
▶新着記事を公式LINEでお知らせしています。友だち申請はこちらから!
▶ICCの動画コンテンツも充実! YouTubeチャンネルの登録はこちらから!
ICC KYOTO 2022のセッション「AIの最新ソリューションや技術トレンドを徹底解説(シーズン3)」、全11回の⑦は、LINEのAIカンパニーCEOの砂金 信一郎さんが登場。話題の画像生成AI「Stable Diffusion」は一体どんなことができるのかをデモンストレーションします。複数の画像と手描きを合わせて生まれる画像とは? ぜひご覧ください!
ICCサミットは「ともに学び、ともに産業を創る。」ための場です。そして参加者同士が朝から晩まで真剣に議論し、学び合うエクストリーム・カンファレンスです。 次回ICCサミット FUKUOKA 2023は、2023年2月13日〜2月16日 福岡市での開催を予定しております。参加登録は公式ページをご覧ください。
本セッションは、ICCサミット KYOTO 2022 プレミアム・スポンサーのリブ・コンサルティングにサポート頂きました。
▼
【登壇者情報】
2022年9月5〜8日開催
ICC KYOTO 2022
Session 11G
AIの最新ソリューションや技術トレンドを徹底解説(シーズン3)
Supported by リブ・コンサルティング
▶「AIの最新ソリューションや技術トレンドを徹底解説(シーズン3)」の配信済み記事一覧
国立国会図書館のデジタル化資料247万点をテキストデータ化
尾原 砂金さん、いきましょうか。
LINEです。すごいですよね、だってAIカンパニーがあるわけですものね。

砂金 AIで、研究するのではなくて、事業をやれています。まあ、割と何かが重なって…
尾原 カンパニーというところは、コストダウンではなくて利益を上げるところですからね。
砂金 難易度も高いのですが、そこにチャレンジをしています。
こちらは最近の仕事で、昨日ようやくプレスリリースを出したものですが、国立国会図書館の昔の資料に関わるものです。
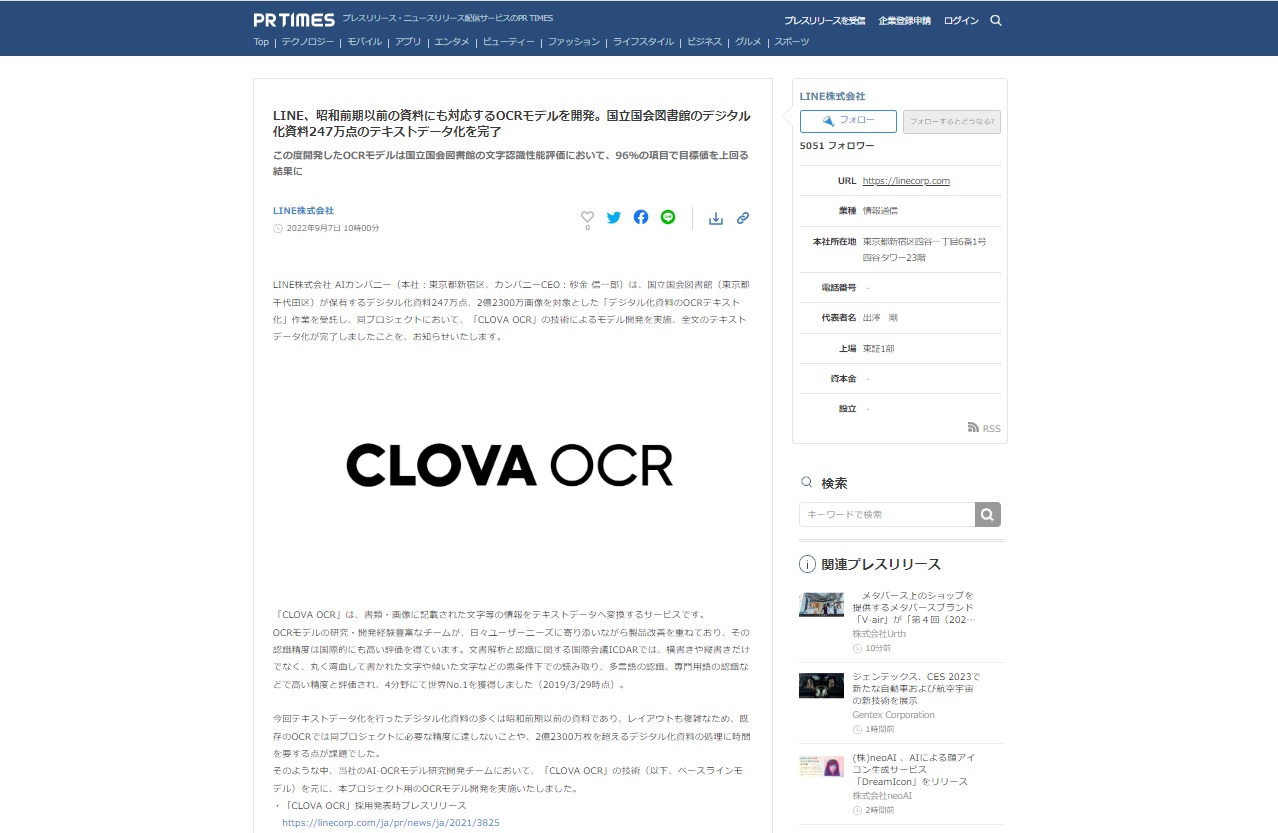
▶LINE、昭和前期以前の資料にも対応するOCRモデルを開発。国立国会図書館のデジタル化資料247万点のテキストデータ化を完了(PR TIMES)
こちらは国立国会図書館から、公開されているものです。
▶デジタル化資料のOCRテキスト化改善結果報告書(LINE)

