
▶新着記事を公式LINEでお知らせしています。友だち申請はこちらから!
▶ICCの動画コンテンツも充実! YouTubeチャンネルの登録はこちらから!
ICC KYOTO 2022のセッション「AIの最新ソリューションや技術トレンドを徹底解説(シーズン3)」、全11回の⑦は、ビジネスマンも使えるツールをLINE砂金さんが紹介。無料で使える議事録アプリの人間より賢い!?要約を実演します。気軽な話し言葉の入力で、かしこまったビジネスメールを生成する精度は驚くばかりです。ぜひご覧ください!
ICCサミットは「ともに学び、ともに産業を創る。」ための場です。そして参加者同士が朝から晩まで真剣に議論し、学び合うエクストリーム・カンファレンスです。 次回ICCサミット FUKUOKA 2023は、2023年2月13日〜2月16日 福岡市での開催を予定しております。参加登録は公式ページをご覧ください。
本セッションは、ICCサミット KYOTO 2022 プレミアム・スポンサーのリブ・コンサルティングにサポート頂きました。
▼
【登壇者情報】
2022年9月5〜8日開催
ICC KYOTO 2022
Session 11G
AIの最新ソリューションや技術トレンドを徹底解説(シーズン3)
Supported by リブ・コンサルティング
▶「AIの最新ソリューションや技術トレンドを徹底解説(シーズン3)」の配信済み記事一覧
文章を要約し議事録を生成

砂金 もうちょっと実務的なものをお見せします。
我々はこの議事録アプリ「CLOVA Note」を無料で出しているので、お使いいただければと思います。
コンサル会社などでは、とりあえずジュニアコンサル、アソシエイトが最初にやらされる仕事は議事録みたいなことがあると思いますが、できない子はだいたい「何々さんがこう発言しました」みたいなひどい議事録を書いて、そういうことじゃないんだよと先輩に怒られます(笑)。
(一同笑)
これは会話のログですが、右側のフォーマットで、AI側がある種規定をしています。
どういう話をしていたんですか?(議題)、何が決まったんですか?(決定事項)、次のアクションは何をしないといけないんですか?(次のアクション)を、左の会話ログの中から読み解きます。

尾原 せいの、ドン!
砂金 そうすると、端的に言うと、こういう話をしていましたというのが出ました。
そんなにずれていないですよね。
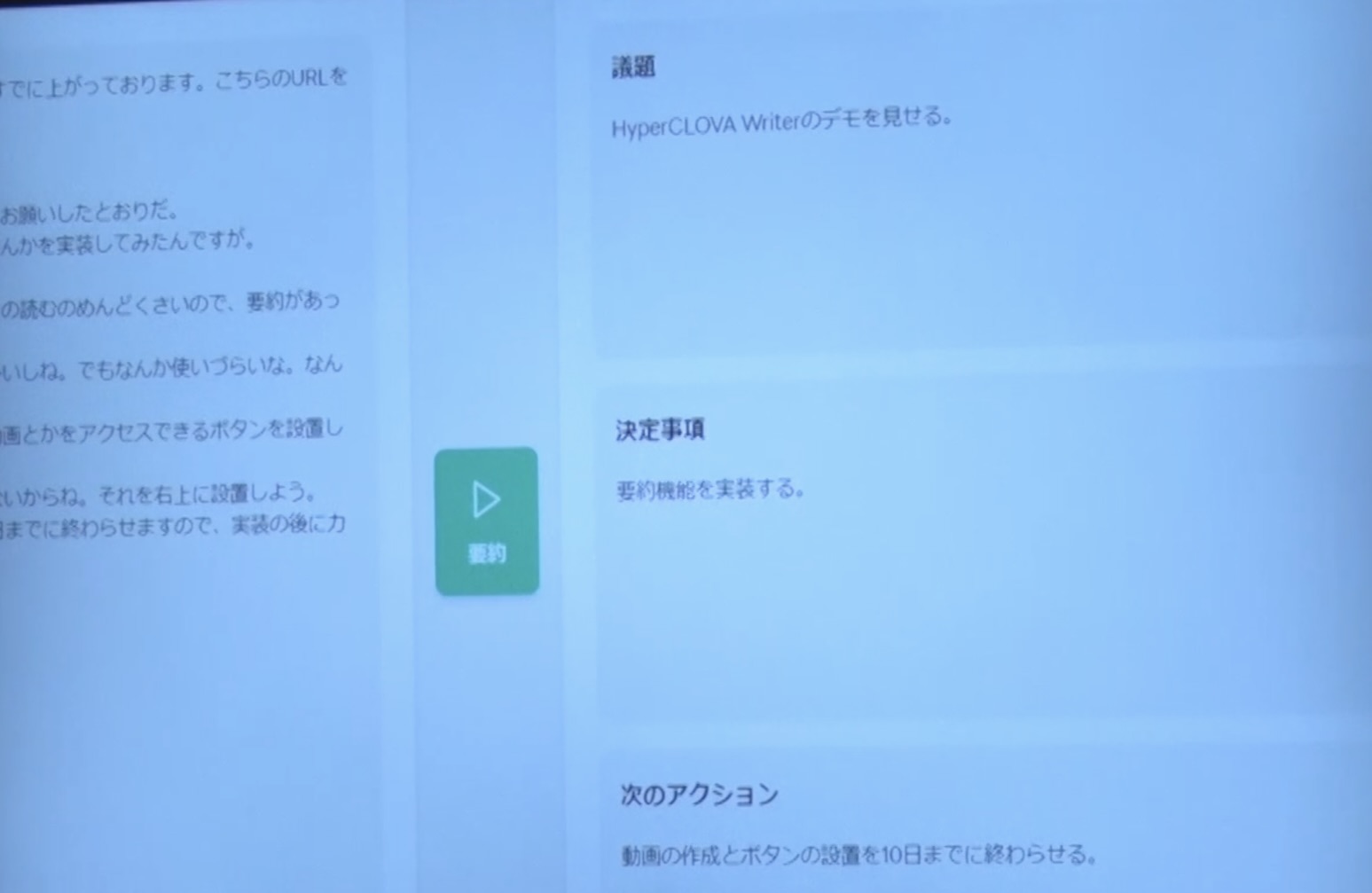
