
▶新着記事を公式LINEでお知らせしています。友だち申請はこちらから!
▶ICCの動画コンテンツも充実! YouTubeチャンネルの登録はこちらから!
ICCサミット FUKUOKA 2020 先進企業のデータ活用経営を徹底解剖(事例研究:セプテーニHD / DeNA)の全文書き起こし記事を全7回シリーズでお届けします。(その3)は、セプテーニのデータ活用経営に興味津々の登壇者たちが、データやツールで、一体何がどこまでできるのかを鋭く問いかけます。それに対する佐藤さんの回答とは? ぜひご覧ください!
▶ICCパートナーズではコンテンツ編集チームメンバー(インターン)を募集しています。もし興味がございましたら採用ページをご覧ください。
ICCサミットは「ともに学び、ともに産業を創る。」ための場です。毎回250名以上が登壇し、総勢900名以上が参加する。そして参加者同士が朝から晩まで真剣に議論し、学び合うエクストリーム・カンファレンスです。 次回ICCサミット KYOTO 2020は、2020年8月31日〜9月3日 京都市での開催を予定しております。参加登録などは公式ページをご覧ください。
![]()
本セッションは、ICCサミット FUKUOKA 2020 プレミアム・スポンサーのビズリーチ様にサポートいただきました。
▼
【登壇者情報】
2020年2月18〜20日開催
ICCサミット FUKUOKA 2020
Session 4A
先進企業のデータ活用経営を徹底解剖(事例研究:セプテーニHD / DeNA)
Sponsored by HRMOS(ビズリーチ)
(スピーカー)
佐藤 光紀
株式会社セプテーニ・ホールディングス
代表取締役 グループ社長執行役員
丹下 大
株式会社SHIFT
代表取締役社長
崔 大宇
株式会社ディー・エヌ・エー
執行役員 ヒューマンリソース本部 本部長 兼 コンプライアンス・リスク管理本部 本部長
(モデレーター)
多田 洋祐
株式会社ビズリーチ
代表取締役社長
▲
連載を最初から読みたい方はこちら
最初の記事
1. データを活用して「従業員体験」を向上を図るのは、経営の仕事である
1つ前の記事
2. HR Techは、人類に良いものでなければならない(セプテーニ佐藤さん)
本編
多田 佐藤さんのお話で、気になったことがあれば質問をお願いします。
丹下 大さん(以下、丹下) 佐藤さんの経営メンバーチームの特徴で「プログラム型」というのがありましたが、これはほかに何パターンくらいあるのですか?

▼
丹下 大
株式会社SHIFT
代表取締役社長
1974年広島県に生まれる。2000年京都大学大学院 工学研究科機械物理工学修了。株式会社イ
ンクス(現 SOLIZE株式会社)に入社。たった3名のコンサルティング部門を、5年で50億円、140人のコンサルティング部隊に成長させ、同部門を牽引。2005年9月、コンサルティング部門マネージャーを経て、株式会社SHIFTを設立。代表取締役に就任。2019年10月、東証マザーズ市場から東証一部に市場を変更。「スマートな社会の実現」へ向け、社会インフラ企業を創るべく、SHIFTグループの企業フェーズ、企業価値をより高みへと導き、躍進をリード。
