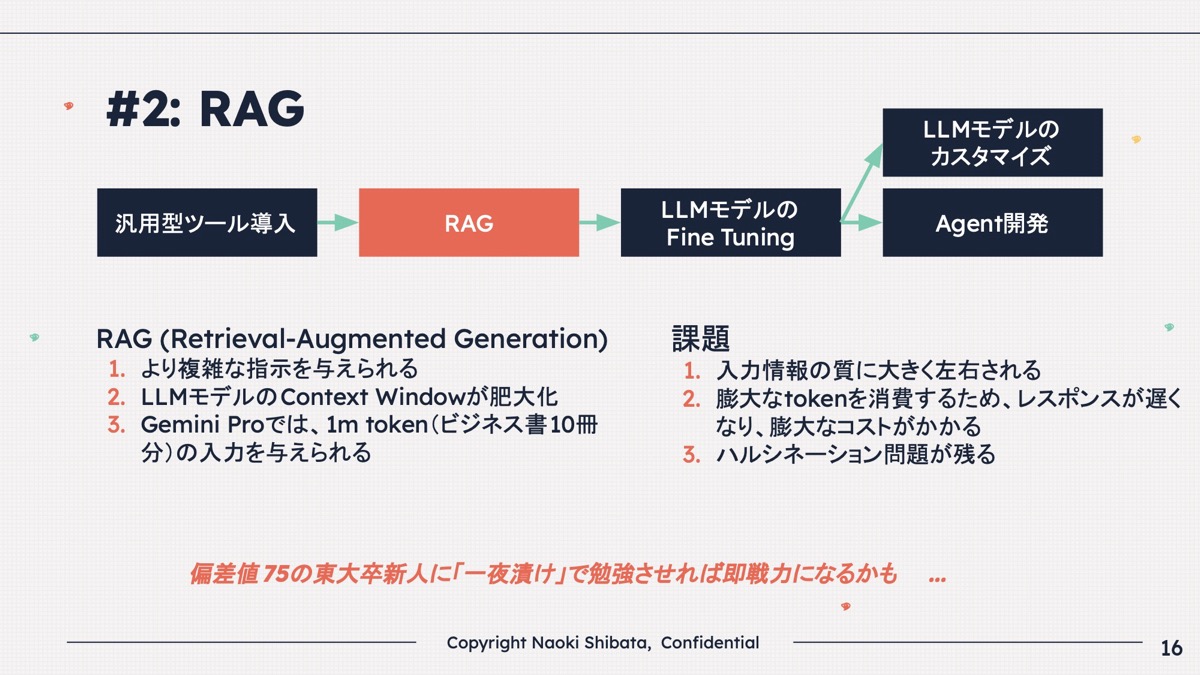
RAGはもちろん良いこともたくさんあって、より複雑な指示を与えられるし、コンテキストウィンドウもすごく長いので何でもできるのですが、これは例えると、偏差値75の東大卒の新人に一夜漬けで死ぬほど勉強させているのと同じです。
ここに本が10冊あるから、明日の朝までに全部読んでサマリーしなさいみたいなことをやるわけです。
偏差値75の東大卒の新人は頭が良いし、若いし元気なのでできるのです(笑)。
でも、ものすごく消耗しますし、上司の指示が少し悪かったりするとハルシネーションを起こしまくるし、人間は毎日徹夜できませんよね。
でも、RAGが悪いわけではないです。
RAGも良いことがあって、特にスタートアップではRAGを当然書いて、こういうふうに指示をしたらこういう結果が出てうまくいくという試行錯誤を最初みんなやるわけですよ。
でもこれは非常に消耗するし、とにかくつらいです。
③LLMモデルのFine Tuning
柴田 その次に何をするかというと、Fine Tuningです。
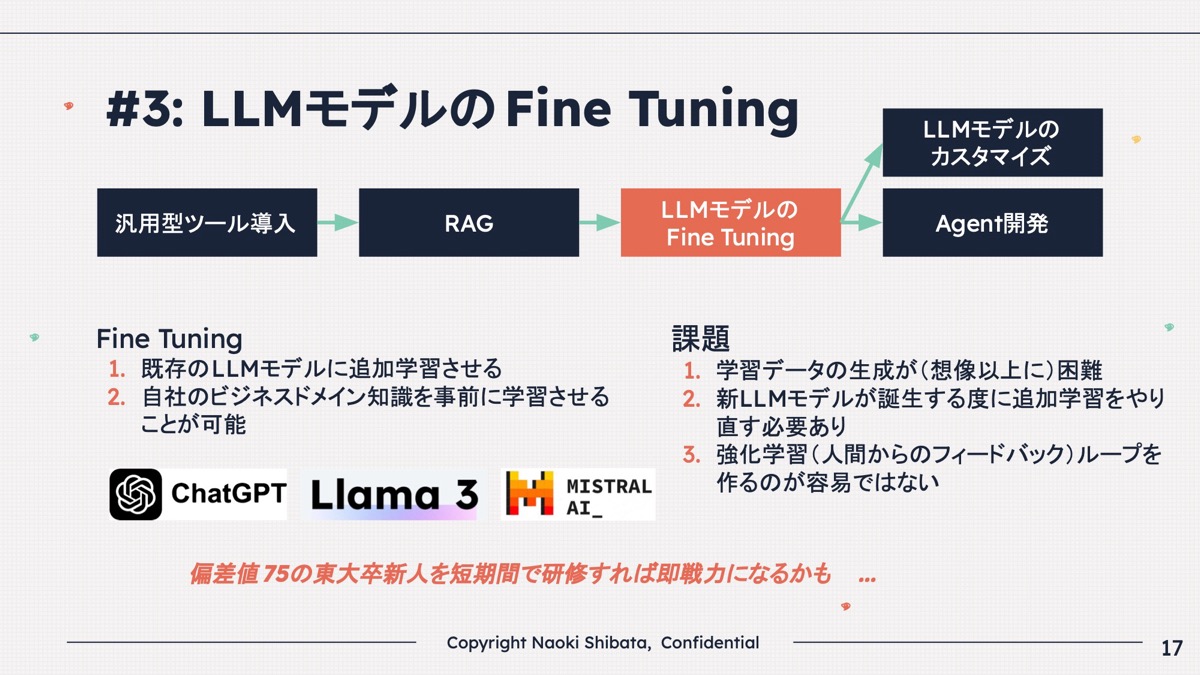
既存のLLMのモデルがあって、Llama(ラマ)のオープンソースもあればChatGPTもあれば、いろいろなモデルがあります。
それらはある程度の常識や知識を持っているわけです。
その上に皆さんの業務知識、特定の業界の特定の業務の知識を追加学習させるのです。
そうすると結構良くなる場合があります。
それをFine Tuningといいます。