HyperCLOVA Writerのデモを見せるという話をしていました、要約機能が良さそうだから、実装することが決まりました、いつまでに何をするなど、要約されています。
どうやっているかというと、先ほどの「すっぱかにせん」の商品説明文を作っていたのと同じです。
皆さん、算数や数学、国語でもいいのですが、例題を解いて本題みたいな昔からの教科書があるじゃないですか。
「Few-shot Learning」と言いますが、生成系のAIに対して、人間だったらこういう状況でこうします、こういう状況の時はこうしますといくつかサンプルを示した上で、じゃあ本題です、このログはAIだったらどういうふうにまとめますか?とやらせると、結構解けるんですね。
そこの部分に関しては、もう割と使える状態にあります。
変換間違いの校正も得意
砂金 要約ができるということは、これはありがちなパターンですが、この文章は日本語としてどこが間違っているでしょうか?
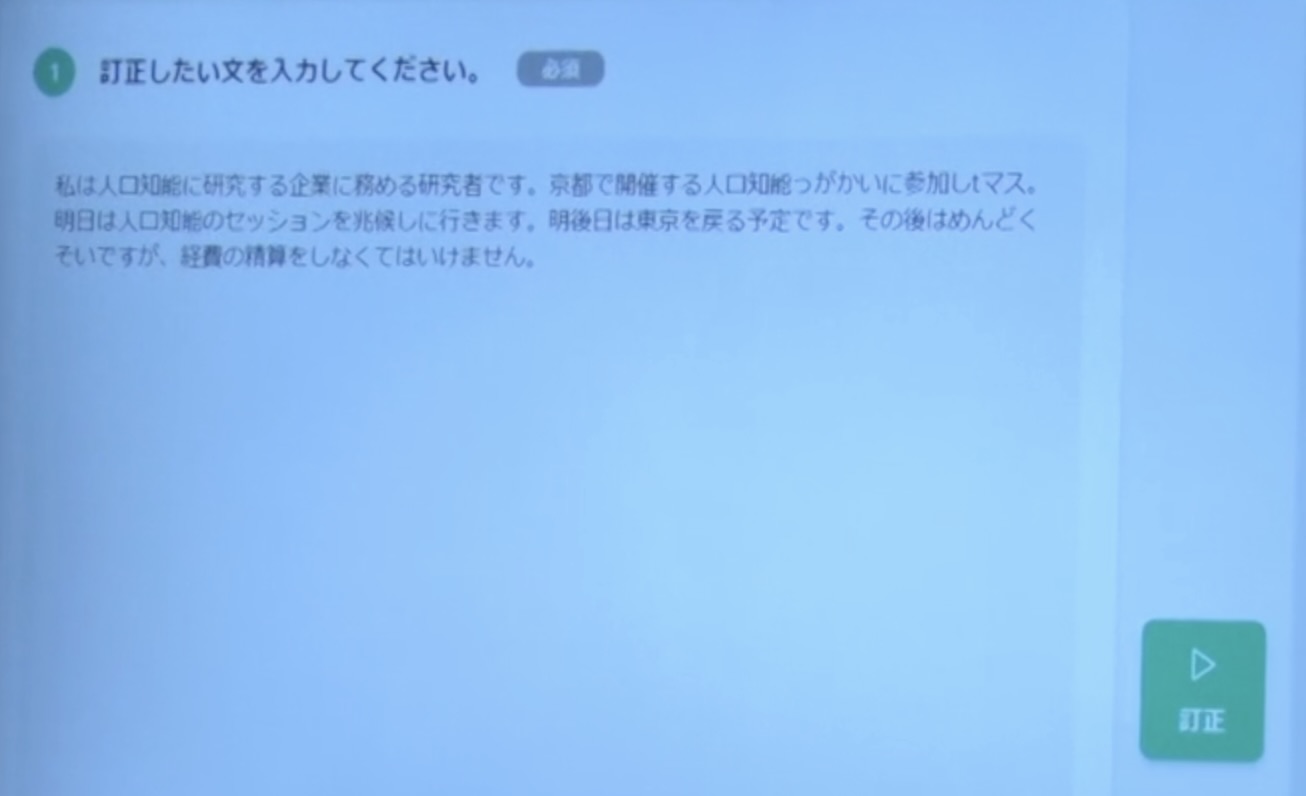
後ろのほうの方はちょっと読めないかもしれないですが、「人工知能」が「人口知能」となっていて、漢字が間違っていますよね。
