
▶新着記事を公式LINEでお知らせしています。友だち申請はこちらから!
▶ICCの動画コンテンツも充実! YouTubeチャンネルの登録はこちらから!
ICC KYOTO 2022のセッション「AIの最新ソリューションや技術トレンドを徹底解説(シーズン3)」、全11回の③は、リアルな世界をデータ化するときの努力についてから議論がスタート。ビッグデータとはいえ、目的に合ったデータを生成するにはクレンジングが必要。いかに誤差を減らしていくか、どうしても偏ってしまうデータやバイアス、センシティブなデータとは? ぜひご覧ください!
ICCサミットは「ともに学び、ともに産業を創る。」ための場です。そして参加者同士が朝から晩まで真剣に議論し、学び合うエクストリーム・カンファレンスです。 次回ICCサミット FUKUOKA 2023は、2023年2月13日〜2月16日 福岡市での開催を予定しております。参加登録は公式ページをご覧ください。
本セッションは、ICCサミット KYOTO 2022 プレミアム・スポンサーのリブ・コンサルティングにサポート頂きました。
▼
【登壇者情報】
2022年9月5〜8日開催
ICC KYOTO 2022
Session 11G
AIの最新ソリューションや技術トレンドを徹底解説(シーズン3)
Supported by リブ・コンサルティング
▶「AIの最新ソリューションや技術トレンドを徹底解説(シーズン3)」の配信済み記事一覧
移動データ解析とウェブのログ解析の違いは

砂金 ちなみに、unerryさんは個人属性側のユーザー属性推定は多分あまりしないと理解していて、それはユーザー企業側でやることだと思うのですが、設置しているBeaconが、例えばどういう商業施設に入っているのかというマスターはあるんですよね?
尾原 そうですよね。今度は場所側のパラメータという話がありますよね。
砂金 まさにそこなのです。
あと時系列というか、ずっとログ解析なので、基本はウェブのログ解析の技術というかアプローチと、このBeaconというか移動データの解析の共通点、相違点はありますか?
尾原 それは非常にいい質問ですね。
内山 こちらがすごく今のご質問の大事なところで、僕はネットの世界の人間じゃないですか。
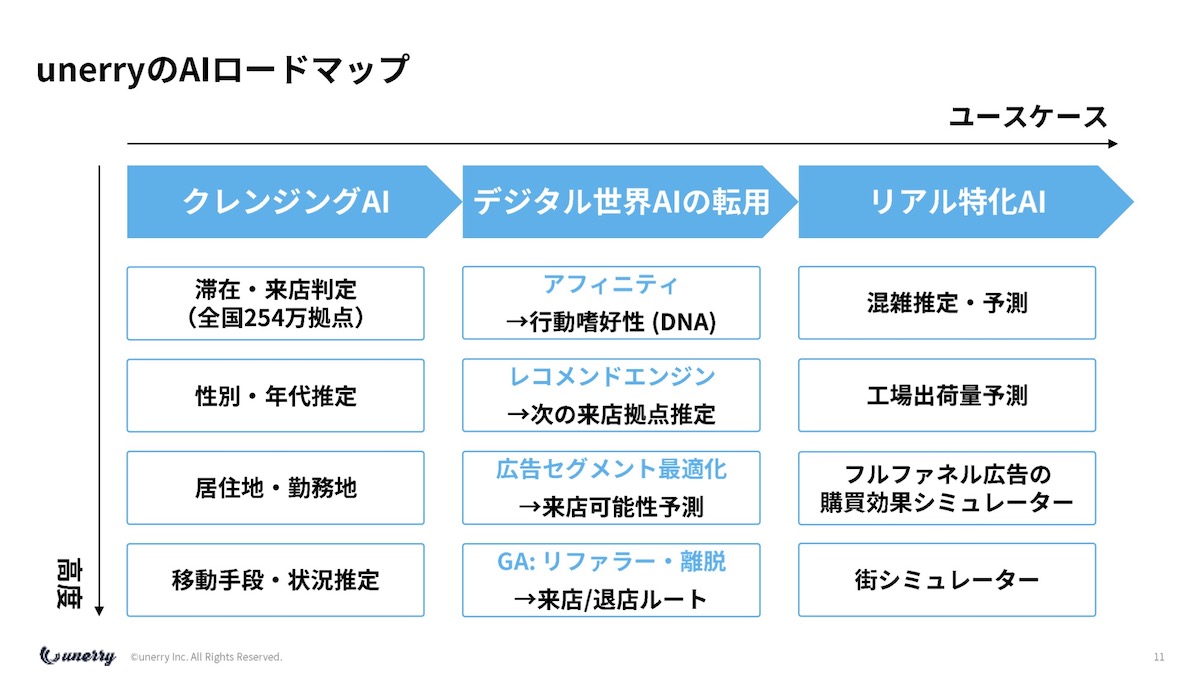
だから、端的に言うと、このデータはウェブのアクセスログと一緒なんですね。
だから、まずクレンジングする系のAIがあるのですが…
尾原 クレンジングというと、要はゴミのデータがどうしてもあるので、本当に使えるデータをどう拾おうかと、本当に大変なんです。
内山 このリアルな世界をデータ化している人はそんなにいないので、あまり研究も進んでいません。
だから、おっしゃっていただいた、デジタルの世界では当たり前にあるけれど、それをリアル版にまず転用するというところ、これは多分誰でもできます。
そういうことをやっていて、あとはリアルの特化のAIみたいなものを作っているという順番でやっています。
その一丁目一番地にあるのが、滞在来店判定なんです。
僕らだとBeaconとGPSを併用して、全国254万箇所の来店を正しく把握するというところが、一番の根幹技術に、実はなっています。
分かりやすく言うと、これだけで254万個のパラメータができるわけです。
尾原 そうですよね。
しかも来店するということは、もうある程度の購買意向がある方、アクション意向がある方ですから、かなり温度が高い方としてデータが取れていくわけですよね?
内山 その通りです。ありがとうございます。
AIはきれいなデータがないと動かない