尾原 古文書や、その辺りの古い文字もデジタル化できるようにしたんですね。
砂金 はい。こちらをデジタル化するということで、我々がご支援していました。
どういうデータ・文献を対象に、何をやるか。文字コードなども処理しました。
この辺(報告書14ページ)はサンプルで分かりやすいと思いますが、昔の文字は結構日本語ではあるのですが、非常に読みにくい。

尾原 そうですよね、旧字もあるし、文字の字崩れも多いし。
砂金 これをテキストデータ化しました。
完全デジタルというよりは、検索可能性を高めたいというのが、国立国会図書館の皆さんの課題感なので、その支援を非常に真面目にやっていました。
これは、「スピルカ」ではなくて、「カルピス」ですよ(報告書20ページ)。
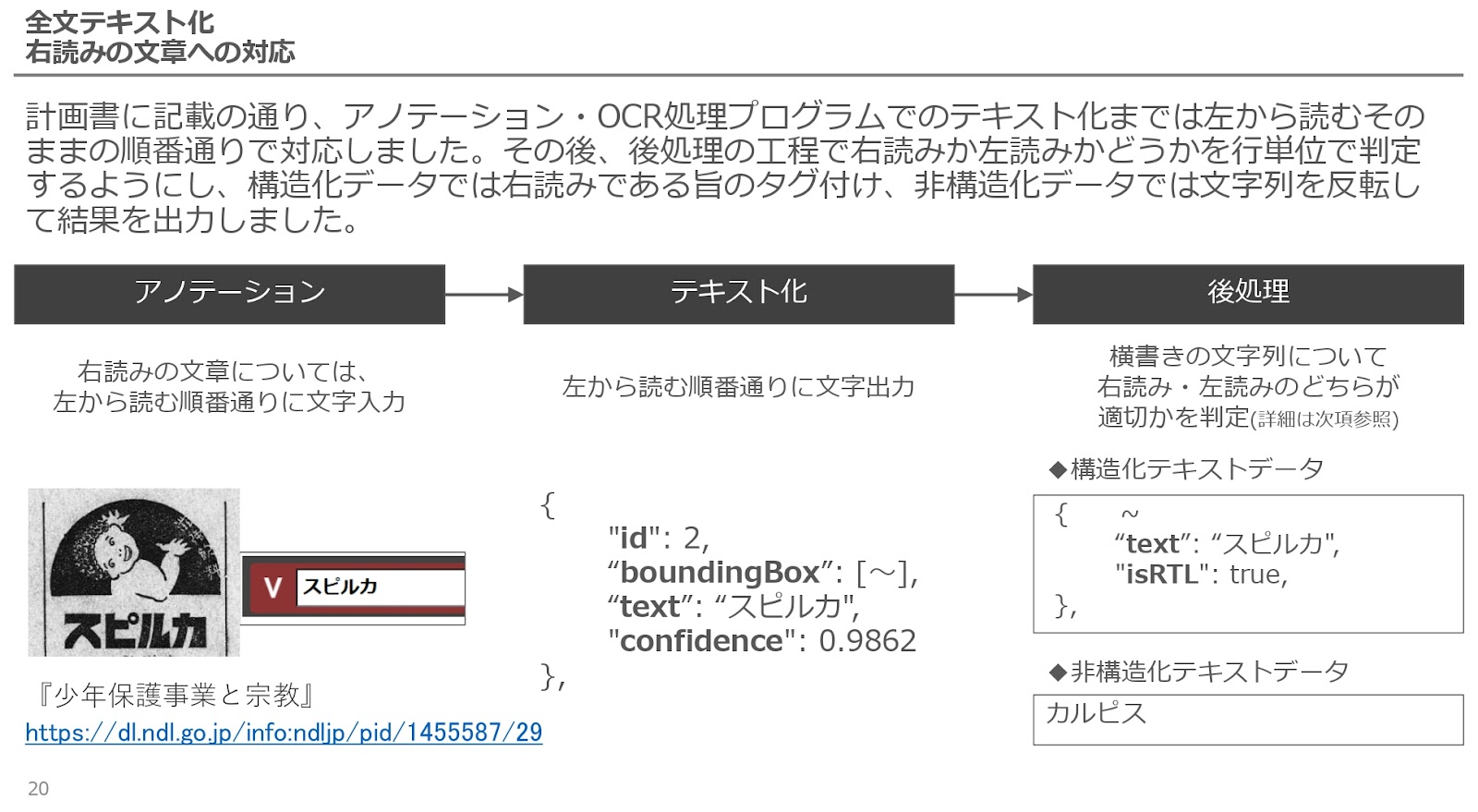
今は左から右に読みますが、昔は右から左だったので、“どちらから読むのが正しいのか確率判定”みたいなところにも取り組んでいました。
結構深みにハマったプロジェクトではありました。
尾原 遠目に見ても面白い。
砂金 このようなことを事業としてやっています。
尾原 これは公開されているんですよね?