「聴講しに行きます」というのも、頭の悪い漢字変換になっているのですが、意外と人間は気づきません。
気づかないのですが、先ほど私が説明した通り、AIは言葉の並びをちゃんと自分で制御できるので、こういうことをあなたは言いたいんですよねと、その部分を補正してくれます。
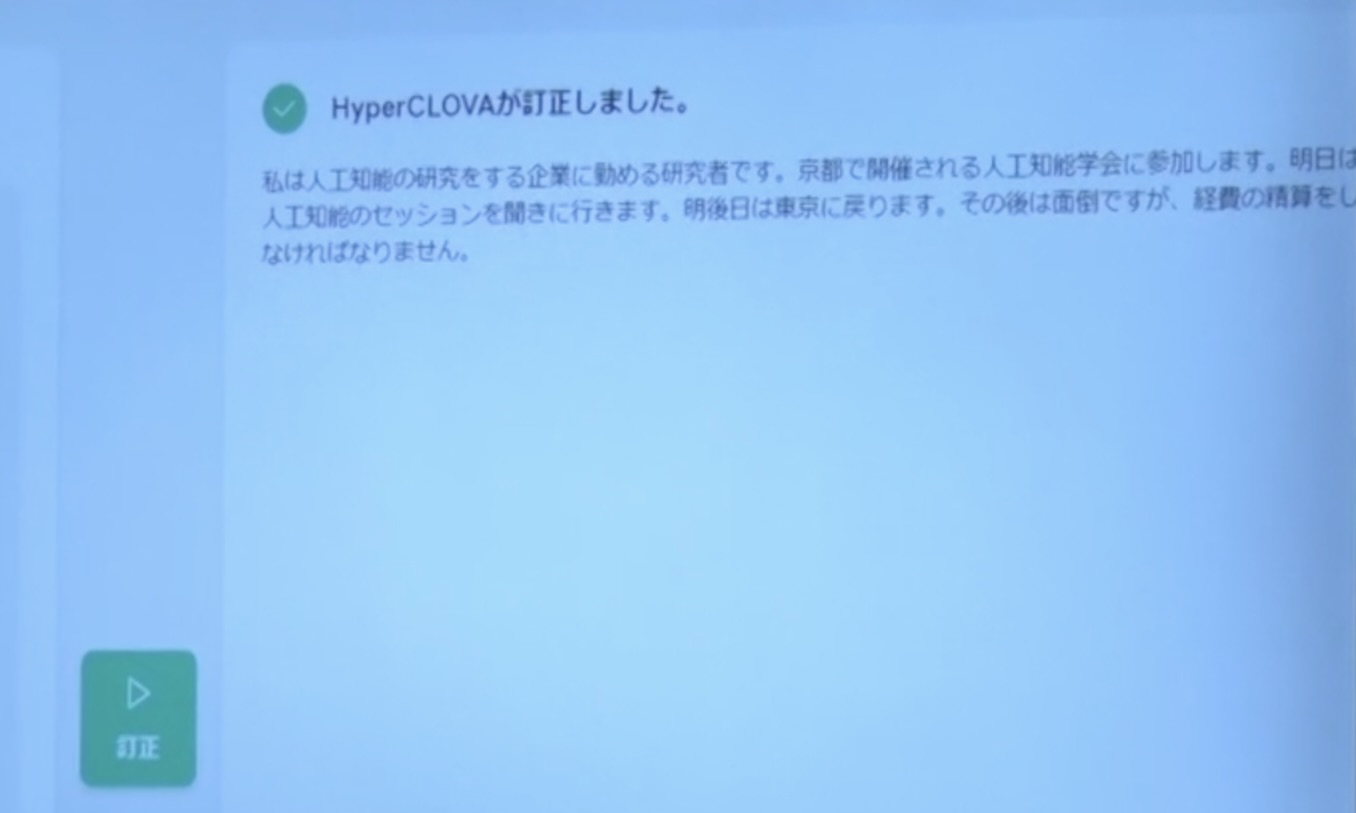
本来、あなたはこういうふうに表現したかったはずと言葉の並びの統計的には思われるが、これで正しいですか?と、生成系のAIの中ではちゃんとできたりします。
文章校正ツールですね。
気軽な話し言葉をもとにビジネスメール文を生成
砂金 次に、まだ我々も社内で使っているわけではないのですが、もうちょっと実務的なものをお見せします。
我々は仕事で使う業務用のメールにLINEを使ってはいけないのですが、LINE WORKSやSlackも含めて、チャットツールでよろしくみたいな感じで、カジュアルに連絡をしています。
そうすると、かしこまった作文をするのは結構面倒くさいみたいな方々がいて、要するにクローズドβテストを始めるよ、使ってみてねみたいな話をメールで通知したいとすると、この要件をもとに生成します。

尾原 これは素晴らしいなあ!
