
▶新着記事を公式LINEでお知らせしています。友だち申請はこちらから!
▶ICCの動画コンテンツも充実! YouTubeチャンネルの登録はこちらから!
ICC KYOTO 2022のセッション「AIの最新ソリューションや技術トレンドを徹底解説(シーズン3)」、全11回の⑤は、全国254万箇所のBeaconから来店予測をするunerry内山 英俊さんが、さらにその技術を詳説。リングサイドのEBILABの小田島 春樹さんも興味津々です。ぜひご覧ください!
ICCサミットは「ともに学び、ともに産業を創る。」ための場です。そして参加者同士が朝から晩まで真剣に議論し、学び合うエクストリーム・カンファレンスです。 次回ICCサミット FUKUOKA 2023は、2023年2月13日〜2月16日 福岡市での開催を予定しております。参加登録は公式ページをご覧ください。
本セッションは、ICCサミット KYOTO 2022 プレミアム・スポンサーのリブ・コンサルティングにサポート頂きました。
▼
【登壇者情報】
2022年9月5〜8日開催
ICC KYOTO 2022
Session 11G
AIの最新ソリューションや技術トレンドを徹底解説(シーズン3)
Supported by リブ・コンサルティング
▶「AIの最新ソリューションや技術トレンドを徹底解説(シーズン3)」の配信済み記事一覧
データクレンジングの仕組みには秘伝のタレがいっぱい
内山 unerryのAIロードマップですが、クレンジングするためのAI、デジタルの世界で当たり前にやっていることをリアルに転用するAI、リアルならではのAIを、それぞれ軽いところから深いところまでやっています。
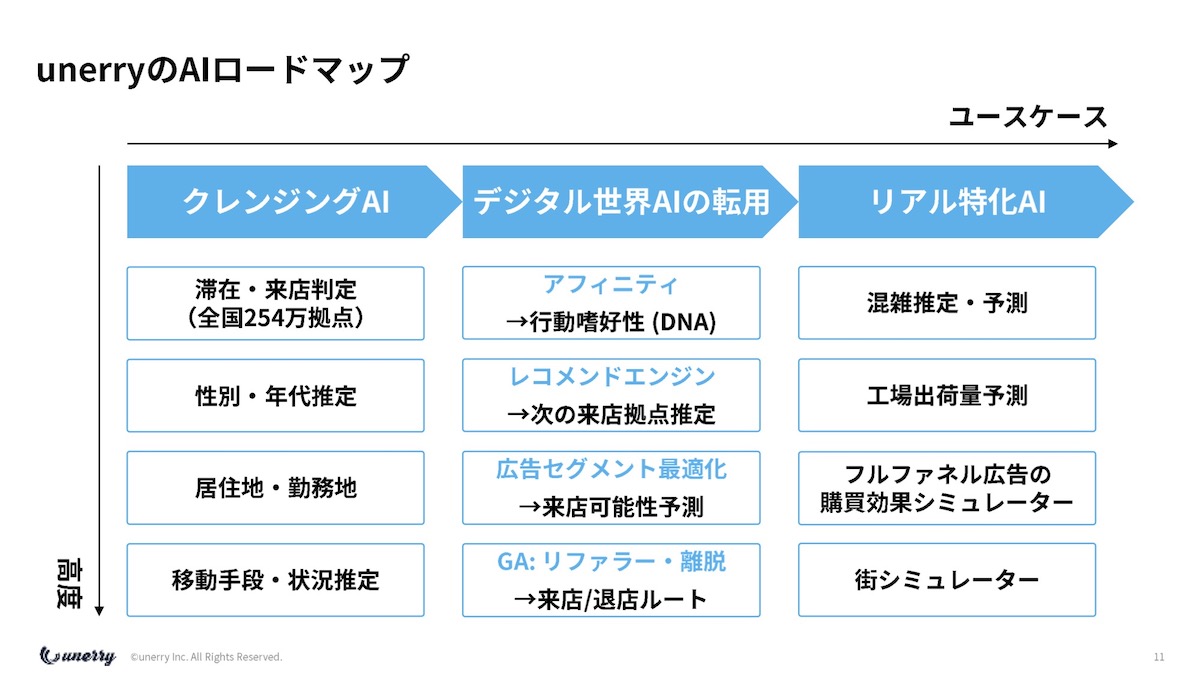
簡単に紹介すると、一番命を懸けているのが「滞在・来店判定」です。
尾原 これは一番大事なところじゃないですか、盛り上がりたくなるなあ!
