
▶新着記事を公式LINEでお知らせしています。友だち申請はこちらから!
▶ICCの動画コンテンツも充実! YouTubeチャンネルの登録はこちらから!
ICC KYOTO 2022のセッション「AIの最新ソリューションや技術トレンドを徹底解説(シーズン3)」、全11回の②は、データ利用の境界線議論からスタート。続いて人流データを扱うunerry内山 英俊さんが、高層ビルにいる人、電車に乗っていることまでわかってしまう、リアル行動ビッグデータについて紹介します その仕組みとは? ぜひご覧ください!
ICCサミットは「ともに学び、ともに産業を創る。」ための場です。そして参加者同士が朝から晩まで真剣に議論し、学び合うエクストリーム・カンファレンスです。 次回ICCサミット FUKUOKA 2023は、2023年2月13日〜2月16日 福岡市での開催を予定しております。参加登録は公式ページをご覧ください。
本セッションは、ICCサミット KYOTO 2022 プレミアム・スポンサーのリブ・コンサルティングにサポート頂きました。
▼
【登壇者情報】
2022年9月5〜8日開催
ICC KYOTO 2022
Session 11G
AIの最新ソリューションや技術トレンドを徹底解説(シーズン3)
Supported by リブ・コンサルティング
▶「AIの最新ソリューションや技術トレンドを徹底解説(シーズン3)」の配信済み記事一覧
尾原 unerryさんのようなソリューション(前Part参照)は、LINEさんも圧倒的に最後のタッチポイントで使っているし、最初のリーチにも使っているから、ものすごくユースケースは増えてきているのでしょうね。
砂金 そうですね。
技術的に可能なことと、それを扱う側の倫理観

砂金 LINEでいうと、 オフラインのタッチポイントとしてLINE Pay決済のほか、サイネージを見てQRで友だち登録とか、色々な方法で出来てきてはいました。
ただそれをスマホの中だけで完結するのか、リアルと連動するのか。LINE Beaconは昔から仕組みとしては使っていましたが、これらの活用には倫理観点が不可欠です。というのも、識別子を持つじゃないですか。
そういった識別子に紐づいた行動データをLINE、ヤフー、PayPayと全部連動するみたいなことが、環境的にも技術的にも可能ではあります。それによって広告やプラットフォームとしての価値は上がりますが、社会的責任みたいなものも同時に増えてきます。
技術的にはできて、許諾の範囲でいうとOKでも、ユーザーが気持ち悪いと思わないかどうかや、その一線を越えないような、扱う側の倫理観みたいなものはすごく気にしています。
今日は話す時間がないので話題としては省略しますが、顔認識の技術などもやっていて、1:1顔認識と、1:N顔認識は全然違うテクノロジーです。
尾原 1:1のほうは、あくまで自分が、自分のロックを外すために使うような。
砂金 はい。1:1は本人の顔写真と本人が特徴量として合致しているか、本人確認などで使うものです。
1:1はまあいいのですが、1:Nのほうが厄介です。
我々が例えば NTTコミュニケーションズとか、もうちょっと社会インフラをやってますみたいな体(てい)で、SIerであれば、一時期話題になった駅で使用する顔認証システムとかもいいのですが、「なんかLINEが顔データを撮って、判別してるぞ…」みたいなことは、ちょっと微妙な線じゃないですか。
ただ、お得意様判定みたいなものは、やろうと思えば全然できるんですよ。
尾原 そうですよね、来店客100人の中に、あっ、お得意様が入ってらっしゃる、みたいなことは。
砂金 例えば、ぱっと見て1,000人の中から1人を当てるようなことでも全然精度的にはできるので、やればできるけれども、やってしまっていいですか、日本で?と。たとえば中国だったら迷いなくやれるのですが。