砂金 日本で企業の中で流通しているであろうEメールは、こういうふうに書くものであると。
これはテンプレートではないので、生成すると毎回違うものが出てきます。
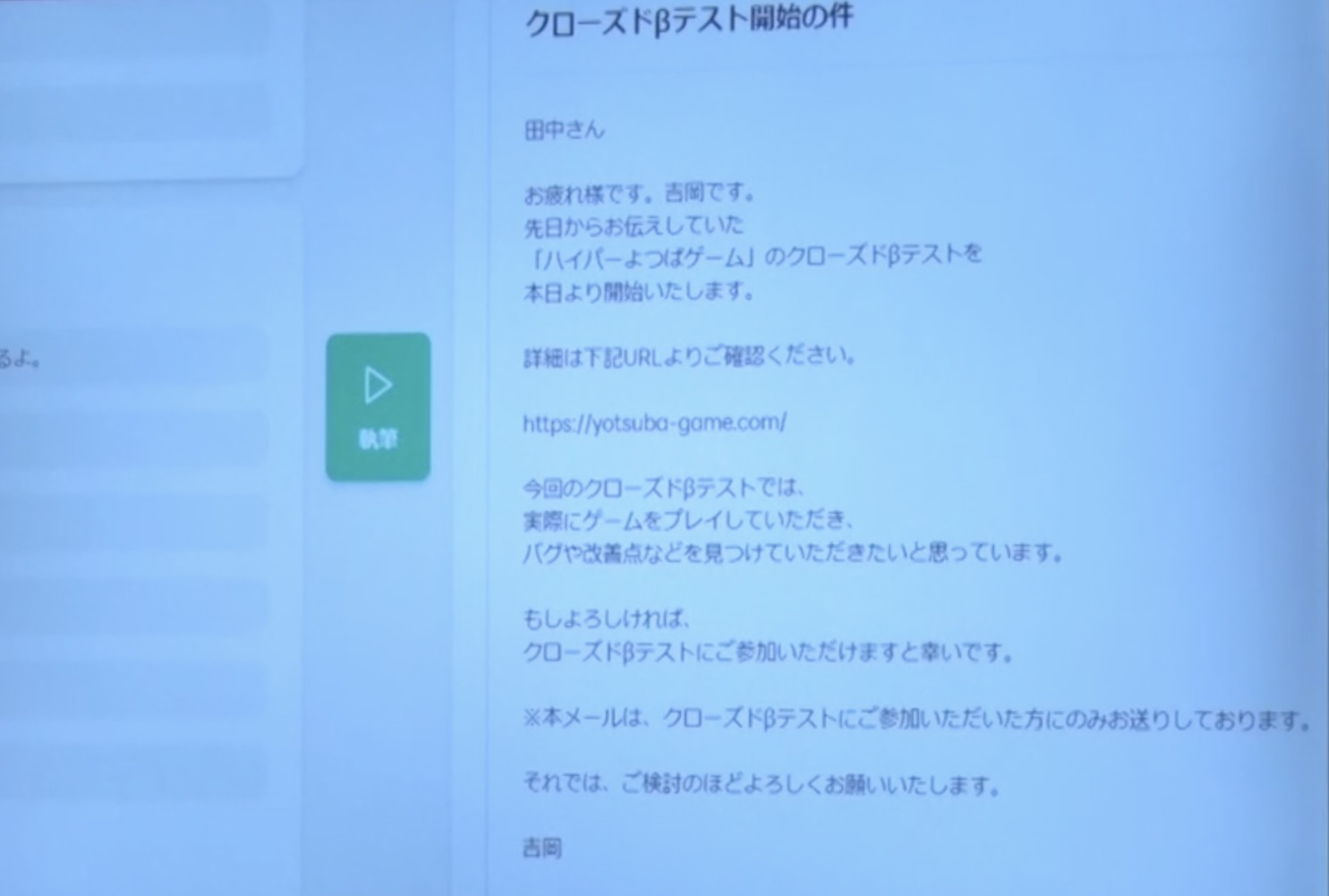
清水 これでマネー交渉の仕事がなくなりますね。
(会場笑)
尾原 大事なのは、パターンを覚えさせるだけではなくて、生成しているわけですよ。
ということは逆に、日本語のメールはこういうものなんだというのを、ものすごく裏側でモデルを作っていて、データ量は半端ないでしょう?
砂金 データ量はすごいですね。
一応言っておくと、先ほどセンシティブデータの話(Part.3、4参照)がありましたが、皆さんがお友達やご家族の間で会話しているLINEのトークデータはセンシティブデータの極みなので、絶対に我々は手を出さないし、怪しまれるようなこともしないです。
オープンチャットという匿名で会話ができる、昔のmixi(ミクシィ)みたいな機能もLINEのアプリに入れていて、本来で言うと、利用規約上は機械学習に使ってもいいという話にはなっているのですが、怖いから使わないです(笑)。