内山 僕らのリアル行動ビッグデータの長所と短所を挙げました。

結構大変でして、先ほど動画でお見せしましたけれども、位置情報計測の誤差などが結構あります。
多分今、皆さんこの場で、スマホでGoogleマップを開いていただくと、薄い青い円が出ますが、実はそれは誤差なんです。
今この瞬間に、その端末が持っている誤差が何mあるのかが、あの薄い青い円なんですね。
それが先ほどの表に出ていた、500mみたいなデータです。
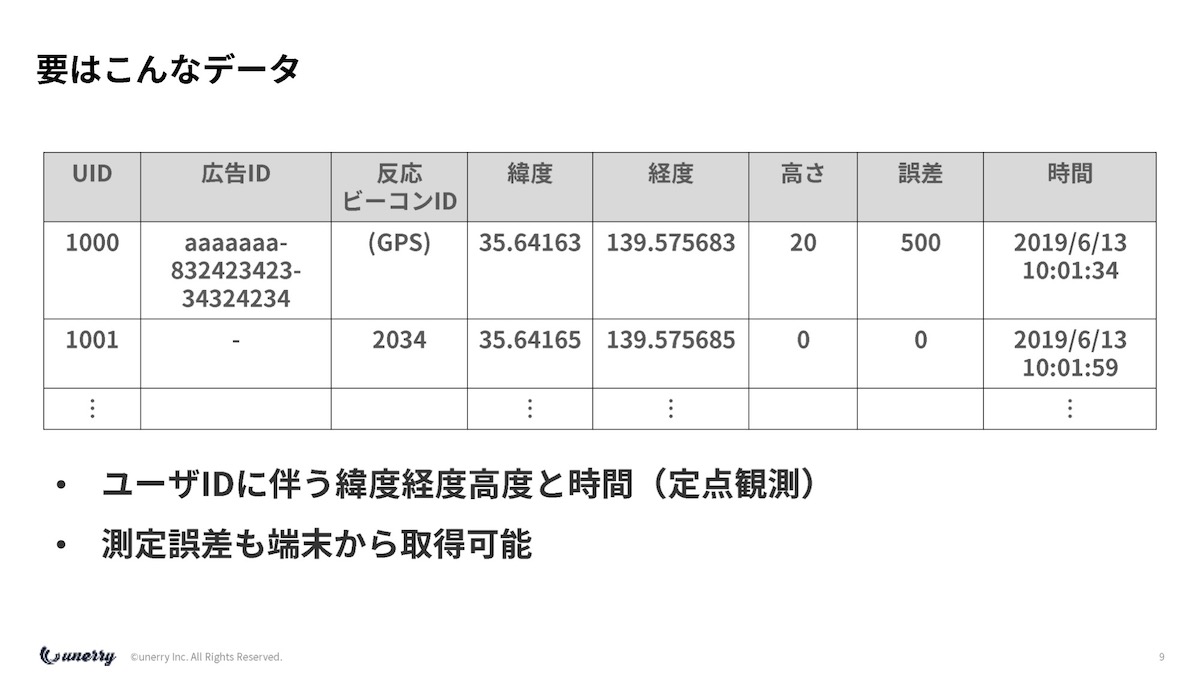
外を歩いていれば、みちびき(準天頂衛星システム)などが上がっているので、すごく精度が高いですが、今この瞬間、この会場で開くと、数百m普通にずれているデータになるのです。
尾原 なぜこういう話を僕らがやたらしたくなるかというと、AIを利用する方にお願いしたいのは、AIはきれいなデータがないと動かないのです。
このきれいなデータにするために、いかに努力しているか。
リングサイドの土田さん、どんな努力をしていますか?(笑)
土田 安紘さん(以下、土田) 僕らは画像認識をしているのですが、画像認識のデータは基本的には僕たちが思うようなものは集まって来ません。
▶リアル広告の効果測定を可能にする「エッジAI」から、人間とAIが協調する豊かな未来を目指す「AWL」(ICC FUKUOKA 2022)