unerryさんは、その辺のデータを、結果、行動データの蓄積としてすごい量を持たれていると思うので、上場企業としてデータ管理は大丈夫ですか?と言われると思います。頑張ってください(笑)。
データ利用の境界線

尾原 ただ、どうなんですかね。
例えば僕が今回ICCの会場に入る時に、まだ僕の顔が受付から見えない段階で、受付の人が僕のネームタグを持ってきてくれていて、「えっ、何で分かったの?」と聞いたら、「尾原さんの声は甲高いので、遠くから響いてました」と、声認識で僕を認識して持って来てくれて。
(一同笑)
まあそこはネタなのですが、でもそれは先回りをして本人のエクスペリエンスを良くしてくれるわけだから、これを日本語で言うと、「おもてなし」という言葉で言うわけですよね。
つまり、こういったものを、本人の行動を気持ち良くサポートするために使っているのか、本人のデータを全く知らないところで…、例えば僕がSNSを見ると、そろそろハゲが気になっていますよね?とか、久しぶりに日本に来たら、不倫に興味ないですか?みたいなものに追いかけ回されるわけですよ。
もちろん興味ないですよ、ハゲはあれですけれども…、というふうに、要はいわゆる自分の了承を得ないところで、他の人から無理矢理やられるのです。
つまり、自分のために自分のデータを使って動いているのか、勝手に「あなたのためでしょう?」とやられることなのかというところに、1つの境界線があるという話です。
それと、勝手に押し付ける場合は、あくまで本人を特定した形ではなくて、1回匿名化してからやるという、この2軸が、ヨーロッパのGDPR(General Data Protection Regulation:一般データ保護規則)というか、eプライバシー法(ePrivacy regulation)などでは一般的になっているマトリクスですが、この辺の整備は、なかなか難しいですかね。

砂金 そうですね。ヨーロッパは面倒くさいので、日本で事業をやるのはまだいいのですが、ヨーロッパの人もちょっと使うとなると、IPで遮断するか、何かをしないと結構大変だなと思います。
先ほどの許諾(オプトイン、前Part参照)の話で言うと、unerryさんにLINE連携していただいているじゃないですか。
▶unerry、「LINE POP Media 認定Beacon設置パートナー」へ(PR TIMES)
LINEのメッセージを送るAPIはプッシュ通知みたいなものと、リプライと呼んでいるものがあって、全然違う仕組みになっています。
プッシュ通知は広告などで使われるので、対象となりそうなセグメントの人たちに同時配信したりします。もちろん趣向やニーズにマッチしそうなメッセージを広告として配信する工夫をいろいろしているわけですが、状況によっては迷惑なこともあるわけじゃないですか。
だから、そこは1通いくらと広告商材として課金していて、リプライのほうは無料にしています。
コールセンターやカスタマーサポートもそうですが、「今ちょっと、これに、本当に困っているんですよ」とユーザー側が困っていて、企業やシステム側に何かアクションを求めている時、その返答は、これはユーザー側が困っている件だから無料で返そうということで、リプライのメッセージに関しては課金しないと、設計思想上できています。
尾原 なるほど、ユーザー同意の仕方みたいなところにもAIが入ってきているということなんですか?
砂金 AIかどうかは…、仕組みとして作られています。
尾原 まあUX上やっているかも?みたいな話ですけれども。
AIと人との間に必要な心地よい距離感

内山 それはまさに僕が言っている、「Ambient Intelligence(環境知能)」というものです。
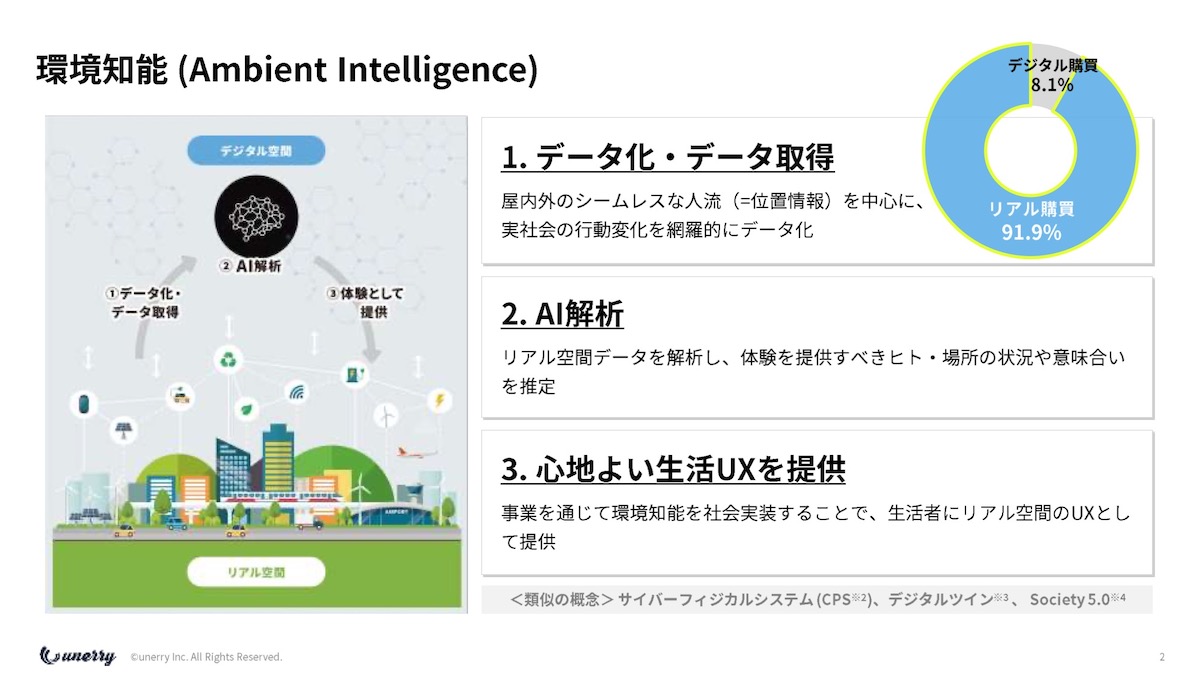
「Ambient」は日本語で言うと「環境」ですが、僕が多分正しく訳すと「空気を読む」という言葉だと思うんですよね。
尾原 KY AI?