どうせLINEはみんなの会話を盗み見してAIを作っているんだろ?と言われると、いや、そうできたらいいですよ、ここが違う国だったらそうするかもしれませんが、それはさすがにレピュテーションリスク(企業などの評判が悪化するリスク)が高すぎます。
尾原 逆に言えば、それぐらいリスクがあるタイプのものを、本当にきれいな形で一社一社が個社で作ることはできないわけです。
だからLINEさんが、こういう何が日本語の自然な文章なのか、文章として要点にまとめる時には何がどう重要なのか、逆に行儀良いメールを書くにはどうすればいいかという基礎モデルを作ってくださっているのは本当に大事です。
なぜかというと、先ほどの絵を描くAI(Part.7参照)などはドイツや英語圏の方々や公共的な機関が割と作ってくれるのですが、日本語は固有性が高いので、なかなか難しいんですよね。
これは本当にすごいことですよね、日本のために。
心削られる謝罪メールはAIにおまかせ
砂金 そうなんですよね。
楽しく書いている文章はいいのですが、心削られるものがあるじゃないですか。
(会場笑)
こちらは、謝罪する時のメールです。
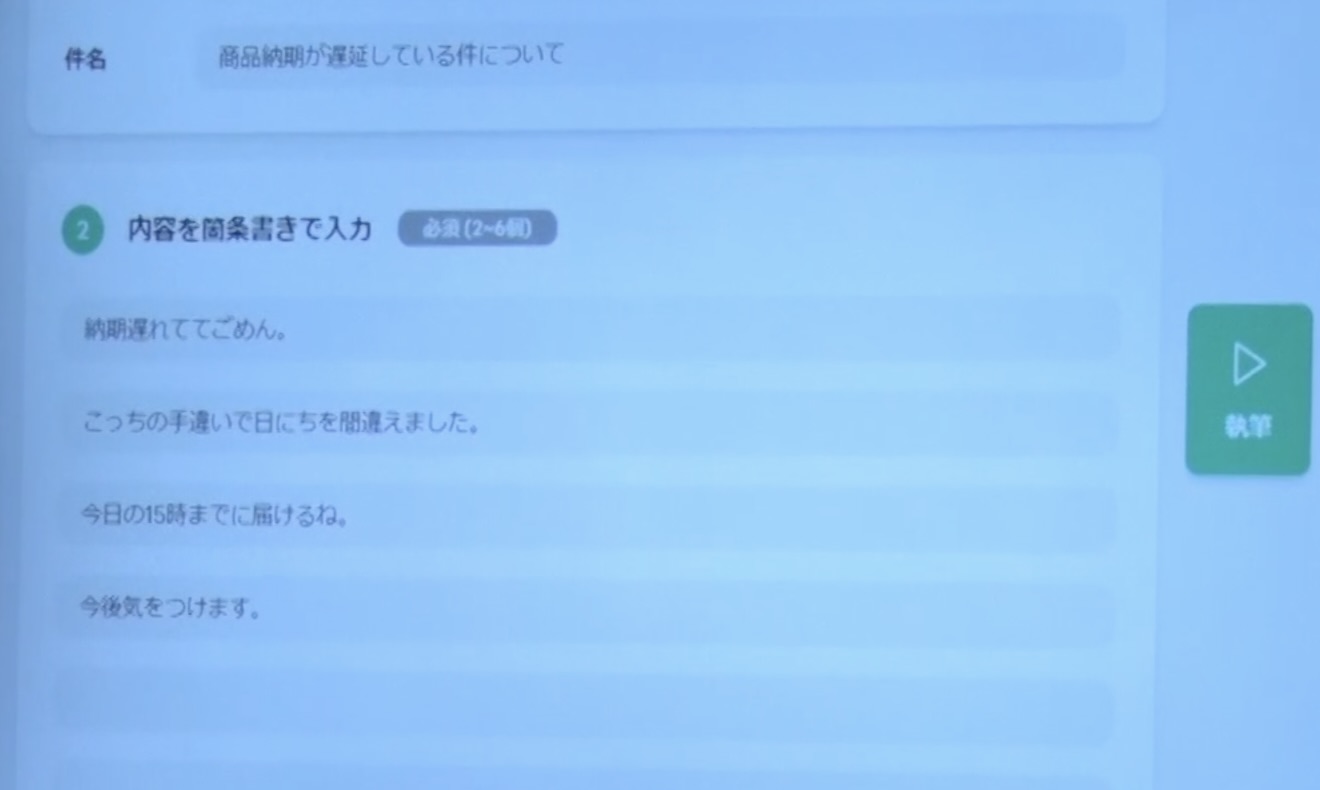
尾原 これはちょっとドキドキしますね。
砂金 納期が遅れていますみたいな。

尾原 おお~!
