
ICC KYOTO 2024のセッション「AIの最新ソリューションや技術トレンドを徹底解説(シーズン7)」、全11回の②は、青木 俊介さんがチューリングによる2つの開発モデルを紹介。より人間に近い自動運転は、AIが人間の常識を身に付けることで強化されるといいます。AIに常識を教える、大規模マルチモーダル学習ライブラリ「Heron」と自動運転向け生成世界モデル「Terra」とは?ぜひご覧ください!
ICCサミットは「ともに学び、ともに産業を創る。」ための場です。そして参加者同士が朝から晩まで真剣に学び合い、交流します。次回ICCサミット FUKUOKA 2025は、2025年2月17日〜 2月20日 福岡市での開催を予定しております。参加登録は公式ページをご覧ください。
本セッションのオフィシャルサポーターは Notion です。
▼
【登壇者情報】
2024年9月2〜5日開催
ICC KYOTO 2024
Session 11C
AIの最新ソリューションや技術トレンドを徹底解説(シーズン7)
Supported by Notion
(スピーカー)
青木 俊介
チューリング株式会社
取締役 共同創業者
柴田 尚樹
NSV Wolf Capital
Partner
砂金 信一郎
Gen-AX株式会社
代表取締役社長 CEO
山崎 はずむ
株式会社Poetics
代表取締役
(リングサイド席)
上地 練
株式会社Solafune
代表取締役CEO
小田島 春樹
有限会社ゑびや / 株式会社EBILAB
代表取締役社長
柴戸 純也
株式会社リンクアンドモチベーション
執行役員
武藤 悠輔
株式会社 ALGO ARTIS
取締役 VPoE
(モデレーター)
尾原 和啓
IT批評家
▲
▶「AIの最新ソリューションや技術トレンドを徹底解説(シーズン7)」の配信済み記事一覧
チューリングの自動運転システム開発の歩み

青木 2022年から、自動運転システムの開発・検証をずっと行ってきました。