内山 KY AI(笑)。そうですね。
例えばですが、打ち合わせに30分遅れるという場合、Googleカレンダーに予定を入れているなら、それを相手に自動的に連絡して欲しいんですよ。
それは技術的には今できるのですが、できていなくて、そんなことはいっぱいあると思っています。
あまりにもパーソナライズされても嫌だけれど、ギリギリのちょうどいい距離感みたいな、僕はそれを最近「心地よい」と言っていますが、それがすごく重要で、AIだったり、コミュニケーションに必要なんじゃないかなと思っています。
尾原 逆に言うと、その心地よい距離感をどのように作っていくかを、専門知識を持った専門会社がやっていくというのは、一つの強みでもあるということですね。
内山 そうなんですよね。
心地よさは、やはり人によって違うので、パーソナライズが、結果、活きる領域だと思います。
尾原 中国も京東(ジンドン)というアリババに次ぐ2位のECプラットフォームがありますが、京東は物を運ぶ人たちが全員社員なんです。
物を運ぶところまで全部コントロールできるので、5分間何でも親切をしていいよという時間をあげています。
まさに物を運んだ時のラストワンマイルでどういう振る舞いをすると、実際その後、お客様が惚れてリピート率が上がるのか、単価が上がるのかなどをAIで解析して、ホスピタリティを上げたり、良い距離感にするようなことは中国などではやっています。
内山 そうですね。それをきちんとパーパスとして定めてやるというのが、僕らのやっていることですね。
人流データを見てみよう
内山 ちなみに「人流データ」という言葉はよく聞くと思いますが、多分見たことがある人はあまりいないと思います。
おそらく見るとしたら、六本木の人通りが20%上がりました、下がりましたみたいなデータやグラフではないかと思います。