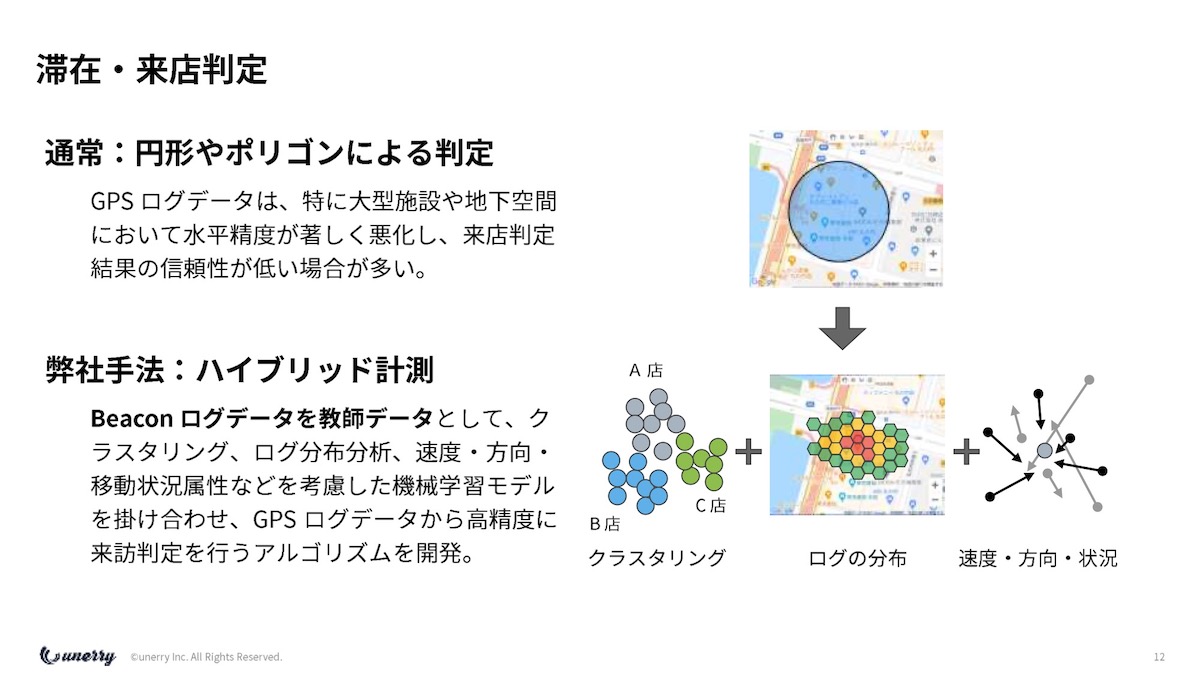
内山 イメージ的に言うと、ポリゴン(地図上の、線で囲んだ多角形)はビルの形だったり、または円形で引いて、そこにGPSのログがあれば、そこに来店したというのが普通の考え方だと思うのですが、先ほど言ったように(Part.3参照)、そもそも建物に入るとGPSのログはずれるのです。
建物に入った瞬間に、そこのログは実はないという問題が起きます。
僕らは、ハイブリッド計測という手法をとっていて、Beaconが254万個ありますが、Beaconがあるということは、ほぼ絶対的に来店を判定できるのです。
これを正解データとして、ビルの1階のドラッグストアにBeaconがあると、そこはGPSのログも取れているし、Beaconのログも取れています。
そうすると、この人は絶対にこの店の中にいるはずだけれども、GPSログは300mずれているみたいなことが起きるのです。
その辺りの誤差の判定やその時の移動の向いている方向などを見て誤差判定みたいなことをして、僕らはBeaconがなかったとしてもGPSのログだけで来店判定をします。
それを254万箇所でやっているんですね。

尾原 ここも秘伝のタレがいくつか入っていますね。
教師データとして、機械学習を組み合わせたアルゴリズム。
清水 これは非常に特許性がありますね(笑)。
尾原 ごめんなさい。ここはツッコミすぎるとライバルの話になりますからやめましょう。
砂金 これはでも、ちょいちょい電波環境によって変えていかなければいけないですよね。
尾原 そうなんですよ、こういうところのクレンジングの仕組みに秘伝のタレがいっぱい残るんです。
砂金 これは、精度が下がってきたぞみたいなのは、どういうイベントで検知できるんですか?