▼
土田 安紘
AWL株式会社
取締役CTO
北海道勇払郡生まれ。
北海道大学大学院修士課程修了。
2001年4月に松下電器産業株式会社(現パナソニック株式会社)に入社し、NTTドコモ向け携帯電話のミドルウェア開発に従事の後、本社R&D部門にて幾つもの新規事業開発プロジェクトを牽引。その後、米国シリコンバレーでの社内起業プロジェクトリーダに抜擢され、2012年から2016年まで米国・日本市場向けのモバイルO2Oサービス事業の立ち上げを主導。
AI新時代の到来、AI活用ビジネスの最前線で業界リーダーとして”ふるさと北海道”からグローバル市場を切りひらくための挑戦の場として魅力を感じ、参画。全社技術戦略、知財戦略を統括。2019年9月に取締役就任。
▲
例えば性別、年齢を判定するような画像認識のモデルを作りたいと言って、僕がどこかの店舗の映像を使ってデータを集めようとしても、たまたまその週だけおじいちゃんとおばあちゃんしか来なかったり。
尾原 はいはい、サンプリングの問題ですね。
土田 非常にバイアスがかかってしまうようなこともあります。
単純にノイズというところだけでなく、結局僕らが使いたいデータというのはアンコントローラブルなので、その部分をどうやって水増しと言いますか、使える形にしていくかは、今時点でも生成モデルを使うなど色々あるとは思うのですが、これといったものがなくて、結局最後は試行錯誤、手作業みたいになっているケースが多いかなと思います。
尾原 そうなんですよね。
カメラでのAIの認識を実店舗でやられているAWL(アウル)さんでも、こういう感じです。
なぜこの話をしたかというと、AIをすぐ使えるというよりは、いかにきれいなデータを持ってくるかとか、目的に合ったデータをどのように生成するかみたいな工夫が大事なので、我々がついその話で盛り上がりがちなのは、理解していただければという話なんです(笑)。ごめんなさい。
内山 まさに。
尾原 これだけで3時間語れますよね。データクレンジングだけで。