「人流データって何?」というところを、若干説明したほうが分かりやすいと思います。
尾原 そうですね。
内山 あと、今日僕がこの場にいる理由は何かな?と考えてみると、清水さんみたいな天才と、砂金さんみたいな、ちょっと……奇人と言うと申し訳ないですね(笑)、未来を見ている……
尾原 (笑)。未来に生きちゃってる人達ですよね。
内山 生きちゃってる人たちですね。
僕は元々二十数年前はAIエンジニア、研究者だったのですが、普通の人、普通の会社が、AIをどうやって使えるのか、その現実感みたいなところを伝えるのが今日の僕の役割なんだろうなと思っていまして、その辺の紹介を少ししたいと思います。
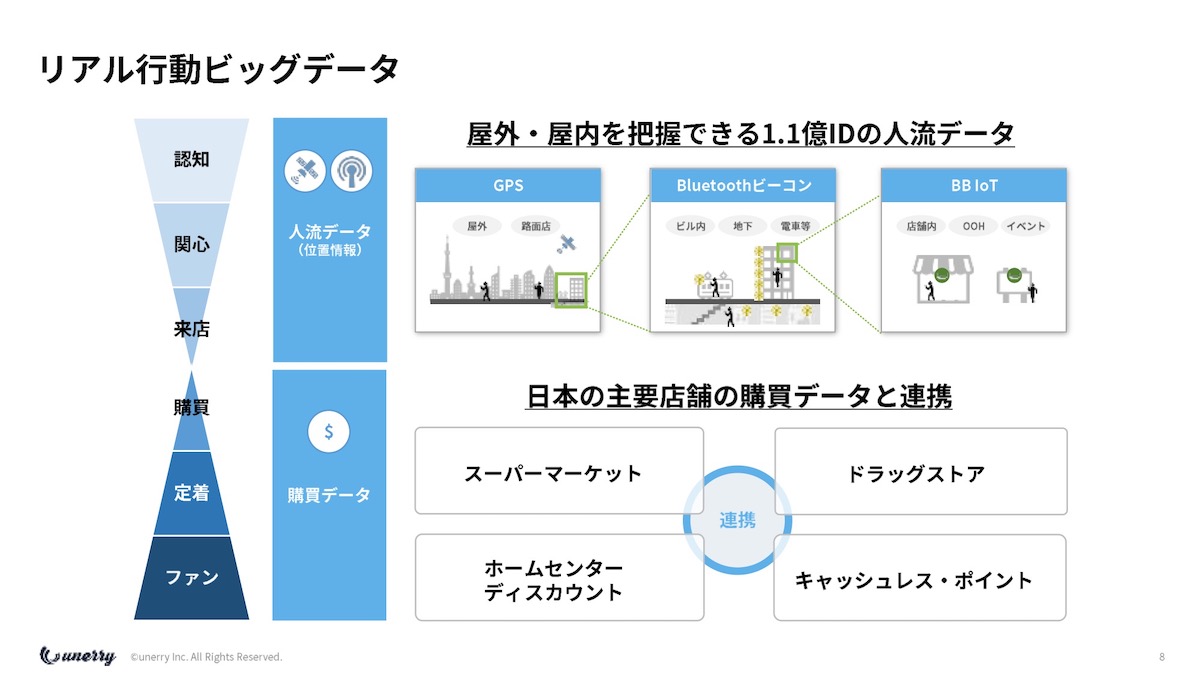
ちなみに1.1億IDの人流データと購買データが2つ合わさっているものを、僕は「リアル行動ビッグデータ」と言っています。
人流データは、屋外はGPS、屋内に入るとBluetoothセンサーのBeaconと呼ばれるもので取ります。
Beaconは今254万個ぐらい日本中に設置してあって、地下や電車や店、ビルの各フロアなどに実際に入っています。
東京の山手線も、実は全車両にBeaconが入っています。
▶山手線全車設置の「ビーコン」活用したサービス、提供開始 ゲームアプリへの活用も 2016.11.02(乗りものニュース)
そうすると、誰がどの電車に乗って、どのビルの何階に行ったかみたいなことも分かる仕組みに、現状なっています。
LINEさんもBeacon(LINE Beacon)をやられていて、そこは一緒にやらせてもらっているのですが、そんな仕組みだということです。
人流とはどんなものかお見せするのですが、東京の中心のマクロ的なところ、100万人ぐらいのデータを見ていくと、朝から始まっていって、昼になるとこうです。