最初は私有地で1周200mをぐるっと回るような、AI一発で回るものを作りました。
2023年に、ついに公道に出まして、2025年の12月には東京都内を走れるような自動運転システムを作っていきたいと思っています。
▶目指すは「東京の市街地を30分以上自動運転で連続走行」!チューリングが挑む全社プロジェクトを徹底解説(チューリング)
具体的にやっていることはMLOps(※機械学習(ML)と運用(Operations)を組み合わせた造語)の基盤作りで、これはやはりデータが非常に大事です。
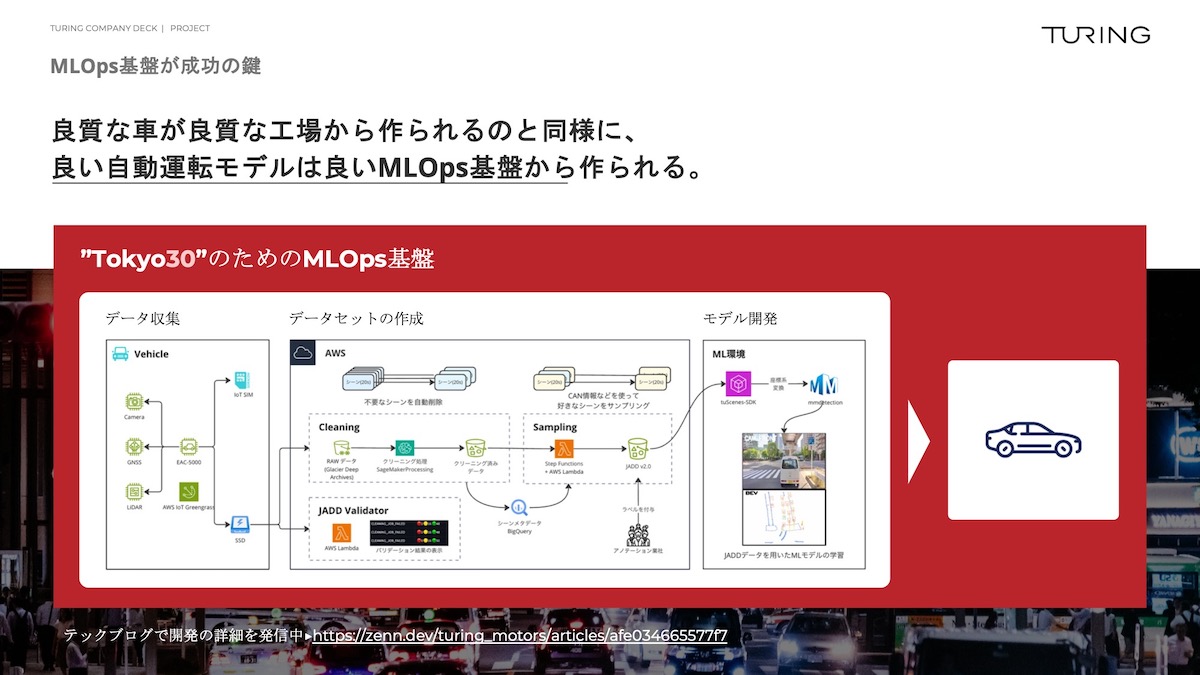
イギリスのウェイブは、つい先日、ソフトバンク、エヌビディア、マイクロソフトから大型の資金調達をしました。
ワークショップなどで我々も対峙したりしますが、どこの会社も言っているのはデータが非常に大事だということです。
テスラの車はもうデプロイ(運用)されているから、テスラの車からデータを取ってきているためすごいとよく言われるのですが、テスラの人に聞くと結構大変だそうです。
たとえば、一時停止サインを日本人も無視するかもしれませんが、アメリカ人もよく無視します。
無視するポイントが決まっていたり、歩行者を無視することがあったり、それがたくさんデータに入ってきているので、きちんとクレンジングできていないことに困っていると聞いたので、それならば勝ち筋はまだまだあるなと感じました。
実は我々もデプロイして、7台ほど東京都の街中を走らせています。
尾原 すべてAIで情報が取れていくときの逆作用というものがあります。
Googleマップも皆さんが使っているスマートフォンの動きに基づいて、AIで道路情報をアップデートしているのです。
一方通行なのによく逆走されている道があると、Googleマップはその方向でも通れると思ってしまい、最適化のルートにしてしまうみたいなことも起こります。
そういうところのチューニングはすごく大事ですよね。
青木 そうですね。
尾原 砂金さん、何かありますか?
自動運転の品質管理

