
ICC KYOTO 2024のセッション「AIの最新ソリューションや技術トレンドを徹底解説(シーズン7)」、全11回の➉は、引き続きGen-AX 砂金 信一郎さんによるソフトバンクのコールセンター自動化の話題です。与えられたミッション「自律思考型エージェントを作り上げ、他の企業でも適用可能であることを証明せよ」に懸命に取り組む過程を、RAGの技術も交え解説します。ぜひご覧ください!
ICCサミットは「ともに学び、ともに産業を創る。」ための場です。そして参加者同士が朝から晩まで真剣に学び合い、交流します。次回ICCサミット FUKUOKA 2025は、2025年2月17日〜 2月20日 福岡市での開催を予定しております。参加登録は公式ページをご覧ください。
本セッションのオフィシャルサポーターは Notion です。
▼
【登壇者情報】
2024年9月2〜5日開催
ICC KYOTO 2024
Session 11C
AIの最新ソリューションや技術トレンドを徹底解説(シーズン7)
Supported by Notion
(スピーカー)
青木 俊介
チューリング株式会社
取締役 共同創業者
柴田 尚樹
NSV Wolf Capital
Partner
砂金 信一郎
Gen-AX株式会社
代表取締役社長 CEO
山崎 はずむ
株式会社Poetics
代表取締役
(リングサイド席)
上地 練
株式会社Solafune
代表取締役CEO
小田島 春樹
有限会社ゑびや / 株式会社EBILAB
代表取締役社長
柴戸 純也
株式会社リンクアンドモチベーション
執行役員
武藤 悠輔
株式会社 ALGO ARTIS
取締役 VPoE
(モデレーター)
尾原 和啓
IT批評家
▲
▶「AIの最新ソリューションや技術トレンドを徹底解説(シーズン7)」の配信済み記事一覧
自律思考型応用へのチャレンジ
砂金 先ほど柴田さんのお話にあった自律思考型のトライアル(Part.8参照)を、カスタマーサポート文脈でやろうと努力していますが、すごく難しいです。
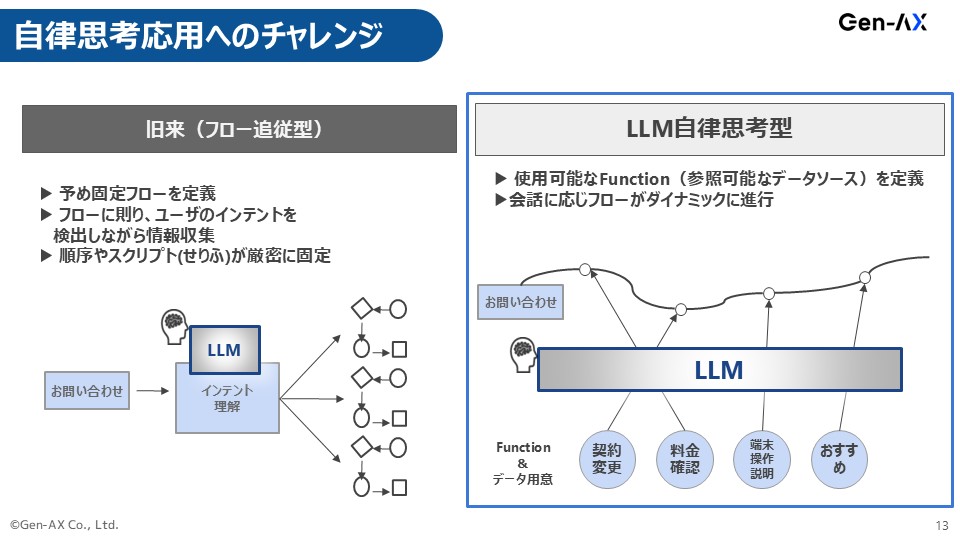
左側は先ほどのLINE WORKS AiCallみたいなもので、事前に設計をしてその通りに会話するので事故はなく、思った通りにしてくれます。
右側は、何を言うかはわからないです。
青木さんのチューリングのお話の中でも言いましたが(Part.2参照)、テストがすごく難しくて、毎回テストの再現性がないのです。
前回テストした時は普通だったのが、同じテストシナリオなのに突然変なことを言い出したり、何も変えていないみたいなことを、どこまでクリアしたら受け入れテストOKで本番化していいかというのが非常にセンシティブです。
それをどうしたらコントロールできるのか、ガードレールをどこにつけたらいいのか、手探りの状態で今取り組んでいます。
これはトップダウンの目標設定がないとなかなか難しいところで、普通だったら右の自律思考型でやろうとして、やっぱりまだ早いから左に戻そうというブレが発生します。しかし、左に逃げられません。