黄色い箇所は高い所にいる人で、赤い箇所は低い所にいる人なんですよ。
尾原 高度も分かる。
内山 はい。
右側は、どちらかというと東京で低い地域ですよね。
左のほうは高い地域で、右側の低い地域なのにポツポツと黄色いのは、ビルの上にいる人です。
(時間を追って変化する人流データをデモ表示)
こんな感じのデータになっていて、一日の人の息づかいのようです。
今見ていたのは100万人ぐらいのデータですが、500人ぐらいのデータを見ていくと、より人が移動しているんだということがよく分かります。
こんな感じですね。車に乗っているとか、歩いているとか。
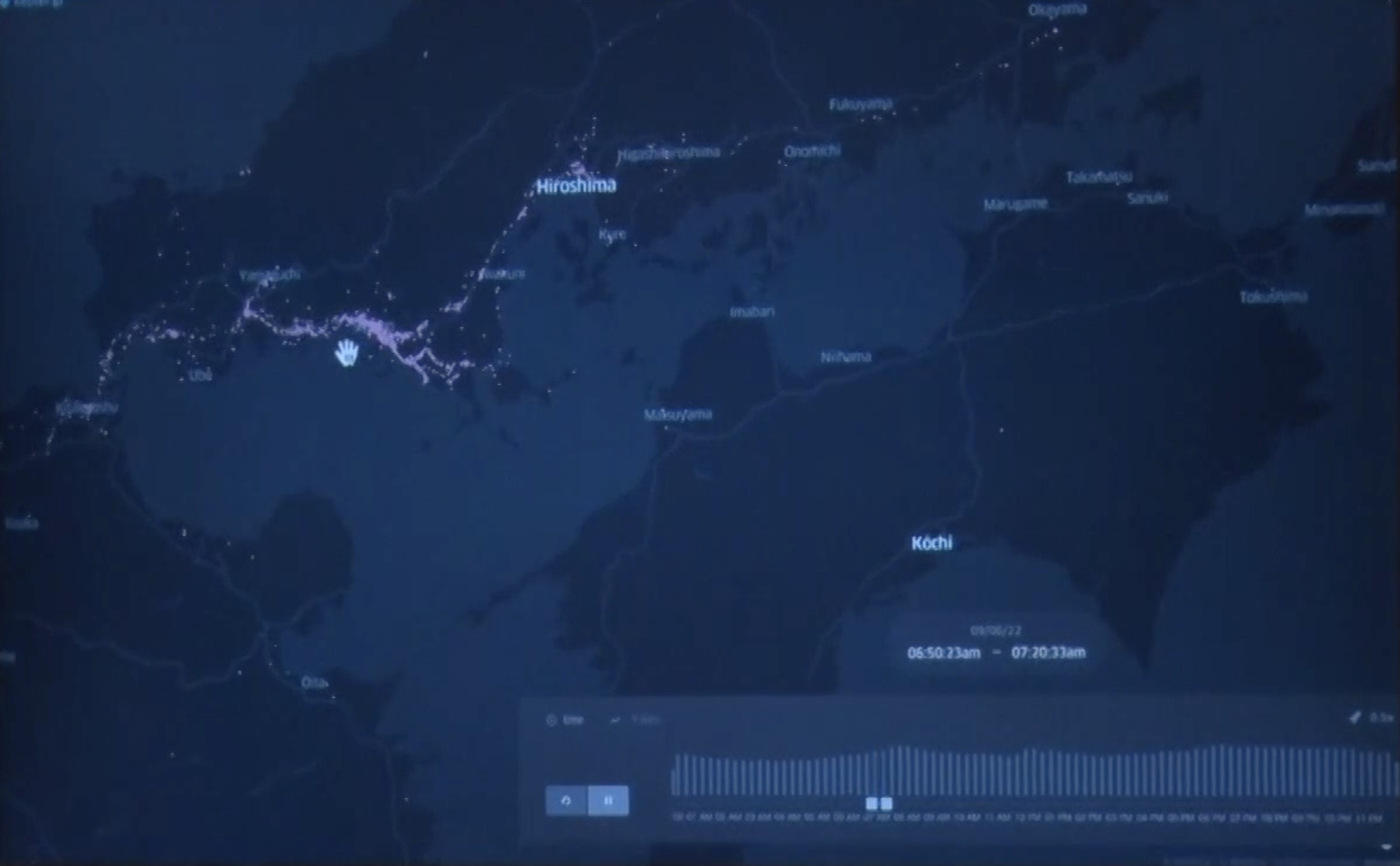
▶編集注:実際に会場で表示されたデータは動いています
尾原 おお~。どこからどこに散らばっていって、集まっていってと。
内山 新幹線に乗って移動しているのだなとか、こんなことが分かるのが人流データのイメージです。
人流データの構造

内山 ただちょっと問題があるのです。
AI的には結構な問題があって、人流データはどんな構造かというと、こんな構造なんです。
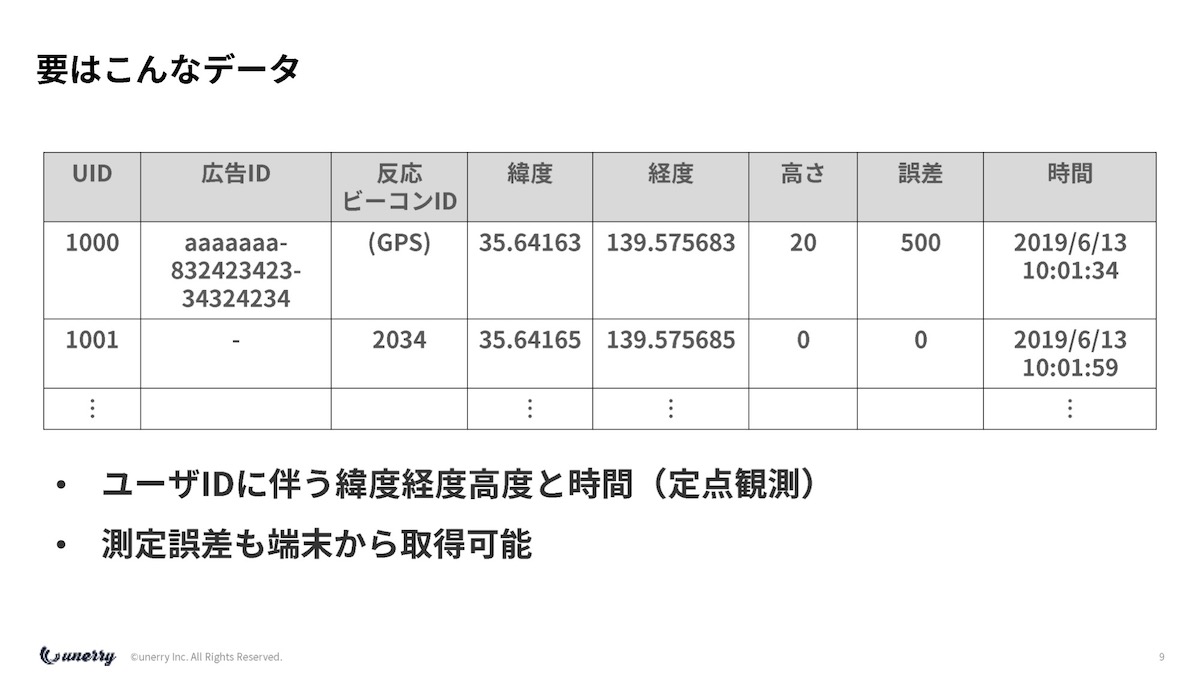
尾原 まあそうですよね、要は匿名化するためにIDでやっていて。
内山 そうなんですよ。端的に言うと、僕らは個人情報は全く持っていないので、端末のIDです。
「広告ID」というのは技術論があるのですが、アプリ横串で取れるIDがあります。
あとはBeaconと反応すると、BeaconのIDがあって、緯度・経度があって、高さがあって、誤差があって、時間があります。
尾原 なるほど、だから誤差で信頼度もちゃんと取っているわけですよね。
内山 そうです。でも端的に言えば、これだけのデータしかないんですよ。