内山 店ごとの単位で見ると、やはり突然ボコンと来店人数などが上がってしまったりします。
通信環境が変わっていたりとか、よくWi-Fiのアクセスポイントが変わると、一気に通信環境が良くなるので、なんかそういうことがあるんですよね。

尾原 (会場に向かって)今こうやって盛り上がるでしょう?
こういう例外処理のどこに秘伝のタレがあるかで盛り上がっていますが、こういうことを分かっておくと、AIビジネスの肝が分かります。
ライバルではできない、こういう実質ビジネスのところで、絶対ここの誤差にこだわったほうがお客様にいいデータが提供できるというこだわりの感度が、実はAIベンチャーの秘訣なので、やっぱり2人は実践を積み重ねてますね!
砂金 だって、初期モデルのベースコードって、それこそGitHubに落ちているか、論文をパクって実装すれば動くんです。
100店満点中70点ぐらいのものができるのですが、それを1回とりあえず初期商用版みたいな90点ぐらいのものにして通ると、だんだん劣化するんですよね。
尾原 逆にね。
砂金 それをちゃんと維持継続するのには、普通にやると非常にコストや人手がかかるみたいな話で、それをどう自動化するかというところまで考えないと、モデルを外部に提供するのは多分やらないほうがいいです。しんどいです。
内山 本当です。
砂金 254万箇所でこれを維持するのは、すごい大変だろうなと思って。
unerryと競合サービスとの違い

尾原 内山さんは本当に非常に色々な方のユースケースを想定しながらやっているから、汎用性の高い実利があるデータにする工夫がすごいのです。
一方、前回で言うと、小田島さんは逆に実践から割り切って、シンプルなデータでいいじゃないかみたいなところが印象的でした。
アプローチが全然違っていいなと思うのですが、そこら辺のアプローチの違いは、こういう話を聞いてどう思われます? 小田島さんはゑびやとして実際にリアル店舗で、店員がどうやれば集客を増やせるか、看板をどうすれば集客を増やせるかみたいな、本当に店舗さんが使える実践AIというところをやられています。
▶来客予測的中率は90%以上!データドリブンな店舗経営を実現する「TOUCH POINT BI」(EBILAB)(ICC KYOTO 2022) |【ICC】INDUSTRY CO-CREATION (industry-co-creation.com)
小田島 そうですね、大変だなあと思ってお話を聴いていました。
やっぱりセンシティブなデータも含めて、個人に関連しそうなデータを扱うことの、何て言うんですかね…、直接商売に繋がるまでの距離が、聴いていてすごい遠いなあと感じました。
結局、僕らのPOSデータはすごくきれいなデータで、誰が買った、何を買った、何時に買ったというのをずっと追いかけているので、お聞きしている観点でいくと大変そうだなと思いました。
僕らは人流データを取るときに、よりミクロな、店前や信号機の下を通過した人とかをよく取っています。
人流データには、そういうミクロなデータ、unerryさんがやっているようなデータ、例えば、携帯の基地局を使うような、モバックみたいなデータがあります。
unerryさんのデータも多分モバイル空間統計とかとすごい近いデータなのかなと思っていて、そこは何か違いというか、脅威になったり、競合だったりするのでしょうか?
