
▶新着記事を公式LINEでお知らせしています。友だち申請はこちらから!
▶ICCの動画コンテンツも充実! YouTubeチャンネルの登録はこちらから!
ICC KYOTO 2022のセッション「AIの最新ソリューションや技術トレンドを徹底解説(シーズン3)」、全11回の⑦は、LINE砂金 信一郎さんが、話題を集めている日本語の巨大AI言語モデル「HyperCLOVA」について解説。そもそもLINEがなぜこれを作っているのか、一体どんなことができるのかを、デモで実演します。ぜひご覧ください!
ICCサミットは「ともに学び、ともに産業を創る。」ための場です。そして参加者同士が朝から晩まで真剣に議論し、学び合うエクストリーム・カンファレンスです。 次回ICCサミット FUKUOKA 2023は、2023年2月13日〜2月16日 福岡市での開催を予定しております。参加登録は公式ページをご覧ください。
本セッションは、ICCサミット KYOTO 2022 プレミアム・スポンサーのリブ・コンサルティングにサポート頂きました。
▼
【登壇者情報】
2022年9月5〜8日開催
ICC KYOTO 2022
Session 11G
AIの最新ソリューションや技術トレンドを徹底解説(シーズン3)
Supported by リブ・コンサルティング
▶「AIの最新ソリューションや技術トレンドを徹底解説(シーズン3)」の配信済み記事一覧
日本語に特化した大規模言語モデル「HyperCLOVA」

砂金 今日お話しするHyperCLOVA(ハイパークローバ)は、テキスト側の技術ですが、GoogleがPaLM(AI言語モデル)を無料で公開したら、我々は軽く死ねるなみたいなことがあるのですけれども(笑)。
▶”ジョークを理解するAI”をGoogleが開発! 5400億パラメータの言語モデル「PaLM」(ナゾロジー)
先ほど(Part.4参照)GCP(Google Cloud Platform)などを使いながらみたいなお話もありましたが、やると無限にGPU代と電気代がかかります。
尾原 そうですよね、むちゃくちゃかかりますよね。
砂金 今我々が作っているのは、パラメータ数で言うと、820億パラメータぐらいの日本語モデルですが、学習に1カ月とか、かかります。
「しょぼいGPUでやっているんですか?」と聞かれそうですが、これはNVIDIA社のSuperPODという、純正のA100というGPUがついたものを、InfiniBandといって、複数台に分けないとメモリーに載らないので、それを効率的に動かすような仕組みを全部含めて、結構な金額のGPU投資をして作っているのが現状です。
これは、本当に我々も頑張っているのですが、NVIDIAのアーキテクチャからどうやって脱却できるかは業界全体に結構動きがあります。
Googleさんは自分たちでプロセッサーを作って、さすがだなとは思うのですが、私の今使っているこのラップトップもゲーミングPCで、2060のGPUがついているので、先ほどのStable Diffusionや、我々がやっている音声合成や音声認識のモデルなどは、自分のPCの中で、遅いけれどギリギリ動くみたいな状況は作りながら日々やっています。