▲
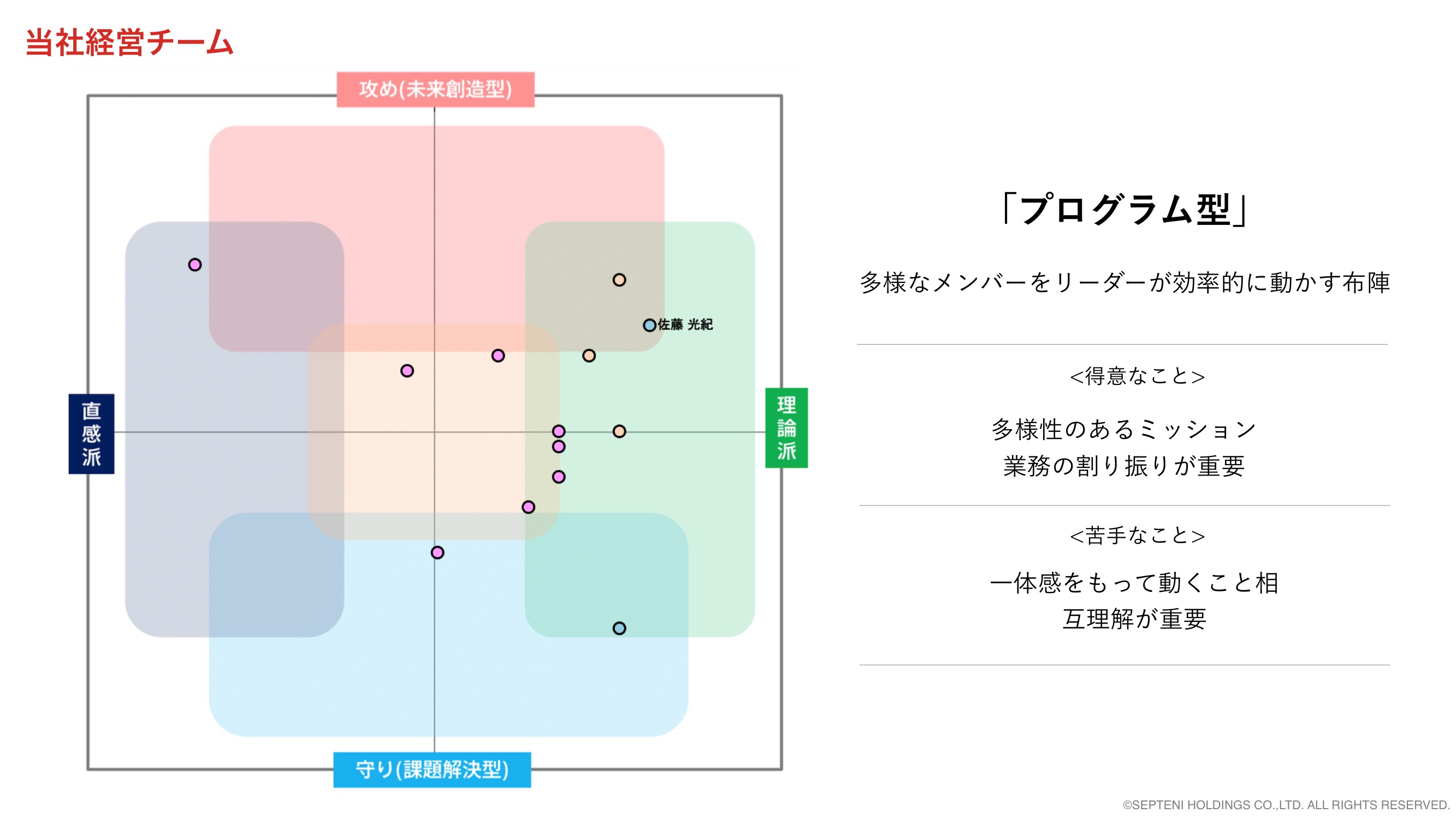
佐藤 数十パターンあります。
丹下 その数十パターンは、どれでも同じパフォーマンスが出るものなのですか?
例えば「プログラム型」と別の型を比べて、「プログラム型」だと1.5倍の生産性で、別の型が1.2倍などということがあるのですか?
欠員補充するときの、活躍予測ができる

佐藤 それは、担当する仕事によっても違っています。
例えばインフラ事業を手がけるチームに求められる分布とSaaS事業に求められる分布は違いますし、デジタルマーケティング事業、メディア事業、ゲーム事業など、それぞれの事業の特性によって、どのような偏りがあるとパフォーマンスが発揮されやすいかということには特徴があるので、「この型が一番良い」というように優劣を示すものではないのです。
どのようなジョブに取り組むかというジョブごとや、産業課題や事業などのビジネスゴールに対しての、フィッティングをきちんと見ていくというものです。
丹下 その数十パターンというのは、将棋の駒的に考えてしまうのですが、例えば新卒で採用するときに、この辺に欠員が出たからこの辺のメンバーを揃えようという感じなのですか?
佐藤 その通りです。
丹下 その通りですか。すごいですね(笑)。
佐藤 例えば営業組織があって、今この事業の営業組織に求められる分布はこの型で、その型に対して現状ではここが足りないということになれば、次に採用する人は願わくは、その位置の人に入ってきてもらうのがベストです。
そこで、応募いただいた方のデータも見ながら突き合わせをして、半自動的に、その人がうちに来ると活躍するかどうかがほぼ分かるということです。
丹下 新規開発は置いておいて、既存の、ある程度読めるビジネスでは、数式的に売り上げや利益がある程度読めるのですか?
佐藤 ある程度読めます。
丹下 マーケットがあれば読めるのですね。それはすごいですね。
佐藤 人材を何人採用すると、戦力化スピードが何ヵ月で何パーセントで、例えば一人当たり売り上げや一人当たり粗利などの何らかの事業指標があったときに「その事業指標の標準値にたどり着くまでの必要期間が何ヵ月」と出る感じです。
丹下 それは、HaKaSe miniでも分かるのですか?
佐藤 分からないです。
丹下 分からないのですか(笑)。そこがミソなのですね。
佐藤 それにはダイナミックデータがやはり必要で、事業ごとの変数がHaKaSe miniには入っていないのです。
どの事業を、どのポジショニングで、どの規模でやるのかという、企業ごとの動的なデータ、もしくはどのような企業理念で、どのような評価システムでやるかというようなことを、後からデータとしてどんどん追加していくので、体験版ソフトウエアが答えまで提供してくれるわけではありません。
丹下 miniはどこまでできるのですか(笑)?