砂金 車は命を預かるので、自動運転はQA(品質管理)が大変ですよね。
データのクレンジングの話がありましたが、事前学習のモデルを作るための学習データと、検証するためのデータの両方を集めなければいけないので、それぞれに難しさがありますよね。
青木 QAは非常に難しいですね。
多分AI系のこれだけ大きいもののQAをやったことがある人は、日本にほとんどいないのではないかと思います。
そういう人材の採用は、喫緊の課題だと思っています。
砂金 言語系とかだとクイズ王などはELIZA(イライザ)が作っていて、国内でもいくつかテストデータみたいなものがあって、それでパフォーマンスがどのぐらいか出せます。
自動運転にもそういうメジャーなものはありますか?
あるいは独自に作られているのですか?
青木 今のところないのですが、この後お話しする「世界モデル(World Models)」で、シミュレーションも実はできるのではないかと考えています。
▶デヴィッド・ハ、ユルゲン・シュミットフーバー「世界モデル」2018年3月27日
尾原 おっ、出た!
青木 シミュレーションの話も、後ほどそこでしたいと思います。
尾原 やった! 「世界モデル」というのが、次のバズワードの一つです。
生成AIで「より人間に近い運転」を強化
青木 次にお話しするのが、我々のE2E(End-to-end)自動運転モデルの構成です。
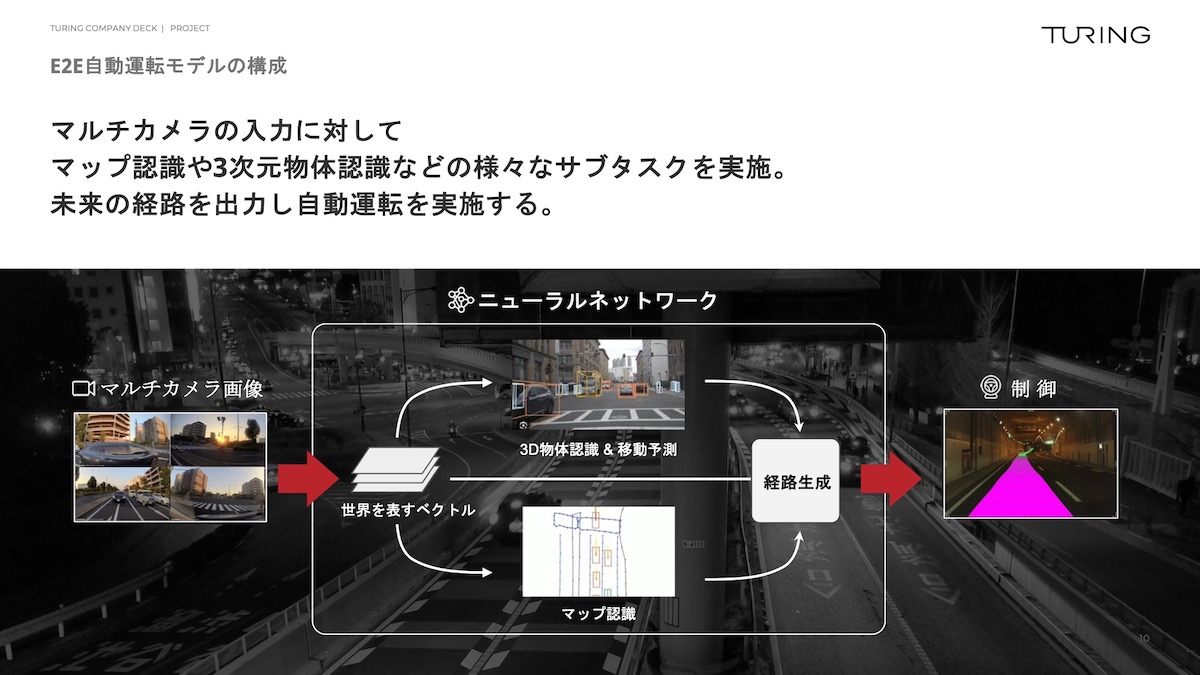
まず、マルチカメラで画像を撮ってきます。
そして、サブタスクをいろいろ考えてはいるのですが、基本的には1つの大きなニューラルネットワークに入れます。
右側にピンク色の線が出ていますが、道をどう走ればよいかみたいなところまで指示を出しています。
ここまでやると走れそうじゃないですか。
いや、一般の方には走れるかどうかは、わからないですよね。
文書を書けました、絵を描くことができました、画像も生成できます、ゲームも人間より格段に上手です。
運転行動は基本的にはアクセルとブレーキとハンドルをどれだけ動かすかという3つの出力しかないのだから、これだけ考えてあげるとできそうなのです。
でもまだちょっと難しいかなと思っているところに対して、生成AIを自分たちで開発して、最後(完全自動運転)までもっていこうと、今取り組んでいます。
左側に「運転能力」とありますが、実際に撮ってきたデータで、なんとなく自動運転できるものを作っています。
そして、右側の「VLM(Vision Language Model)」と「世界モデル」という2つのモデルを作っています。