尾原 結局キャリアでも取れるデータって、結構あるじゃないかと。
小田島 そうですね。
尾原 他との違いをどう出していくのかと。

内山 いやもうこれは、僕が作っている決算発表資料(25ページ)にそのままのページがあるのですが、モバイル空間統計さんは、実は一緒にやっているんですね。
(会場笑)
モバックはNTTドコモのキャリアデータですが、500mのメッシュデータなんですよ。
だから、500m×500mの枠の中に、どんな人が何人いますかということがずっと出ているデータです。
僕らは高精度位置測位なので、どの場所にいる人とか、来店判定をします。
ただ、お互いメリットとデメリットがあって、モバイル空間統計はキャリアデータなので、僕らの弱い70代も含めてデータが存在します。
だから、属性や人数などの補正に使うのはモバイル空間統計です。
その人が本当にそこにいたかどうかは、僕らのデータで取るような掛け合わせでやっています。
小田島 なるほど、ぜひ使わせてください(笑)。
尾原 ゑびやさんだと、店舗の売上をどう上げるかは実践から逆算で考えるので、先ほどさらっとおっしゃっていましたが、店舗の近くの信号を越えたところに、人が何人いるかみたいな、店舗の運営にとって本当にクリティカルに効くデータが取れればいいわけで、だとしたら、どんな画像認識を使えばいいか?というふうに絞り込むアプローチです。
一方unerryさんの、プラットフォーマーとして汎用型でみんなが使えるデータ、Google Analyticsのようになっていくためにはどうすればいいかというのは、やはり違います。
そこら辺の汎用化への絞り込みはすごいなあと思う一方、なぜこういう話をしたかというと、利用者側からすると、ここまで汎用化にこだわらなくてもいいケースがあるので、そのバランスは難しいですよね。

清水 すごいし面白いなと思うし、自分も使ってみたいけれども、使い方が全く分からない。
久しぶりに全く分からないものを見たなと。
尾原 (笑)。
清水 今バー(技研Bar 清水さんが運営する技研ベース内のバー)をやっているけれど、自分の商売には全く関係がなさそう。
うちのバーは、美味しそうな店があるから入ってみようという感じでは全くなくて、知り合いからぼったくることだけが目的のバーなので、尾原さん、来てください。
(会場笑)
だから、使ってみたいなと思いつつ、全く使い道を思いつかないのが悔しいというか、ゲームとかに使えたらいいんだけど、そういうものでもないですよね。
結局マーケティングに使うんでしょうね。