砂金 はい、出ています。
尾原 詳しく知りたい方は、ぜひご覧ください。
話題の画像生成AI「Stable Diffusion」をデモンストレーション
砂金 これは我々がやっているというより、世の中で流行っているもので、Stable Diffusionです。
尾原 いきなりプロンプトを入れ始めましたね。
砂金 はい。
画像生成で遊んでいる方もいらっしゃると思いますが、UIをちゃんと作ったり、色々なエコシステムが爆発的に今増えていて、すごい面白いことになっているなとは思います。
尾原 「Nikon D850で撮ったような」と、今テキストを入れましたね。
砂金 そう、プロンプティングのところに、仕上げをリアルフォトみたいな感じでとか、どういう環境で撮影したのかみたいなことを入れると画像が出てきます。
今のようにプロンプティングをして、イメージを出してくるのはまだいいのですが、私がもっと破壊的だなと思っているのは、image-to-imageで、こんな感じの画像が私は欲しいみたいなものを、今まではPhotoshopやIllustratorなどで加工して作っていました。
尾原 イメージのパーツで入力するんですね。
砂金 そうそう。富士山で、稲妻が光っていて、ちょっとカッコいい絵が欲しいみたいなパーツを。

尾原 Adobeで加工できるレイヤーでやっているから、インプットデータを他からパクパクと…
砂金 (今は)インプットを作っている最中ですね。
尾原 あっ、そういうこと。
砂金 まだです。
尾原 あっ、ここからがそうですね。

砂金 そうです。
尾原 既存のレイヤーで作って取るわけですね。
砂金 こんな感じのものが欲しいんだよというのを、1つ前のもの(犬のイラスト)は、プロンプティングをテキストで入れていましたが、これはイメージで入れられるというのが、暴力的だなと思います。

尾原 はあ、そうすると、1回コンセプトに落として、それでもう1回拡張するのか。
砂金 そうなんですよ。
尾原 Photoshop側から直接呼び出せてしまう。
そうすると循環が速くなるものね。
これ(左)を加工すると……(右が絶え間なく変化)うぉー!
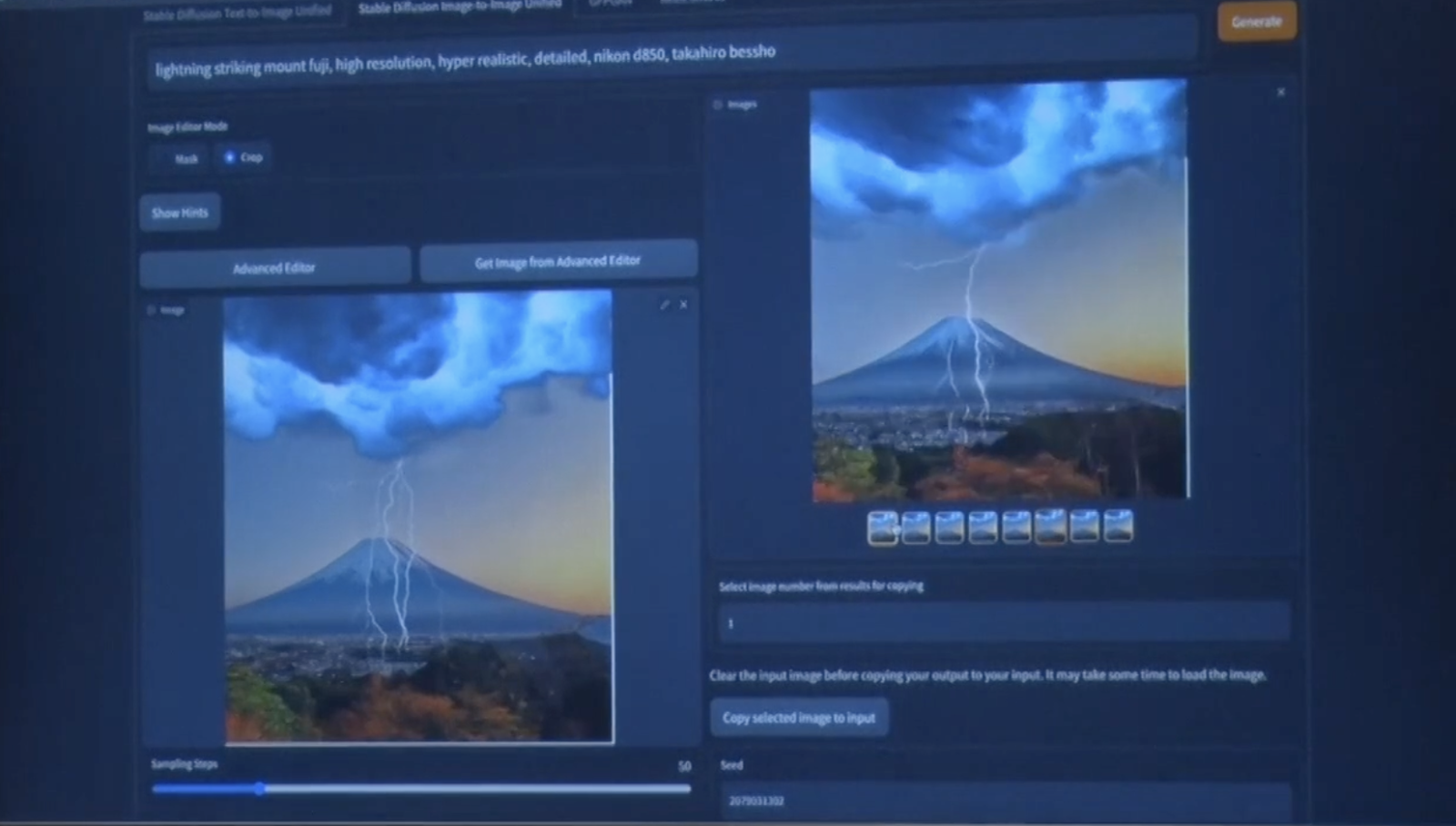
砂金 なんとなく良さそうだみたいなものをいったん選んで、ここにさらに、火山が噴火して溶岩が流れて大変だみたいなものを加えます。(と、赤い線を加える)
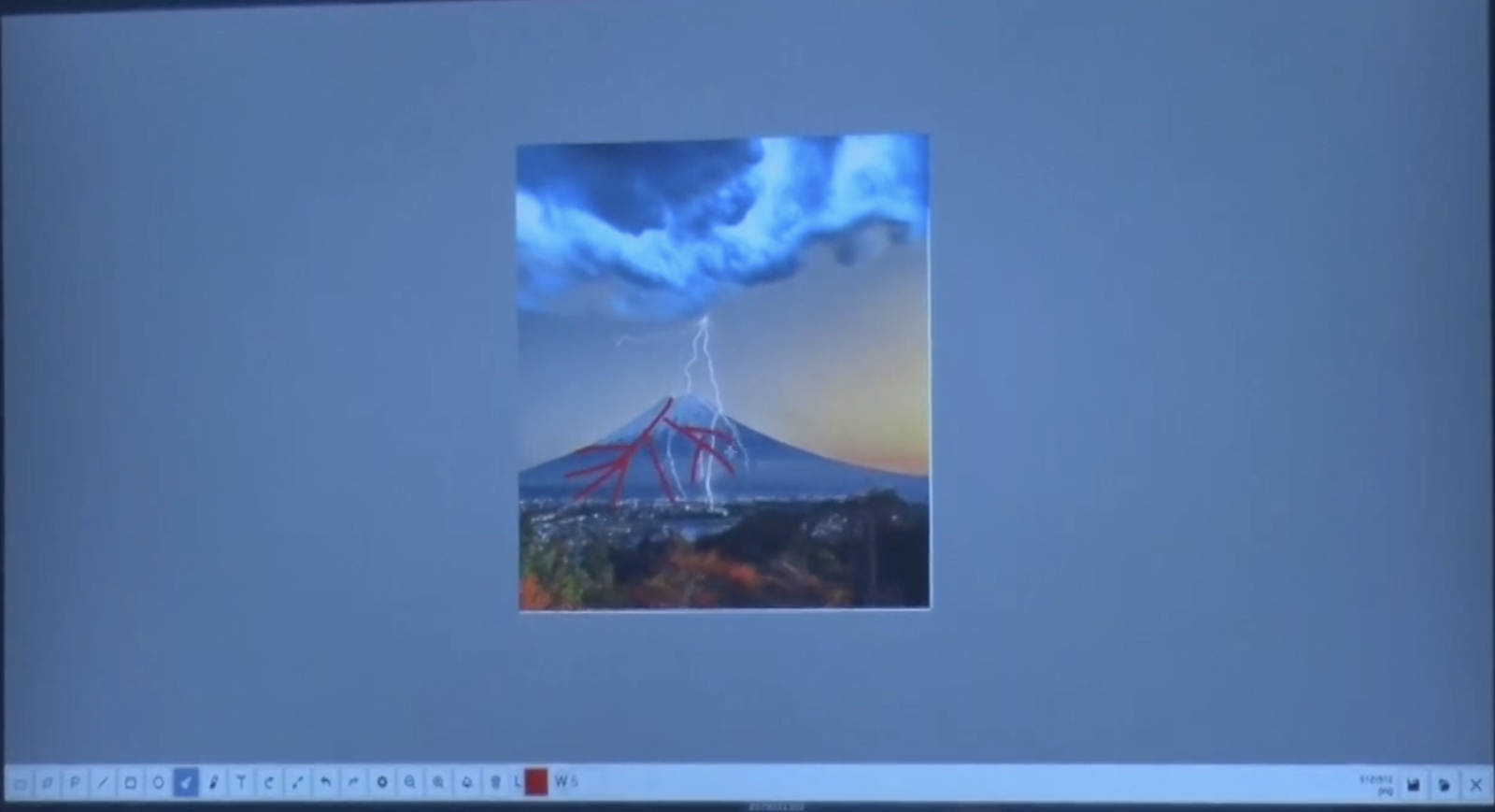