世界との技術開発競争
青木 AIは目が非常に良いし耳が良くて、言語か画像のどちらかを入れることはできますが、我々は言語と画像の両方を入れて考えさせています。
これが、Vision Language Modelモデルで、我々はマルチモーダル生成AIライブラリの「Heron」を作っています。

▶自動運転EV開発のチューリング、日英言語対応のマルチモーダル学習ライブラリ「Heron」と最大700億パラメータの大規模モデル群を公開(PR TIMES)
これはR&Dあるあるなのですが、他社も動きが早く、開発してもすぐ出てきます。
Heronを出した時はすごく早かったと思いますし、業界的にも多分注目を浴びました。
尾原 そうですね。
青木 良かったなと思ったのですが、これを出したすぐ後にGPTがアップデートして同じようなことをやってきて、この巨人とちゃんと戦っていくのは大変だと思っていました。
人が適切に運転できるのは培ってきた常識があるから

尾原 皆さん、今度車に乗った時に、運転席から1枚写真を撮って、「僕は今車を運転しています。この状況だったらどうドライブしますか」というプロンプトを入れてみてください。
ChatGPTは、僕が運転手だったらこっちの人に気をつけて、右にちょっと曲がりますみたいなことを言ってくれます。
いまやAIの中に汎用知識があるから、画像を入れると人間が運転の判断をどうするべきかみたいなことを表示できてしまいます。
そういうことに、GPTがあっという間に追いついてきましたよね。
青木 本当にあっという間でした。
「汎用知識」という単語が出てきましたが、我々人間は教習所に2,000時間通うわけではないですよね。
今まで2,000時間なり5,000時間なり走れば自動運転で走れると思ってやってきたのですが、実は我々は18年間生きてきて、いろいろな常識を獲得しているのです。
道端でこういうことが起きるとか、この人は転びやすそうとか、ここで絶対飛び出してくるとか、この動物がここにいるのは珍しいとか、いろいろ考えたりします。
常識を獲得した上で教習所で30時間ぐらい運転ルールをふりかけみたいにちょっと学んでみると、運転できるようになるのです。
この常識を獲得することが非常に大事であるということに、ほとんどの人がGPTが出てくるまで気づけていませんでした。
そこに気づけたので、自動運転領域の論文は今大きく変化していて、どれだけ学習したか、どれだけ走ったら何パーセントだという内容から、今は生成AIが何を見ているかという内容になりました。
まさしく尾原さんがおっしゃってくださったように、「自動車を運転している時に何を考えればいいですか? どこに気をつければいいですか?」とプロンプトすると、我々が思っているぐらいのことをちゃんと答えてくれるのです。
「交通誘導員を見てください」「信号機を見てください」「工事の標識があります」「映っていないけれど奥に車があるかもしれないから気をつけてください」など、結構いろいろなことを見てくれて、言ってくれるのです。
これだけのIQというか頭の良さがないと運転はできないと思います。
冷静に考えてみると、5歳児や鳥やタコが運転できるかというと、5歳児はペダルを踏むことはできるかもしれませんが、高度な決断はできません。
リアルな運転シーンを動画で出力する世界モデル「Terra」

青木 いよいよ「世界モデル」の話をしようと思います。
我々も世界モデルの「Terra」 を作っていますが、作っている側からしても使えるかどうかわかりません。
▶チューリング、日本初の自動運転向け生成世界モデル「Terra」を開発(PR TIMES)
わかりやすくいうと、これらの動画はAIが生成しています。

左側を見てもらうとわかりますが、結構東京っぽいですよね。
我々が走行して撮影したデータを、世界モデルから出力すると、こういう動画が出てきます。
OpenAIのSoraをご存知の方がいらっしゃるかもしれませんが、我々はSoraの自動運転版を作っています。
なんか新宿っぽいなとか、静岡のあの辺ぽいなと感じるのですが、現実世界とは解離が起きていて、「ここにこんな道はないのに」という動画をAIが生成しています。
右側を見てもらうとわかるのですが、薄く緑の線と赤い線がついていて、「アクショントークン」というものを入れます。
緑の線は「直進しますよ」というアクショントークンで、真っ直ぐ進みます。
右側の赤い側にアクショントークンを入れると、ここは右折してよい環境下ではないので、右折すると事故が起こってしまいますよと、AIの中でAIをシミュレーションするようなことができるようになってきています。
データに残らない事故のシミュレーションもAIで
青木 シミュレーションが出てくると、AIは進展がすごく早く、今のQAの話に少し紐づいてきますが、もしかしたらものすごいテスト環境になる可能性があるという話が一つと、もしかしたら世界モデルですら、自動運転側のニューラルネットワークに包含されるかもしれないという話があります。
今まで、1つタスクをやっていたら、それが全部包含されてしまうことはよくありました。
文書でいうと、翻訳のDeepLを多くの方が使っていたと思いますが、今ではDeepLよりGPT-4のほうがずっと賢いです。
翻訳をしていた人からすると、「翻訳も全部含まれてしまうのですか?」と驚くかもしれません。
でも、その不可逆な動きは抵抗してもどうにもなりません。
そう考えると、この世界モデルですらもしかしたら、自動運転のAIに包含できるかなと思っています。