尾原 まあまあ、データで言えば。
内山 データで言えば。
ユーザーIDに伴う緯度・経度、高さと時間を、僕らは何分かに1回とか1分に1回定点で取っているので、そのデータと、あとは誤差も取れます。
このデータはAI的には結構苦しいんですよね。
なぜなら、AIの場合、パラメータ勝負じゃないですか。
尾原 はい、本来的にはね。
内山 そうです。
パラメータはこれだけしかないという問題です(笑)。
ここからAIをどう作るのかというのは、かなり苦しい戦いなんですよ。
だからAI的にいうと、“ここからパラメータの数をどう増やすか勝負”というのが、僕らがやっていることです。
(続)
【本セッション記事一覧】
- AIの開発に関わるトップランナーたちが集結したシーズン3!
- 「人流データ」から、何がどこまでわかるのか?
- Googleマップの薄い青い円はデータの誤差! 高精度のAIに必要なものとは
- 取得データが多すぎる問題にどう対処する? unerryが上場した目的
- 全国254万箇所の来店検知で「行動DNA」が丸わかり
- 動的データで、人のペルソナ分類から半導体出荷量予測まで明らかに
- イメージと手描きでリアルな画像生成、話題の画像生成AI「Stable Diffusion」
- 長文要約、文章生成…ここまでできる! 日本語の大規模言語モデル「HyperCLOVA」
- 日本のビジネスメールや心削られる謝罪メール、すべてAIにおまかせ
- 天才プログラマー清水 亮が指摘する「検索から生成へ」の変化
- ハイコンテクストな文化こそが参入障壁、日本の「生成系」に勝機あり!
▶新着記事を公式LINEでお知らせしています。友だち申請はこちらから!
▶ICCの動画コンテンツも充実! YouTubeチャンネルの登録はこちらから!
編集チーム:小林 雅/小林 弘美/浅郷 浩子/戸田 秀成