尾原 溶岩と言っているけれど、赤い色の線は溶岩っぽいだろうという感じで入れてしまうんですね。
砂金 人間がやるとシャビーな感じですが、こんなイメージでちゃんと仕上げてねという指示を出すと、それっぽく仕上がります。
尾原 ああ、これは溶岩っぽい。しかもこっちまで反映してくれている、溶岩を拾って。
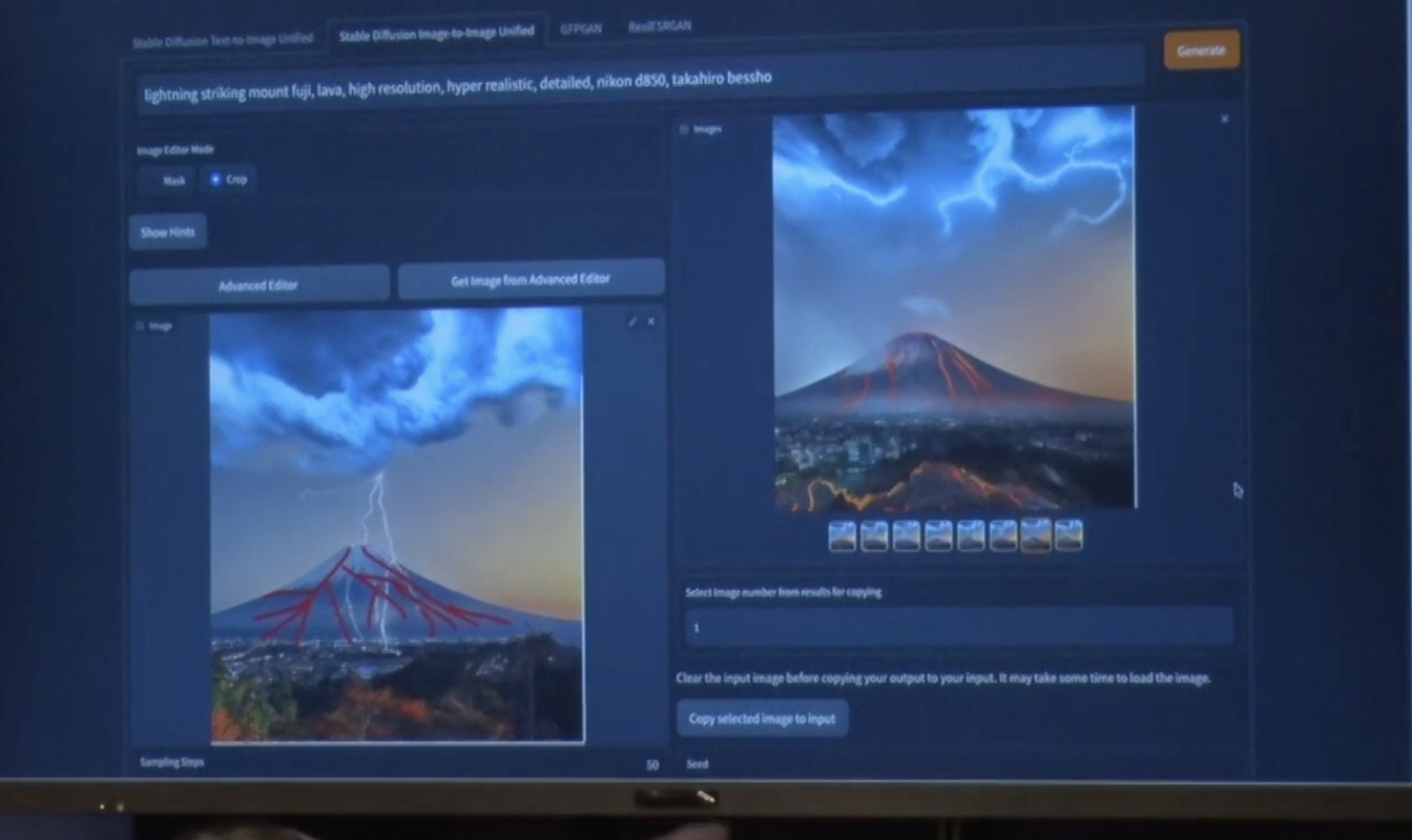
砂金 というのが、割と誰でも使えるようになりました。
これは昨日、岡田さんも含めてお話ししたのですが、お絵描きAIみたいなもので、一般のメディアでも話題になっていると思います。
この仕組み自体もすごいのですが、これを無償かつオープンソースでモデルごと提供しているのです。
尾原 そうなんですよね、モデルごと提供していますものね。
砂金 Googleはじめアメリカのいくつかの企業がAIで先行的にこういう巨大モデルを作っていたのですが、これを提供したのはドイツの大学(ルートヴィヒ・マクシミリアン大学)ですよね。
過去も含めて、ヨーロッパ圏、特にドイツの皆さんとかは、アメリカが業界のルールみたいなものを作っているところに、破壊的なテクノロジーを持ち込んで壊すみたいな(笑)。
それまでお金をかけて、大規模モデルを作ってきた人たちが、これで商売しようかなと思ったところに、無償提供するということが、画像の世界では起こりました。
(続)
【本セッション記事一覧】
- AIの開発に関わるトップランナーたちが集結したシーズン3!
- 「人流データ」から、何がどこまでわかるのか?
- Googleマップの薄い青い円はデータの誤差! 高精度のAIに必要なものとは
- 取得データが多すぎる問題にどう対処する? unerryが上場した目的
- 全国254万箇所の来店検知で「行動DNA」が丸わかり
- 動的データで、人のペルソナ分類から半導体出荷量予測まで明らかに
- イメージと手描きでリアルな画像生成、話題の画像生成AI「Stable Diffusion」
- 長文要約、文章生成…ここまでできる! 日本語の大規模言語モデル「HyperCLOVA」
- 日本のビジネスメールや心削られる謝罪メール、すべてAIにおまかせ
- 天才プログラマー清水 亮が指摘する「検索から生成へ」の変化
- ハイコンテクストな文化こそが参入障壁、日本の「生成系」に勝機あり!
▶新着記事を公式LINEでお知らせしています。友だち申請はこちらから!
▶ICCの動画コンテンツも充実! YouTubeチャンネルの登録はこちらから!
編集チーム:小林 雅/小林 弘美/浅郷 浩子/戸田 秀成