清水 でもこういうメールが来ても、謝っているつもりはないんだ。
(一同爆笑)
砂金 そういうことですよね(笑)。
ちなみにこのデモアプリの仕組み自体を作っている言語系のエンジニアが最初に作ったサンプルが、障害報告書の自動生成でした(笑)。
(会場笑)
内山 すごく実用的ですね。
砂金 エンジニアとして心削られるものを人間が書くより、AIに任せておけばメンタルのダメージは少ないなと。
現時点においては、最終的に心を込めたり、最後に筆を入れるみたいなところは人間がやります。
下書きをAIがしてくれて、そこに対して最後の一言を入れるみたいな、よく年賀状で印刷されているハガキに、手書きで一言入れるじゃないですか。
ああいう作業がまだ多分人間のやるべきこととしては残っていて、そこを補完してあげると、毎朝30分ぐらいかけてメール処理していた時間が5分ぐらいに短縮できて、残りの25分でちょっと面白いことができるかなと。
清水 でもこれ、危ないですよね。
結局みんなこれに頼るようになるじゃないですか。
そうすると、みんな偉い人の文章をチェックしなくなってしまって、偉い人が最後に余計な一文を加えて炎上みたいな、そういう未来が浮かんできました(笑)。

尾原 まあそこも、偉い人が一文を入れた余計な文章をサブミットしようとすると、AIが判定してくれて、その偉い人のプライドを傷つけないような、ちょっとお止めくださいという丁寧な文章もAIが自動生成してくれるとか。
(一同笑)
清水 いやあ、難しいんじゃない? ここ最近炎上している案件は、明らかに広報が働いていないものばかりじゃない? ブレーキが利いていないみたいな。
尾原 そうですね。でも究極で言えば、そういうものはプレスリリースとしてサブミットをAIが拒否する。
広報が止めると問題があるけど、AIがサブミットしないからと。
清水 プロキシー(proxy)フィルタみたいなもので、もう変なことは送信できないようになっているとかね。
砂金 生成したものの正しさは、画像もそうだし、Stable Diffusionも、配布されているほとんどのモデルは、際どい画像とかを生成しようとすると、フィルタがかかっています。
今は嗜好の多様性があるので、何が本当にだめで何がいいのかは結構微妙な線に入るのですが、我々の生成したものが、本当に安心して大丈夫なんですか? 倫理的に問題がないんですか? プライバシー的に大丈夫ですか? 人を傷つけていないですか?みたいなのは、フィルタをかけなければいけません。
今は社内で作っているサンプルデモアプリとして皆さんにお見せしましたが、世の中に出す時に何が足りないかというと、今は鉾(ほこ)、敵を衝く武器を作っているのですが、それを防御する盾も必要で、それが同時にないと暴走してしまいます。
そこで、“その仕組みをどう作るか議論”なんですが、フィルタは正しいです。
例えば、広告を自動生成にしようとした時に、広告ガイドラインがすでにあります。
ガイドラインに照らして、これはいい、これはだめ、コンプレックス商材だったり薬やダイエット食品みたいなもので、これはいい、これはだめみたいなものは厳密に決まっているので、そういうものは簡単で、フィルタすればいいのです。
ただ僕らが次にチャレンジしているのは、清水さんがまさに良いテスターだと思いますが、コイツに変な入力したら面白いこと言うぜみたいなことで、故意的に変な生成をさせようとする、クリエイティビティが異常値的に高い人がこのAIを使った時に、それでも変なことは言わせませんという仕組み自体を学習モデルの中に入れ込むということです。
尾原 そもそも組み込むということですよね。
だから今後の学習で大事なのは、問いと答えというもののセットで考えることです。
生成って何かを生成すると、必ず次の行動につながってしまうんですよね。
そうすると行動が良い時はいいけれども、悪循環すると歪みが歪みを呼ぶので、そもそも歪みを呼びやすい問いとは何なのか? 先ほどの話(Part.6参照)で言うと、歪みを呼びやすい人というのも特定できるから、じゃあ歪みを呼びやすい人がやる時には、こういう制御をかけましょうみたいなことを、それもAIで学習していくようなこともできます。
清水 あと20分しかない。2時間あっという間だった。
尾原 あっという間だね、楽しすぎるね。
(続)
【本セッション記事一覧】
- AIの開発に関わるトップランナーたちが集結したシーズン3!
- 「人流データ」から、何がどこまでわかるのか?
- Googleマップの薄い青い円はデータの誤差! 高精度のAIに必要なものとは
- 取得データが多すぎる問題にどう対処する? unerryが上場した目的
- 全国254万箇所の来店検知で「行動DNA」が丸わかり
- 動的データで、人のペルソナ分類から半導体出荷量予測まで明らかに
- イメージと手描きでリアルな画像生成、話題の画像生成AI「Stable Diffusion」
- 長文要約、文章生成…ここまでできる! 日本語の大規模言語モデル「HyperCLOVA」
- 日本のビジネスメールや心削られる謝罪メール、すべてAIにおまかせ
- 天才プログラマー清水 亮が指摘する「検索から生成へ」の変化
- ハイコンテクストな文化こそが参入障壁、日本の「生成系」に勝機あり!
▶新着記事を公式LINEでお知らせしています。友だち申請はこちらから!
▶ICCの動画コンテンツも充実! YouTubeチャンネルの登録はこちらから!
編集チーム:小林 雅/小林 弘美/浅郷 浩子/戸田 秀成