NVIDIAに気づかないうちに支配されているみたいな状況から脱却すべく、今GraphcoreやSambaNovaなど、いくつかのプレイヤーがGPUではないけれど、GoogleのTPU(Tensor Processing Unit)のようなAIのモデルを作るのに専用特化したCPUみたいなものを開発しています。
それが出てくるのをすごく心待ちにしていますが、今のところ非常に高額なGPUを使わないとできないので、それでやっています。
なぜLINEはHyperCLOVAを開発するのか
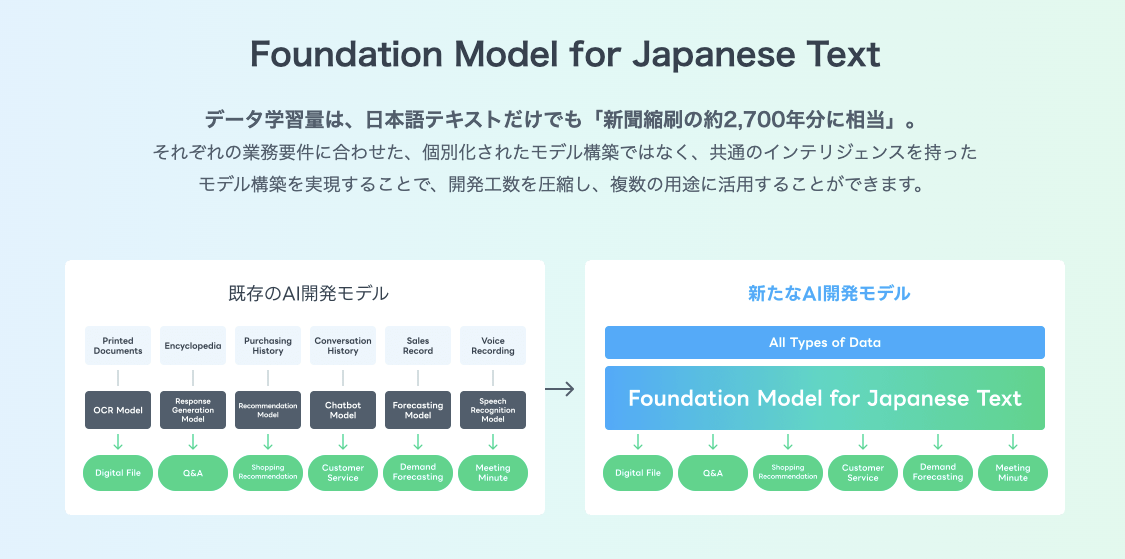
砂金 我々は、HyperCLOVAを発表してから今に至るのですが、なぜそもそも大規模言語モデルを作っているのか、お話します。

上記画像のテキストはこちら:
▶LINE、NAVERと共同で、世界初、日本語に特化した超巨大言語モデルを開発 新規開発不要で、対話や翻訳などさまざまな日本語AIの生成を可能に 2020.11.25(LINE)
尾原 それは非常に大事な話です。
砂金 すごくシンプルに言うと、OpenAIという会社・団体がGPT-3なるものを開発しました。
GPT-2もあったし、そこそこ使えていましたが、GPT-3は桁違いのレベルです。
先ほどのStable Diffusionは日本でお絵描きAIみたいな感じになっていますが、作文ができるAIをGPT-3が作って、ブログというかコメントというか分かりませんが、人間が書いたのではなくて、AIが書いたものにもかかわらず、非常に高い評価になりました。
これはもうすでに使える状態にあるんじゃないか(英語では)、というのがあって、日本語はどうするかみたいな話があります。
尾原 そうなんですよね、日本語環境が置いていかれちゃうんですよね。
砂金 日本語を入れたらそこそこのものが返ってくるし、よくある皆さんの今の利用パターンでいうと、DeepLのような生成系の翻訳とGPT-3の英語版を合わせて使うのが、割とよくあるパターンかなとは思います。
やはりネイティブにしないと難しいなと、昨夜盛り上がった例の話があるのですが、マイクを通して言うのはやめます。
日本語とか中国語とかタイ語とか韓国語とか、そういう話ではなくて、歴史認識などを含む話なので、英語のモデルが一個あればいいんだという話ではない、というのが今のところの我々の認識です。
尾原 そうなんですよね、単なる言葉を理解するだけではなくて、文脈を理解するというところがありますからね。
砂金 はい。なぜLINEがHyperCLOVAを作ることに決めたのかというと、これを作らないと我々の言語処理の開発エンジニア、リサーチャー、モデラーが足りないのです。
先ほどの画像認識や音声認識のような、それぞれに特化したモデルを作って、それぞれ言語処理が絡むので、それ用にエンジニアを張ってやっていますが、個別特化、ファインチューニングしたものをたくさん作るみたいなやり方は、もう無理です。
そこで、1個すごい賢い常識を持ったものがあれば、後はそこに味付けをするだけで、エンジニアではないプランナーみたいな人たちでも、ノーコードで操作できるようになると、結構面白いことになるんじゃないか? あるいは事業として、それが必要だぞと、HyperCLOVAなるものを作りました。
尾原 これは新しい資本主義の起草と言ってもいいですよ。