これは、さすがに偏差値75の東大卒の新人に徹夜はかわいそうなので、研修ぐらいはしてあげようと、研修をすることと同じ話です。
たくさん研修すると当然業務のことがわかるのでうまくいく場合が多いですが、研修資料の作成(=学習データの生成)は非常に大変です。
僕もたまに研修の資料を作りますが、大変です。
研修資料の作成(=学習データの生成)は非常に困難だったり、あとはLLMのモデルが数カ月おきに新しくなるので、結構しんどいのです。
一番大事なのは、強化学習のループです。
新しい正解データがどんどん増えるような仕組みをちゃんと作るのは、結構難しいのです。
④a LLMモデルのカスタマイズ
柴田 Fine Tuningをしたけれど、もう少し頑張りたいという時に、LLMのモデルをカスタマイズしたり、LLMの小型のモデルを作ったりする方向に進む人もいますが、これはマシンラーニングのエンジニアが相当必要になったりするので、あまりお勧めはしません。

これは採用でいうと、一般教養が全くないし、コミュニケーションが苦手で、特定の分野の知識だけを持った人を採用しようみたいな話なのです。
別に悪いことでもなんでもないのですが、なかなか難しくて、意外と会社のカルチャーにフィットしないとか、いろいろな問題があります。
④b Agent開発
柴田 今、最先端のスタートアップは、Agentを作ろうとしています。
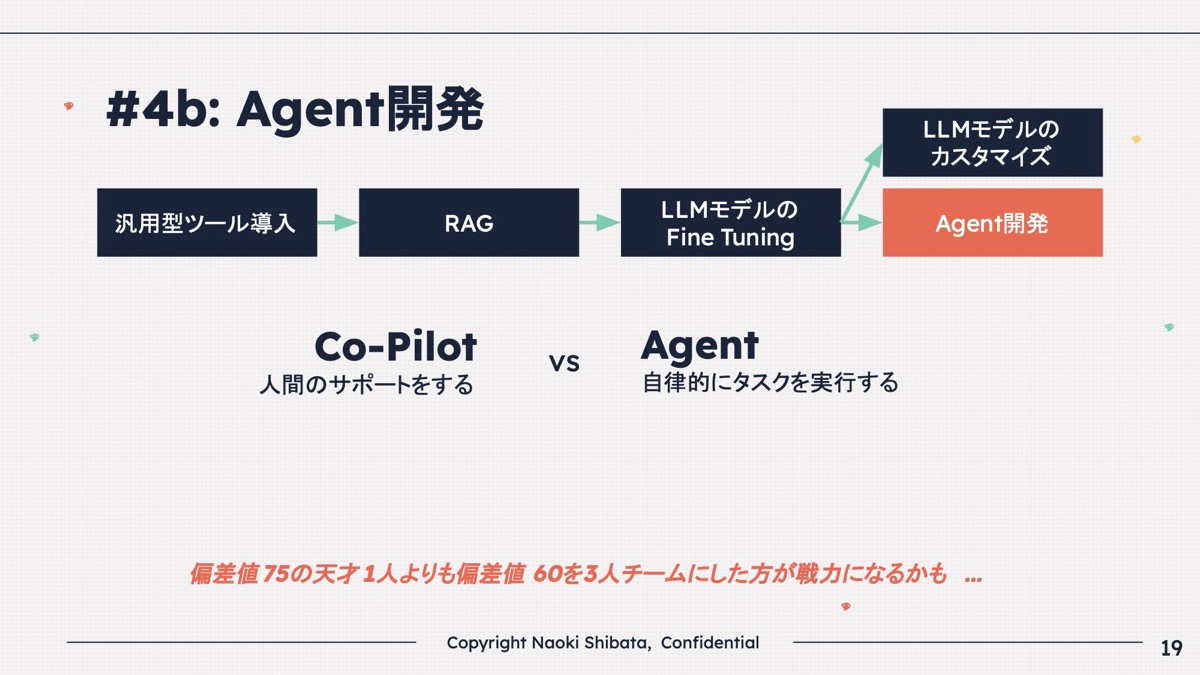
AgentとはCopilotとの対比で、皆、Agentと言っています。
Copilotは人間が何かするのをサポートするAIで、Agentはタスクを自分で実行することができます。