とは言え、先ほどの小さいAgentをたくさん作って群戦略ですみたいな話は、アプローチとしては同じです。
コミュニケーションだけ非常にうまい人とか、解約手続きのことだけあらゆる選択肢を全部持っている人とか、iPhoneの使い方に詳しい、アンドロイドの使い方に詳しいみたいな、そういうAgentをいくつか作って、その裏にプラグインとしてロジックが組めるようにはしています。
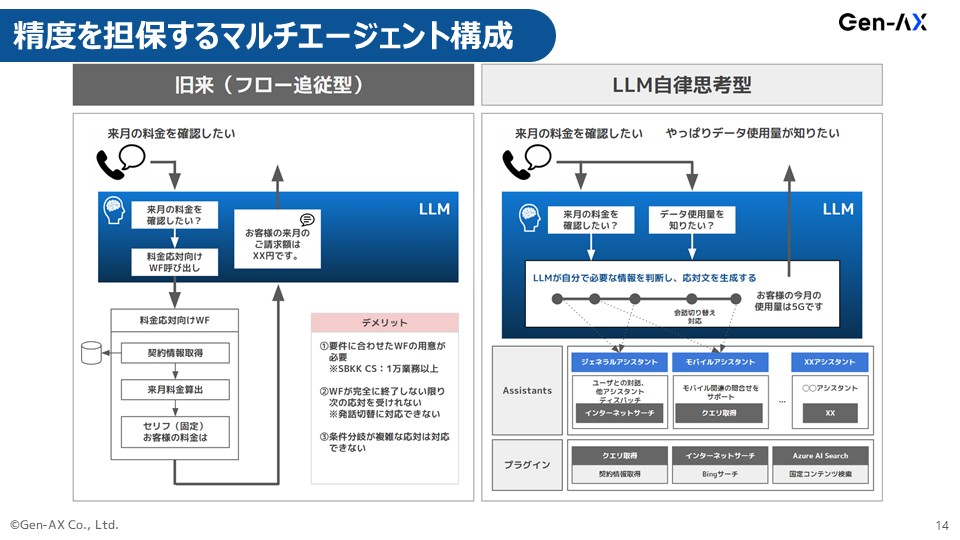
LLMを素直に使うと、Function callingかRAGになるのですが、そこにロジックを組んでアプリケーション処理は決まった定型をします。
ただ大事なことは、何をしたらいいかというタスク分解はLLM自体に任せることです。
それですごく苦労していますが、ここは突破したいなと頑張っている感じです。
これを社内でもちろんやるけれども、Gen-AXでわざわざやっているのは、外販というか外部の企業に、「ソフトバンクはこれでうまくやれましたので、皆さんもどうですか?」というのを事業の展開としてやろうとしているからです。
RAGにおけるチューニングポイント
砂金 この裏側にある作業のRAGの話について、少しだけ我々のアプローチを深掘りすると、RAGを頑張りますみたいな会社はたくさんあります。
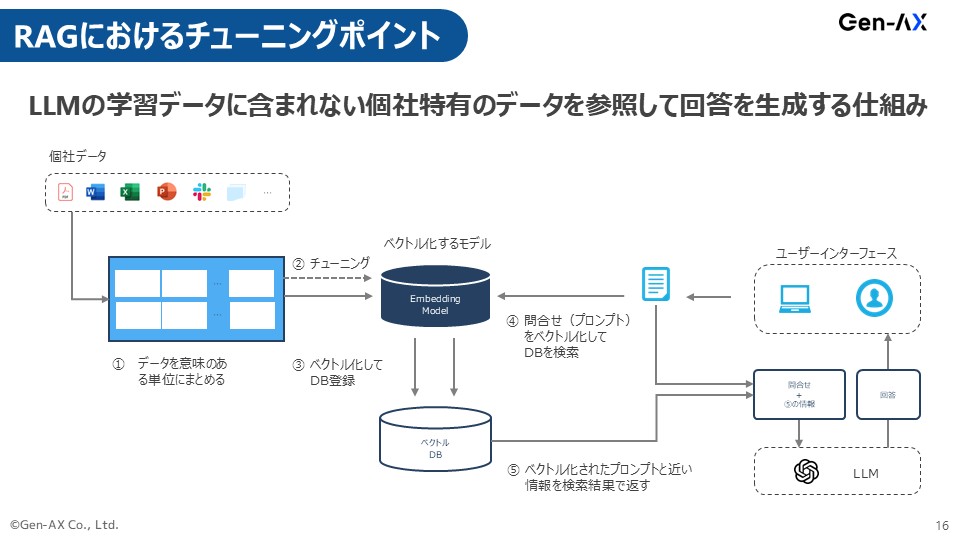
多分チューニングというか、今のGPT-4oベースもしくはGPT-5になったら違うかもしれませんが、だいたい効きそうなところでいうと、最初のデータのチャンキングの部分です。
尾原 チャンキングは「まとめ方」ですね。
砂金 画像化されたPDFを入れて、それで精度が出ないですというのは、それは当たり前ですよね。
AIの気持ちに立って、文書を作っていないのですから。
それを理解するのが難しいから、まずデータのチャンキングのところは多少人手を介してでも前処理はちゃんとやらないとだめなのです。
我々はEmbedding(埋め込み)モデルは、自分たちで頑張って作っています。
Tokenizerをどうするかは、少し微妙なのですが。
Embeddingモデル自体は、日本語や自然言語をベクトルデータでAIが理解できる数値に変換するという処理をします。
この部分がインターネットクロールでできている、先ほどの偏差値75の東大卒の新人の一般常識でベクトル化するのと、特定業務の細かい意味の違いを理解しているという部分をちゃんと埋め込んだ状態、そこだけFine TuningしたEmbeddingモデルにやらせるのとでは、全然違ってくるのですよね。
本当は我々のグループにはSB Intuitionsもいるので、フルスケールでFine Tuningしたいし、独自のLLMを作りたいのにコスパが合わないのですね。