内山 ゲームとかだと、結局生活体験に使うので、最近だと一番流行っているSTEPN(NFTゲーム)とか、位置情報NFTみたいなところの裏側の技術としては結構使ってもらっています。
位置情報NFTに一番重要なのは、来店判定なんです。
その店に行った時に、NFTを本当にもらえる権利があるかは、来店判定技術がないと多分成り立たないと思います。
清水 へえ。APIは実際おいくらなんですか?
内山 アプリにSDK(ソフトウェア開発キット)を提供していますが、10万円から60万円ぐらいの範囲で、そんなに(高くないです)。
清水 取れるデータとしては?
内山 先ほどの位置情報の羅列(Part.3参照)のほかに、来店したかどうかや、あとはその人が何を使って移動しているのか、車なのか、電車なのか、その辺の属性をバーっと付けていく感じですね。
清水 面白そうですよね。
来店検知で分かる行動嗜好性
内山 やれることは結構ありまして、時間の関係上手短に、他に何をやっているかご説明します。
一同 ぜひぜひ!
内山 ウェブの世界では、Google Analyticsには、アフィニティカテゴリがあるじゃないですか。
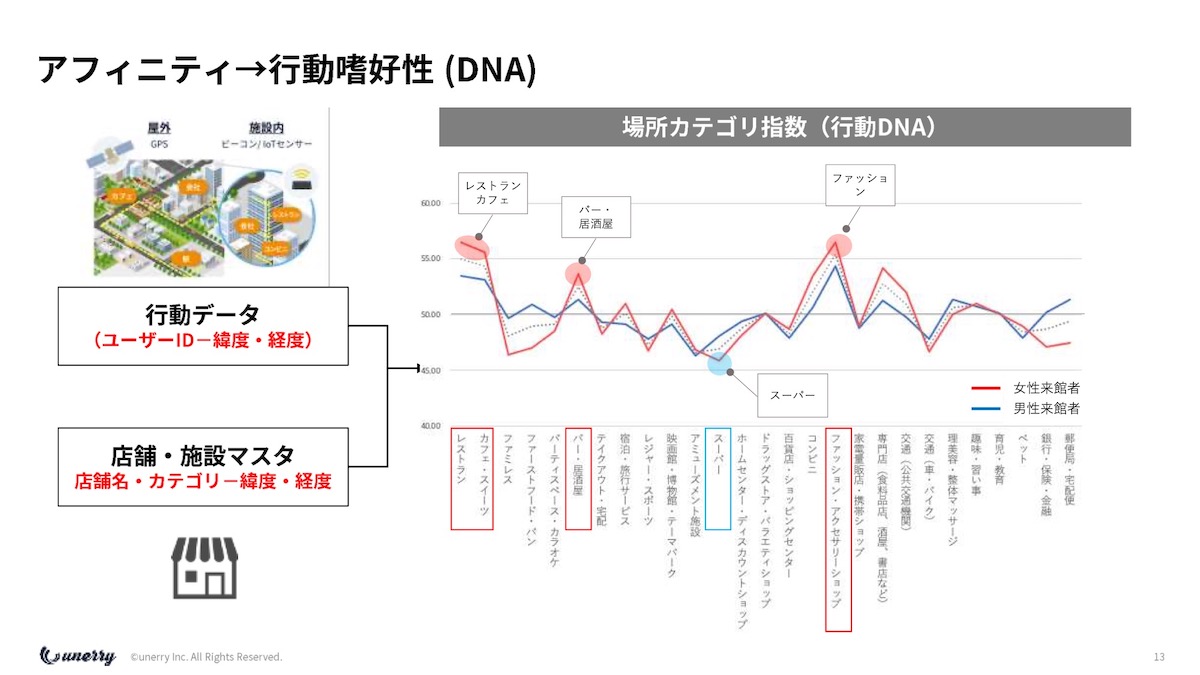
どのウェブサイトを見ているかによって、その人の嗜好性が分かりますし、先ほど言った254万箇所の来店を検知していると、その人が普段スーパーに行くけれどあまりバーに行かないとか、行動特性が分かります。
その人の行動嗜好性を、僕は「行動DNA」と言っています。
清水 「その人」というのは、例えば、僕がウェブアプリを作っていて、APIでそのページか何かをJAVAスクリプトで呼ぶと、「その人」というのが出てくるんですか? という訳ではない?
内山 現在はアプリのユーザーですね。
清水 なるほど、じゃあ端末ID的なもので、その人の判定に。なるほど、なるほど。
内山 これで、パラメータを増やしてくのです。
そうすると、254万箇所からよりカテゴライズされたパラメータになっていって意味づけがされていきます。
これが分かると、何が分かるかというと…
清水 すごすぎない?
内山 レコメンドエンジンみたいなものが分かっていきます。
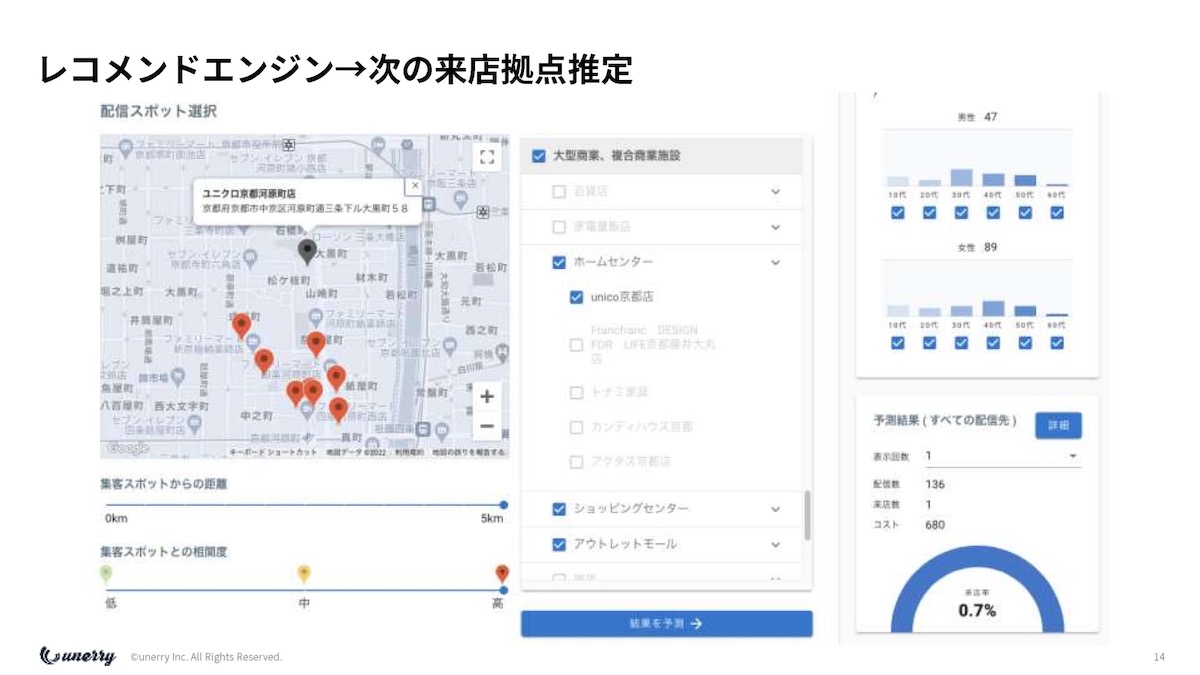
Amazonで、この本を買った人はこの本を買っているという協調フィルタリングがあると思いますが、これのリアル版を作っているのです。
これは昨日のデータを取ったのですが、ユニクロの京都の河原町店に行った人はその次にどこに行くのかみたいなところですね。
清水 これをAPIで見られるということですか?