砂金 普段は事前に録画したスクショでプレゼンしているのですが、今日はせっかくなのでこの場でデモをします。
尾原 お絵描きのAIも、基礎となるどういうテキストを入れればどういう絵を作れるかとか、この絵を解釈し直して、もう1回絵にするとどうなるかということは、膨大なモデルが必要です。
絵はまだ共通なのですが、言語においては日本語環境だと特殊すぎて、なかなか日本的なものの発達を遅らせる可能性があります。
だから、そこをきちんとやってくださるのは、非常に日本のためになるわけです。
日本語文章の要約をAIが生成

砂金 実際使ってみましょう。
デモアプリなので、このままの状態で世の中に出すわけでもないし、現時点で皆さんがアクセスして使えるわけでもないですが、我々が社内でどんなことを実験的にやっているのか見ていただきたいと思います。
できることは、テキストの生成です。
画像ではなくて、文章の生成、作文をしますので、どんなことができるのか、いくつかメニューが並んでいます。
尾原 アメリカなどでは、(AIが)ニュースサイトに文章を作ってしまったら、プロの記者でも本物のニュースと区別がつかないぐらい、英語では文章構成が作れたりしているわけです。
砂金 これは要約するという、昔からある日本語のタスクではありますが、ちょっと長めの文章です。
▶編集注:当日は砂金さんが長いニュース記事を使って実演しましたが、上記の映像は事前録画ずみの映像です。
尾原 長いなあ。
砂金 文字も小さいし、日本語を読もうとすると結構大変、面倒だなというので、3行に要約します。
尾原 あっ、結構分かりやすい。
砂金 キーワードを取ってきてツギハギするのではなく、この文章は要するにどういう内容だったんですか?というのを、改めて作文をしているんですね。
だから人間がやっていることに割と近いと思いますが、1回読む、コンテクスト(文脈)、事実を把握する、それに基づいてこの文字数の中で表現するにはどうしたらいいかを、作家先生お二人(尾原さん、清水さん)は日々やられていると思いますが、その作業をAI的に代替します。
もう少し技術的に言うと、なめらかに見える文章をどのように作っているのかというと…
尾原 そうですよね、多段階でやっているわけですよね。
砂金 結局は、この単語の次にこの単語が来ると、日本語としてはなめらかである、自然であるということを事前に学習して統計的に行っている処理なので、変な文章にはならないんじゃないかなとは思います。
例えば、LINE的にはどうするかというと、LINE NEWSやYahoo!ニュースとか、3行要約とか。
どういう見出しにすると、CTR(クリック率)が高いみたいなことは職人的にやります。
今、デモでは1パターンしか作っていませんが、AIだと疲れないので無限に生成します。
とりあえず1,000パターン作ってと指示を出すと作ってくれて、その中から、人間が目検で見て判定してもいいのですが、CTRが取れるので、ABテストを1,000パターンやったりできます。
尾原 ABテストをやって、一番クリック率の高いものとか、次のニュースまで読んでくれるものをとか、色々な形で最適化もできてしまいますからね。