計算量とか全然合わないので、Embeddingモデルだけは自分たちで作り、ベクトルデータベースを作っておいて、そこに問い合わせを、これもちゃんとEmbeddingモデルを介して適切に処理されたもので突合すると、それっぽいものを出してきます。
もちろんGraphRAGをハイブリッドで使うとか、そういったこともチャレンジしていますが、Embeddingモデルをチューニングするのが、今のところ効いているかなという感じですかね。

尾原 これは、どのくらいのデータサイズだと有効なモデルを作れますか?
砂金 そんなに要らないです。
要は、社内の専門用語集みたいなものがあると思うし、問い合わせ履歴に専門用語や固有名詞が入っていたりします。
固有名詞だから絶対に分割してはいけないし、こういうメニューですと、ちゃんと教える必要があります。
それはきっと社内の業務マニュアルに入っていると思います。
尾原 確かに、業務マニュアルの中に普通は誤解しやすいことは、こう誤解しないでくださいねという記載があるから、それをちゃんと入れると、ベクトルが違って出るから、一般知識だとまとまってしまうところが判別できるということですね。
砂金 それを基盤モデルに事前学習でやらせようとしたり、追加学習をFine Tuningでしようとしたりするとすごい沼ですけれども、Embeddingモデルと、あと我々が調整しているのは最後の検索結果のところのRerankerです。
Googleの検索も、多分最後にいろいろな大人の事情によってリンクの出される優先順位が変わると思います。
これをちゃんと正しい順番で出していきます。
RAGで使う時の検索エンジンの作り方はすごく肝のところで、私の場合はLINEですが、ヤフージャパン側に昔の検索エンジンの古の技術を持っている人が少しだけいます。
その人たちがどういうことに気を使って、検索結果をどう表示するかということのノウハウの部分で、Rerankerも少し調整しています。
尾原 先ほどの4番(解約防止)、5番(クレーム対応)は結構肝で、LLMやGPTは実は言語でやりとりしているようで、裏側はベクトルでやりとりをしています。
砂金 そうです。
尾原 だから要は人間に介するところは一般言語でやるのですが、直接やりとりする、4番、5番は要はもうAI同士の会話としてベクトルでやってしまうということですよね?
砂金 そうです。
4番のところとかも本当はもっとちゃんと工夫しなければいけないのですが、人間がこうしたいという自分の思いと言語化されたものがずれていることもあるので、そこを補完してあげることは多分必要なことですね。
山崎 人間においても、多分Word Embedding(単語の埋め込み)は人によって違う気がしていて、まさにそれは自然言語で話していないだけだけれども、あるコンテクストにおけるものというのは、Embeddingで解消していくという方向は……
尾原 これは本当にオープンに出してしまっていいの? (1つ前のスライドを指しながら)これは結構秘伝のタレなんじゃないですか?