多田 miniに興味津々ですね(笑)。
佐藤 多分、丹下さんであれば、miniだけでも相当使えると思います。
なぜならば、どの事業を、どの規模で、どのポジショニングで、どうしたいかという意思を、もう持っているからです。
意思のあるリーダーの元で、ソフトウエアがチームに対するデータを出せば、自分たちの事業でどこが足りないかが分かります。
組織をレイヤー分けして、例えば経営チームであれば、この部分のピースとして守りの人材が少ないとか、マネジメント層の課長としてここが足りないとか、メンバークラスにおいてはこうだということが、事業のタイプとの組み合わせによって、ある程度は分かると思います。
ツールの具体的な活用法は?

崔 大宇さん(以下、崔) 実はDeNAもこの考え方を、僕がHR本部長になってからやり始めていて、同じようなプロットをしています。
少し気になったのは、これはどちらかというとデータをどう活用するかという立場だと思いますが、従業員にどれだけ開示されているのでしょうか?
例えばマネージャーがこれを見ることができて、自分のチームとしてここのパーツを補いたいのでこういう人を異動してほしいと言えるなど、どのような会話がなされていて、どれくらい透明化されているのかについて教えてほしいです。
佐藤 まず、自分のデータは自分で見られます。
そして例えばマネージャーであれば、自分のチームのデータは見られるし、部長であれば自分の部のデータは見られます。そのような形で、データへのアクセス権限があります。
それから今、崔さんがお話しされたように、例えばマネージャーがダッシュボードを見ながら、ここの人が必要なのでここに埋めるような異動を検討してほしいということを、コーポレートのHRとやり取りすることはあります。
もちろんそれはケースバイケースで、その通りになるケースもあれば、ならないから逆に育成をしようということで、時間をかけて見込みのある人を育成するという意思決定につながったりします。
解決の仕方はいろいろあるという感じです。
崔 これはある意味で一つの切り方だと思うのですが、実際に異動する中で、このタイプということを主に論じるのでしょうか?
実際の活躍という面では、スキルや環境などいろいろある中の一要素だと思うのですが、この考え方に基づく会話というものが、結構なされるイメージなのでしょうか?
佐藤 それは多分、人のリテラシーによって違っていて、このようなデータを使いこなせている人と使いこなせてない人というのは、我々の社内にもおそらくいるのだと思います。
ただ、そのような啓蒙をずっとしているので、使いこなすマネージャーの方がやはり成果を上げるのです。
ですから自然と、成果を上げる行動を取ろうと思うと、ダッシュボードを使った方が良いという動機になってくる感じです。
丹下 ちなみに、何年くらいこれを運用しているのですか?
多田 お二人とも質問が止まりませんね(笑)。
佐藤 データの蓄積自体は、17〜18年くらいです。
丹下 17〜18年!すごいですね。
ビッグデータの蓄積で仮説が当たるように
多田 いきなりここに到達するのはなかなか難しいなと、見ながら思いました。
最初はどのように始めていったのか、振り返って、どのような方をアサインしてどれくらいの規模で始められたのか、ぜひ教えていただきたいと思います。

佐藤 最初は先ほど申し上げたように、人事担当の役員に『マネー・ボール』の本を渡して、「こんな感じで作ってほしい」と無茶振りした感じなので、かなり雑な始まり方です。
実際にこれがダッシュボードとして使えるようになってきたのは、この5年くらいですね。
やはりビッグデータが揃うまでの期間が必要で、データベースの構造がきちんと入口から出口まで統合的に管理できて、データ基盤が整った上でデータ量が一定程度あるという状態になって、我々の仮説がだいぶ当たるようになってきたのです。
それまでは当たったり外れたりを繰り返していたので、まだ現場で使えるレベルではなかったのですが、それでもやはり大事だからずっとデータは蓄積していこうという感じの時期が、10年くらいありました。
多田 ということは、何か意思決定をしたり成果が出たりしたものを、データを突合しながら、「合っている、合っていない」ということを10年くらい続けられていたわけですね?
佐藤 そうですね。以前ICCでもお話ししましたが、ベースになっているのは360度のマルチサーベイです。
上司と部下ではなく、自分と周りという形の360度のマルチサーベイを、年2回行っています。
この結果が、人に対する信用スコアやNPSのデータなどとして、ずっと蓄積されているということが大前提になります。
そこから枝分かれしていくデータとして、一人に対して平均619項目のデータがあります。
多い人はもっとあると思いますし、入社したての人は少ないというように、ダイナミックデータは人によって量が違います。
多田 半年に1回、そのデータがたまり続けるということですね。そのサーベイは、どんどん項目を変化させていったりするのですか?
佐藤 少しはしていますが、基本的にほぼ変化はないですね。サーベイ以外に、任された事業、ポジション、チーム、業務、その先の成績などがデータとなります。
(続)
次の記事を読みたい方はこちら
続きは 4.イノベーション人材を逃さない! データ活用が個性へのリスペクトを促す をご覧ください。
▶新着記事を公式LINEでお知らせしています。友だち申請はこちらから!
▶ICCの動画コンテンツも充実! YouTubeチャンネルの登録はこちらから!
編集チーム:小林 雅/浅郷 浩子/フローゼ 祥子/戸田 秀成
他にも多く記事がございますので、TOPページからぜひご覧ください。
更新情報はFacebookページのフォローをお願い致します。