Agentを作る時にマルチエージェントにする場合が多くて、偏差値75の天才1人よりも偏差値60くらいの人を3人のチームにしたほうが戦力になるのではないかという話です。
尾原 三人寄れば文殊の知恵ですね。
柴田 おっしゃる通りです。
AI Agentの例①2つのLLMに違う役割
柴田 イメージとしては、例えば、コーディングのタスクがあって、タスクを実行するようなソースコードを書いてくださいという指示が来たとします。

左側にいるLLM君はコードを書くLLMで、「こういう関数ができました」と言います。
右側のLLM君はそれをレビューするLLMで、「5行目にバグがあるから修正して」と指示を出します。
左側のLLM君がそれを直して、「バージョン2ができました」と右側のLLM君に送ると、「ユニットテストの3番目が失敗しているから修正して」みたいな感じで、バージョン3ができてきます。
こうやって2人のLLMを違う役割で投入させることによって、より精度を上げることができます。
AI Agentの例②マネージャーがタスクを分解
柴田 もう一つの例は、少し複雑です。
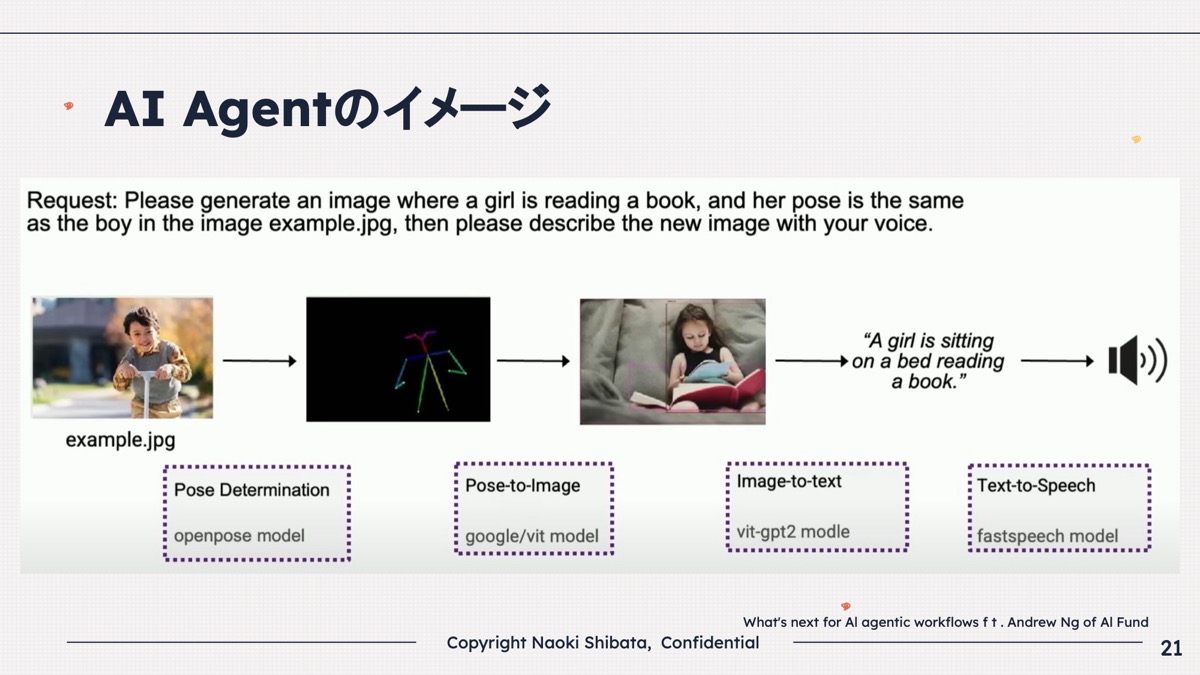
以下が、タスクです。
・Please generate an image(画像を生成してください)
・女の子が本を読んでいる画像です。
・その女の子のポーズは、左の写真にある男の子と同じポーズです。
・画像を生成した後に、音声でその画像を説明してください。
こういうタスクがあった時に、マネージャーエージェントがサブステップに業務を分解します。