砂金 どうやってチューニングするかは、秘伝のタレです。
尾原 確かに。
RAG改善をLLM Opsで実現
砂金 こういうことをやっているよという話をしてきました。
今私が話したのはRAGで性能が出ないですといったときに、あとこういう情報を追加すれば性能が向上しそうというのを、裏側でLLM Ops(大規模言語モデル運用)的に解ける仕組みは作っているので、Googleサジェストみたいな感じですね。
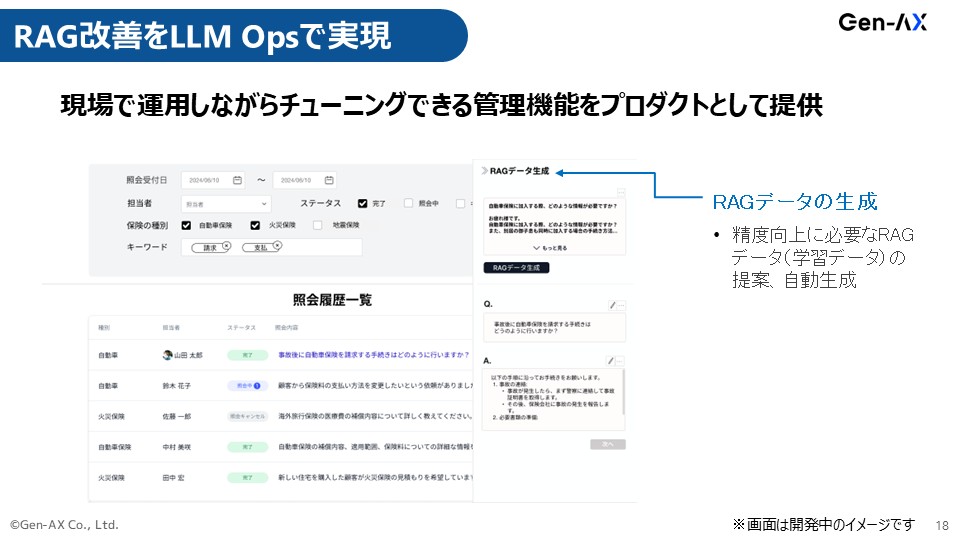
この検索キーワードだと欲しい答えが出てこないけれど、もう1つキーワードを追加したら欲しい答えが出てきそうだというのを、こういうRAGデータが今足りていないんじゃないですかとお知らせするようなものまで、裏側の機能を作っています。
ですから、ChatGPTを社内で導入しましょうみたいなことでAI活用しているということと、業務の中でちゃんと業務知識を持ったAIのモデルを埋め込んでいくことは、努力の幅としてギャップがあることはご理解いただきたいなと思っています。
それをプロダクト化していくのが、ソフトバンクのグループの中での我々の役割です。

そんなにきれいごとではないので、プロダクト提供だけではなくコンサルティングもセットにして、任務として負っています。

コンサルティングアプローチ
砂金 左と真ん中は普通のことを言っているのですが、右は「RAG Readable」と我々は呼ぶようにしています。
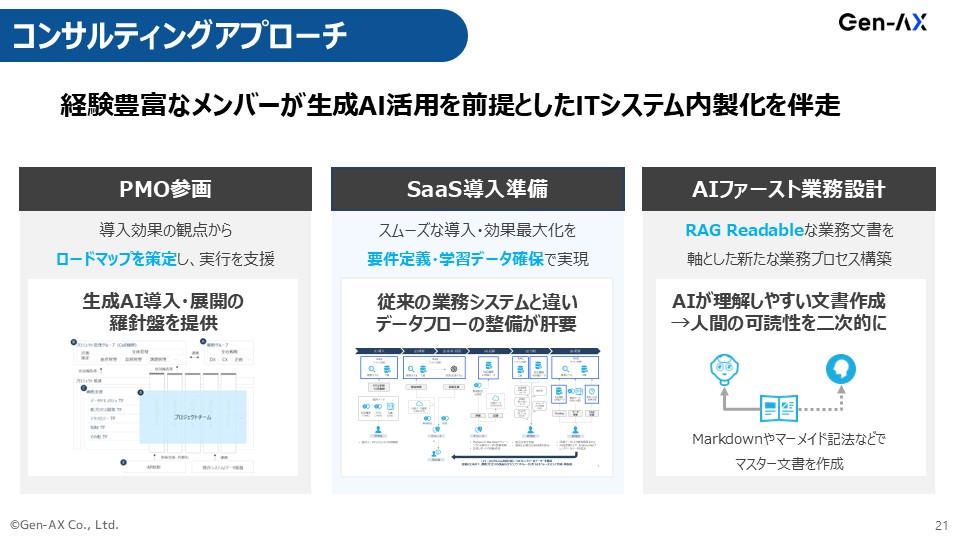
RAGが誤解せずに認識できるような文書をちゃんと作るコンテンツマネジメントやワークフローの仕組みを、業務ごと変えましょうと提唱しています。
ほとんどの業務マニュアルは、人間が読みやすいことに最適化して書き手が書いているのです。
だけれども、人間はいったん置いておいて、AIが正しく読めるようなMarkdown文書をきちんと書いて、それを人間も読めるような状態に変換するツールをセットで提供します。
AIを最終的に自動化、自律化させたいのだったら、AIに知識を埋め込むこと自体が業務運用主管部門の役割ですよねと、意識を変え、業務を変えることが我々がやろうとしているコンサルティングです。
企業向けエージェント、2026年までにここまで作る
砂金 最後にロードマップですが、我々が2026年ぐらいまでの短期にやりたいと思っているのは、企業エージェントをちゃんと作り上げようということです。