内山 はい。管理画面もありますし、APIでも取れます。
尾原 はー。
清水 これをアプリでどう活用するんだろう? 例えば、ユニクロポイントアプリみたいなものにSDKが入っていて…
内山 とか、はい。
清水 ユニクロを出て行ったら、次はミスタードーナツの広告が出るみたいなイメージなんですかね。
内山 ちょっと順番を逆にしていただくと、ユニクロに来る可能性が高い人はどこですか?というふうにも使えます。
尾原 そうするとターゲティングで、そのお店の広告を出したり、クーポン連携したりとか。
内山 使ってもらっているのは……、ユニクロさんは使ってもらっていませんが、ユニクロだとしたらうちのSDKを入れておいていただければ、ユニクロに来る可能性の高い人が、他に行った瞬間に、プッシュ配信を送ってユニクロに来てもらうというユースケースは結構あります。
レコメンドエンジンですね。

清水 すごいね、ちょっと怖い(笑)。
普段あまりこういうものに対して怖いって言わないタイプだけど、若干怖い(笑)。
尾原 まあ、だからこそ、最初にその辺のプライバシーに関わる話(前Part参照)を丁寧にしたんです。
そうしないとみんな誤解してしまうから。
砂金 昔からありますよね。
ガソリンスタンドで給油した後に、ちょっと重たいもの、水や色々なものが買えるホームセンターに行く確率はすごく高いから、ガソリンスタンドの給油のレシートにクーポンを出しましょうみたいなことは、もう20年前からやっていますよね。
よりアクセシビリティが上がったというか、特定のプラットフォーマーでなくても、この仕組みをAPIで使えるようになっているというのは、結構色々可能性が広がりますね。
尾原 逆にこれは匿名化しているグルーピングだから、比較的やりやすいタイプのものですからね。
内山 これと広告を連動させるので、この辺に行った人に対して、広告を打つ仕組みとも連動しています。
(続)
【本セッション記事一覧】
- AIの開発に関わるトップランナーたちが集結したシーズン3!
- 「人流データ」から、何がどこまでわかるのか?
- Googleマップの薄い青い円はデータの誤差! 高精度のAIに必要なものとは
- 取得データが多すぎる問題にどう対処する? unerryが上場した目的
- 全国254万箇所の来店検知で「行動DNA」が丸わかり
- 動的データで、人のペルソナ分類から半導体出荷量予測まで明らかに
- イメージと手描きでリアルな画像生成、話題の画像生成AI「Stable Diffusion」
- 長文要約、文章生成…ここまでできる! 日本語の大規模言語モデル「HyperCLOVA」
- 日本のビジネスメールや心削られる謝罪メール、すべてAIにおまかせ
- 天才プログラマー清水 亮が指摘する「検索から生成へ」の変化
- ハイコンテクストな文化こそが参入障壁、日本の「生成系」に勝機あり!
▶新着記事を公式LINEでお知らせしています。友だち申請はこちらから!
▶ICCの動画コンテンツも充実! YouTubeチャンネルの登録はこちらから!
編集チーム:小林 雅/小林 弘美/浅郷 浩子/戸田 秀成