一番目のLLMは左下にあるように、「Pose Determination」といって、左の写真からポーズを決めるLLMを使います。
次に「Pose-to-Image」、そのポーズから画像を生成します。
その次に、「Image-to-text」、画像を文字にします。
最後に「Text-to-Speech」、文字を音声にするというふうに、マネージャーが1人いてそれぞれのタスクに部下が4人いると想像して、4人いなくてもいいのですが、4つのタスクがあるとすると、こういうことは、皆さん、普段の業務でしていますよね。
こういうふうにAIを導入していくと、割とうまくいきそうだということがわかってきています。
(続)
本セッション記事一覧
- AIでEnd-to-endが主流になってきた自動運転技術
- 自動運転車のチューリングが挑む「何が起こるか」を予測できる生成AI
- エッジ生成AIのキラーアプリケーションは自動運転
- AIを作ることは「人間とは何か」という大きな問いを解決しようとすること
- リアルタイム音声認識「Poetics Speech API」が日本語では最高性能レベルの理由
- 人間は生まれながらにEnd-to-endでマルチモーダル
- 日本企業がLLMアプリ、AIを導入する流れを解説
- 自律的に物事を実行する「Autonomous AI Agent」とは
- 最先端のコールセンターを自律AIで構築する試み
- ソフトバンクの子会社「Gen-AX」が展望する企業向けエージェント、2026年までのロードマップ
- 2025年の生成AIはどうなる? 未来を信じて新たな産業を創ろう!【終】
編集チーム:小林 雅/原口 史帆/浅郷 浩子/戸田 秀成/小林 弘美