砂金 それができると、我々はさらにそれを学習データに使えるので、人間様はこういう文章を読むとなんか興味を持つらしいぞということが、ある種の正解データ、要約内容として正しいかどうか分からないけれども、ニュースサイトとして興味を引くぞというバイアスが入った状態の学習データとしては取れるので、結構面白いなと思っています。
尾原 しかもここまでAIが自動化できると、マーケティングが180°変わるという話があって、今までのABテストは、1種類のものでたくさんの人に効率良く取るためのマーケティングでした。
でも、こういうふうに生成系ができると、清水 亮さんが響く表現は何かとか、内山さんが響く表現は何かというふうに、百人百様にすることもできます。
そうなると、そもそも、そのセグメントをジェンダーで切ったほうがいいのか、ライフサイクルで切ったほうがいいのかとか、もっと言うと内山さんの会社のサービスと掛け算すると、こういう来店をした時に響く文章はどうなんだみたいなことができます。
実はAIの生成モデルの破壊力というのは、最適化というものが百人百様の100タイミングのものに変わるところが、際立っているところなんですよね。
尾原 日本語でこのレベルをやってくれると、想像以上だわ。
商品説明文を何万通りも生成
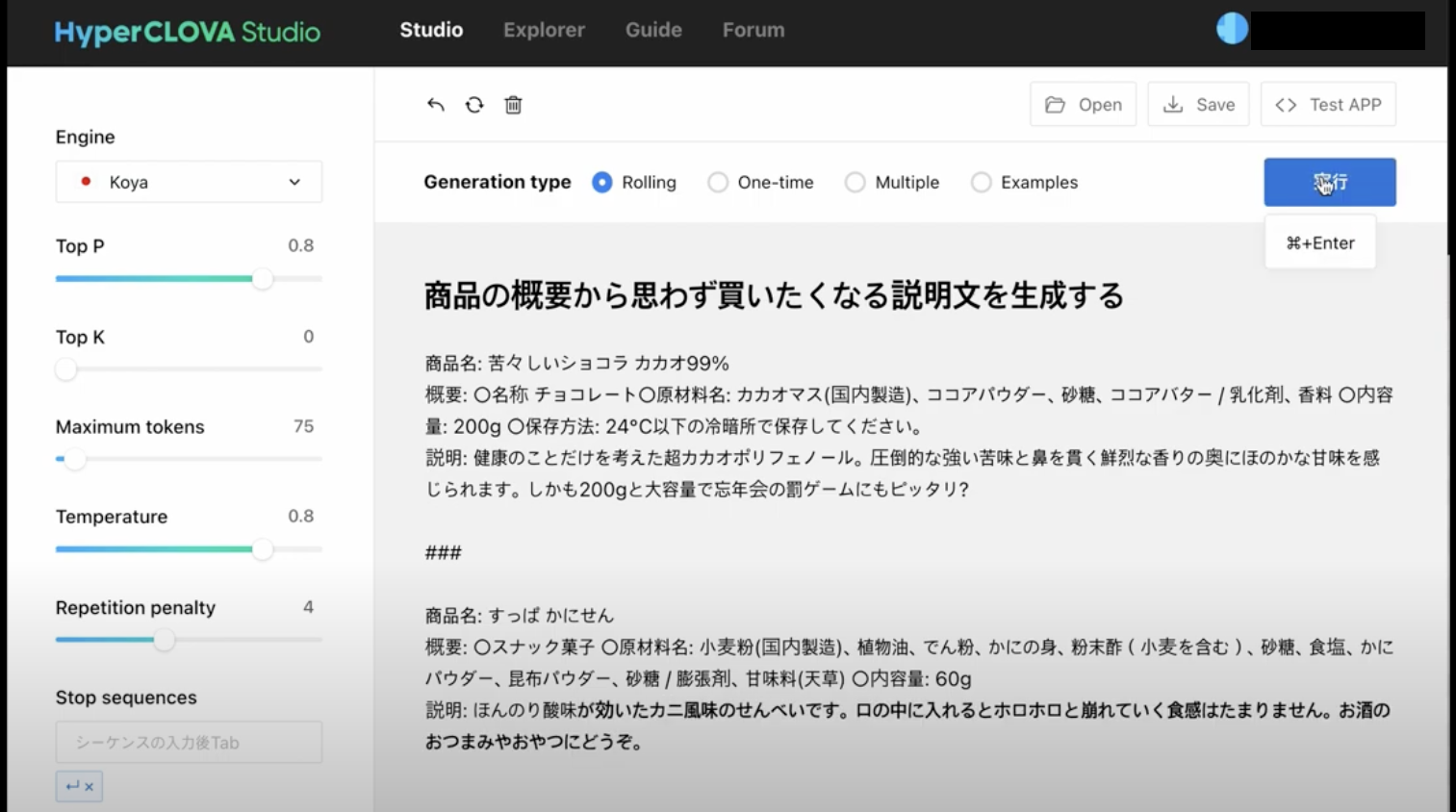
砂金 これは我々が今やりつつあることです。
ECサイトなどで、商品の説明文がありますよね。
LINEの公式アカウントで言うと、プッシュ通知で広告的なメッセージを配信するのですが、製品として、元はこういう商品ですというメタデータがあって、ターゲットとしているのは、「すっぱかにせん」と書いてある、こちらの商品をどういうふうに商品説明文として生成すると良さそうかということです。
一発目に今出てきたのは、「カニ風味のせんべいです、さっぱりした酸味が特徴です。」ですが、文章がちょっとさっぱりしすぎています。
左側で今パラメータを変えていますが、表現の自由度を変えられます。
今、もう少し表現豊かにしてみてというふうに何回か行っていますが、あんまりパッとしないので、「reputation penalty」を調整します。
「reputation penalty」というのは、こういうことやるとだめだよ、この単語の次にこの単語を出すとあまり良くないよみたいなことを、AIで指示を出しています。
「ほんのり酸味」というのは良かったけれど、その後に続く文章はこういうのがいいんじゃないかというのを今出力しました。
人間に「こんなの全然だめだ、やり直し!」と言うと、ふてくされてそのうち会社を辞めてしまうと思いますが(笑)、AIなので何回やれと言っても平気で、何万回でもできます。
先ほど尾原さんが言っていた、これをパーソナライズしようみたいな話が入ってくると、さらに可能性はあります。
先ほどのunerryさんの説明(Part.6参照)の中に、ペルソナがありましたよね。
ペルソナの中で言うと、40代女性でスキンケアにすごく強い課題意識がある人にコスメの広告を打ちましょうみたいな時には、そういう刺さり方をするような作文をしてねと指示を出すと、それも生成できます。
パーソナライズの文脈と生成系が一緒になると結構面白いことが起こってくるんじゃないかなとは思っています。