尾原 そうですね。
これはなぜかというと、DeepLは翻訳という知識を頑張って仕組み化したのですが、生成AIのChatGPTのLLMがすごいのは、大量のテキストデータでトレーニングしていたら、何も教えていないのに英語の文法がわかるし、米国の司法試験をトップ10%で受かってしまうしというふうに、勝手に構造を理解してしまうのです。
テキストの世界が世界モデルになると、遠近法やライトが反射してどこまで光が届くかという物理法則を一切教えていないのに、再現ができてしまうわけです。
そうするとさっき言ったように、特化型で作っていたDeepLよりChatGPTのほうが全体的な整合性を取ってくれるから便利だよねみたいな話になっています。
これを日本でちゃんとやらなければいけないのにやれていないところをやってくださっているのが、チューリングです。
青木 そうなんです、やってみて世界モデルを作れたのですよ。
でも、作ったメンバーも、「まあ、なんか作れたな」ぐらいな感じで、「これは実は秘伝のタレで…」みたいなものがあるわけではないので、そこが今のAI開発の難しいところだなと思っています。
世界モデルの話はAIが大好きな人からしたら面白いと思うのですが、投資だけ見ている人からは、「本当に包含されると言っているけれど、整合性はありますか?」みたいに言われます。
「いやいや何もないですよ。過去を見て傾きを考えていけると思っています」ぐらいのことなので、結構クレイジーなことをやっていると思います。
砂金 動画の右下は事故を再現しているのですか? 当たりそうな感じになっていますが。
青木 そうです。
砂金 正常系のデータは測定して得られますが、こうやった時に事故が起こるとか、人が飛び出してくるみたいなことは、学習にも検証にも使うデータはあまりないので、シミュレーション上で生み出せるのだったらすごく良いですよね。
青木 まさしくその通りで、事故の情報は出てこないのですよね。
あと、エッジケースは人間が避けようとするので出てこないし、データに残っていません。
自動運転のシミュレーターだけ作っている会社はたくさんありましたが、やはり人間の恣意性というか、これは絶対起こらない状況でしょうとなんとなく思ってしまうところがあるので、AI側にそこのフィールドを任せてあげるのは、一つの手段として面白いなと思ってやっています。
行動に伴う未来の予測が自動運転車には必要

砂金 シミュレーションにGPUを無限に使っている感じですか?
▶グラフィック・プロセッシング・ユニット(GPU)とは(IBM)
青木 GPUはめちゃくちゃ使っていて、恐ろしいほど使っています。
砂金 コスパを考えていたらできないってことですよね?
青木 そうですね。うちの会社は良くも悪くも売上を考えずに走っているディープテック・スタートアップです。
ここのコストを削ろうよと言われたら、「コストを削って何か意味があるっけ?」みたいな。
コストを削ってみんなの給料が上がるとか、売上や利益が上がるのだったら考えますが、うちはそういうことをやってもしょうがない会社なので、作って成功するか作らずに死ぬかという二択の選択肢を迫られると、やるしかないなと思います。
砂金 産総研(産業総合研究所)のABCIとか、全投入したらいいですよね。
▶ABCIとは(産業総合研究所)
青木 そうなんです。もっと使わせてほしいなと思っています。
ちなみに世界モデルがなぜ包含されるかという話だと、赤ちゃんや子どもって意味不明なことをするじゃないですか。
ここで急にスマートフォンを尾原さんに投げるとか、口に入れちゃうとか、食べようとしたりとか。
尾原 やりますね。
青木 でも私が今尾原さんに投げたとしたらめちゃくちゃ怒られるし、誰かがケガするかもしれないとわかっているのですよ。
何かをやった時に、未来に何が発生するかをなんとなくみんなわかっているのですよね。
それが自動運転車には必要で、アクショントークンを出す前の上側の画像を見てもらうとわかるのですが、この時直進したらこうなる、この時右折したらこうなるというなんとなく妄想をした後に運転するのは正しいのではないかと思って、今作っています。
(続)
本セッション記事一覧
- AIでEnd-to-endが主流になってきた自動運転技術
- 自動運転車のチューリングが挑む「何が起こるか」を予測できる生成AI
- エッジ生成AIのキラーアプリケーションは自動運転
- AIを作ることは「人間とは何か」という大きな問いを解決しようとすること
- リアルタイム音声認識「Poetics Speech API」が日本語では最高性能レベルの理由
- 人間は生まれながらにEnd-to-endでマルチモーダル
- 日本企業がLLMアプリ、AIを導入する流れを解説
- 自律的に物事を実行する「Autonomous AI Agent」とは
- 最先端のコールセンターを自律AIで構築する試み
- ソフトバンクの子会社「Gen-AX」が展望する企業向けエージェント、2026年までのロードマップ
- 2025年の生成AIはどうなる? 未来を信じて新たな産業を創ろう!【終】
編集チーム:小林 雅/原口 史帆/浅郷 浩子/戸田 秀成/小林 弘美