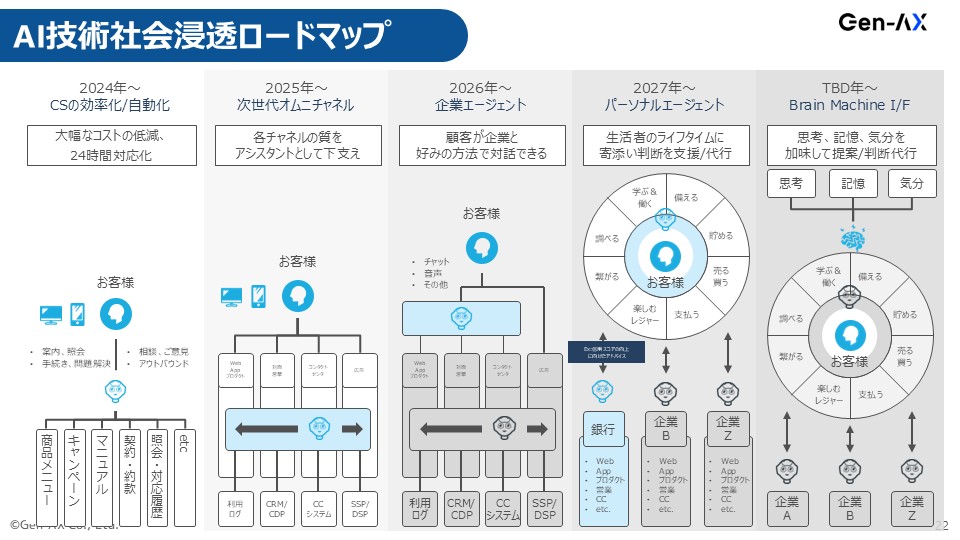
偏差値75の東大卒の新人君ではなくて、ちゃんとFine TuningによるものなのかRAGによるものなのかという手法の違いはあれど、企業の中でやっていること、商品の知識、お客様対応方法をすべて理解しているものを作っていると、きっとそのうちパーソナルエージェント的なものやBMI(ブレイン・マシン・インターフェース)みたいなものが世の中に出てきます。
その時に企業の皆さんがあたふたしなくていいように、もう準備ができていて、エージェントができています、データもあります、現状のデータだけではなくて、今後データをためていくためのデータパイプラインも整理できていますという状態を、ご支援したいというのが我々の位置付けです。
尾原 ヤバいですね! ありがとうございます。
(会場拍手)
これは柴田さんの話と本当につながっていますが、どうですか、柴田さんから見て。
柴田 もう本当に見本のように着実にやるべきこと、できることを一切無駄なくやられているなという印象です。
砂金 無駄はたくさんあります(笑)。
柴田 いやいや(笑)、当然新しいことをやるので試行錯誤しなければいけないと思うのですが、試行錯誤ではなくて、ディレクショナルな無駄が全くなくて、さすがだなという。
尾原 そうですね。
(続)
本セッション記事一覧
- AIでEnd-to-endが主流になってきた自動運転技術
- 自動運転車のチューリングが挑む「何が起こるか」を予測できる生成AI
- エッジ生成AIのキラーアプリケーションは自動運転
- AIを作ることは「人間とは何か」という大きな問いを解決しようとすること
- リアルタイム音声認識「Poetics Speech API」が日本語では最高性能レベルの理由
- 人間は生まれながらにEnd-to-endでマルチモーダル
- 日本企業がLLMアプリ、AIを導入する流れを解説
- 自律的に物事を実行する「Autonomous AI Agent」とは
- 最先端のコールセンターを自律AIで構築する試み
- ソフトバンクの子会社「Gen-AX」が展望する企業向けエージェント、2026年までのロードマップ
- 2025年の生成AIはどうなる? 未来を信じて新たな産業を創ろう!【終】
編集チーム:小林 雅/原口 史帆/浅郷 浩子/戸田 秀成/小林 弘美