尾原 しかも今の「口の中に入れるとホロホロと」といった元のデータの中にない表現も、おそらく小麦粉とでん粉という生成から出た時に、世の中でどういう表現をされているかというモデルの中から持ってくるわけですよね。
砂金 そうです。
尾原 こういうことを考えるのがコピーライターの妙味だったりするわけですが、AIが世の中で売れるキャッチコピーを勝手にモデル生成しているので、拾ってくるわけですよね。
だから、世の中のキャッチコピーを勝手に学習していきながら、最新のキャッチコピーでこういう説明文が生成されるわけなんですよね。
砂金 これをこの後どう発展させていけるかでいうと、我々はある種のCTR(クリック率)で正解データが分かります。
それが良い文章かどうかは分からないけれども、ユーザーの反応があった、じゃあそっちの方向に強化していこうということはできます。
逆にクリエイティブな人たち、コピーライターの皆さんは、過去に作った自分の作品やボツ案も含めて、色々なデータをお持ちです。
それでチューニングをすると、この人っぽい表現…、コピーライターさんは、それぞれ著名な方は、個人の名前でやられていますが、この人のテイストを生かしつつ、この商品やこのブランドのコピーライティングをしたらどうなるんですかみたいなことは、お絵描きアプリ(Part.7参照)と似たような話です。
尾原 お絵描きアプリも、ピカソ風と入れるとちゃんとピカソ風にしてくれるように、糸井 重里風と入れるとそうしてくれるような。
砂金 我々で言うとウェブクローラーなども含めて学習データをクレンジングして作っているのですが、多分コピーライティングも採用された作品しか出ないんですよ。
おそらく創作の過程においては、これはだめだとかあるので、そういうデータをお持ちだとすごくいい感じの言語モデルを作れる可能性が高いです。
尾原 要は何を選択しなかったかというところに嗜好性は表れるので、そういう意味では企業側の内部に、使う手前にあるデータみたいなところをベースにラーニングすると、よりその会社らしい文章みたいなものができるみたいなことですね。
砂金 そうです。
(続)
【本セッション記事一覧】
- AIの開発に関わるトップランナーたちが集結したシーズン3!
- 「人流データ」から、何がどこまでわかるのか?
- Googleマップの薄い青い円はデータの誤差! 高精度のAIに必要なものとは
- 取得データが多すぎる問題にどう対処する? unerryが上場した目的
- 全国254万箇所の来店検知で「行動DNA」が丸わかり
- 動的データで、人のペルソナ分類から半導体出荷量予測まで明らかに
- イメージと手描きでリアルな画像生成、話題の画像生成AI「Stable Diffusion」
- 長文要約、文章生成…ここまでできる! 日本語の大規模言語モデル「HyperCLOVA」
- 日本のビジネスメールや心削られる謝罪メール、すべてAIにおまかせ
- 天才プログラマー清水 亮が指摘する「検索から生成へ」の変化
- ハイコンテクストな文化こそが参入障壁、日本の「生成系」に勝機あり!
▶新着記事を公式LINEでお知らせしています。友だち申請はこちらから!
▶ICCの動画コンテンツも充実! YouTubeチャンネルの登録はこちらから!
編集チーム:小林 雅/小林 弘美/浅郷 浩子/戸田 秀成