内山 どれだけでもいけます(笑)。
誤差が大きいとか、あと人によって5分定点で取れている人もいれば、1分定点で取れている人もいるので、頻度のバランスの問題も結構あります。
だからというのもあるのですが、1分に1回取れている人だったら、道を歩いている間を埋めなければいけません。
例えば、1分定点で取れている人だったら直線で詰めればいいかもしれませんが、5分定点で取れている人は、どこの道を曲がったのかとか、その間に店舗を訪れたかもしれないとか、その辺の間を埋めるのも結構重要なクレンジングです。
尾原 そうですよね。
だからこの辺は、AIの発達で言えば、例えばGoogle マップは皆さん使ってくださっているので、同じ道路を動いていても、ああ、この人の動き方はバスのパターンだなとか、車に乗っているんだろうなとか、速く走っているんだろうなみたいなことを判別します。
あと最近の傾向で言うと、スマートウォッチですね。
データ側で見ると、定点でデータを上げるのが大変ですが、スマートウォッチだとローカルでデータをずっと取り続けているので、この人は走っている、この人はバスに乗っている、この人は電車に乗っているみたいなことを、スマートウォッチがローカルで1回処理して、データを渡したりと、この辺の工夫や進化は非常に色々していますからね。
内山 そうですね。
尾原 亮さん、この辺は何かやっていませんか?
清水 ん? 普通にすごい面白いなと思って聴いています。
尾原 はい、ありがとうございます。進めましょう。
清水 (笑)。普通にすごいです。
内山 ありがとうございます。
70代はアプリ経由でデータが取りにくい
内山 僕らは例えば、Shufoo!さんのような特売のチラシアプリとか、radiko(ラジコ)さんのようなラジオを聴くアプリなど、位置情報を正しく使う120個ぐらいのモバイルアプリからデータを取っているので、どうやっても70代からはデータが取れないなどのデメリットがあります。

尾原 ああ、なるほど。
内山 あと僕らは、18歳未満は原則取らないとしているので、ちょっと年齢の偏りみたいなものがあります。
清水 東カレアプリ(東カレデート)とか、そういうので取ったら、湯水のようにいいデータが(笑)。
尾原 AIの専門家がなんてことを(笑)。
そうなんだけど、一方でいわゆるセンシティブデータという……、なんか僕、今日守りの話ばかりしているんだけど(笑)、一般的にやはりこういったものって、行動だけでだめなものをあぶり出してしまう時もあるわけですよね。
結局、ある病院に行っていたらそういうことだよねとか、深夜にあるエリアに行っていたらそういうことだよねとか。
そういうものに関しては、これもまた欧州の事例が多くなってしまいますが、いわゆるセンシティブデータという言い方をしています。
元々のセンシティブデータは、この人は病気を持っているなどの属性データで、そこはタッチしては絶対にいけないのです。あそこに行ったらとか、こういう行動をしたらというのはセンシティブデータだから、絶対そこは触ってはいけないみたいなところがあって、unerryさんは当然そういうことに配慮されながらやっているんです!
内山 (深く頷く)。でも、ニーズはすごく高いです。
尾原 分かってますよ(笑)。
お坊ちゃん育ちのAIにはいつか限界がくる
清水 今の話は偶然だったんだけど、センシティブデータに対する扱いは、これからAIで向き合っていく時にすごい重要です。
尾原 そうですね。
清水 教育ママ的な問題があって、人間が好ましいと思ういいデータだけをAIに学習させていると、結局悪いものが分からなかったり、OpenAIがなぜDALL·Eをすぐに出さなかったのかという話とも、すごく近いと思うんです。
ちょっと邪(よこしま)な気持ちで使うようなウェブサイトやアプリで、上手いことデータを取らないできれいなところだけ見せると、結局、実は本当に欲しい、隠れたニーズは取れないんじゃないかなと思います。
尾原 なるほど。
これはまた1時間ぐらい話さないといけなくなりますが、アメリカでは「digital Me」という言い方をしています。
人の行動特性や考え方の特性みたいなものを「ペルソナ」と言いますが、ネット上やオンラインに溜まっていくデータがあると、このペルソナがデジタル上でAIとして再構築できるじゃないかと。
そうすると、この人はこういうことをやりたがる人だからと、逆に言うと先回りできるわけですね。
だから、究極のおもてなしをするためには、AIで「digital Me」を作っていくことが、結構重要といわれていたりします。
清水 もう1つ言いたいのは、僕は20歳ぐらいの時専門学校で教えていて、その時生徒から、「清水さんのプログラミングテクニックはすごく学びたいし真似したいけど、清水さんの人格は絶対真似したくない」と言われて。

尾原 そうですよね、僕らは常に言われますよね。
清水 (笑)。それで、「お前、だからだめなんだよ」と。
それを別のものだと思っているのが全然だめで、要は、この人格があってこのテクニックとこのスキルがあるのであって、その2つは不可分なんです。
つまり、闇の清水と表の清水は同じものであって、コインの裏表だから、片方だけ真似して片方は真似しないということはできないし、片方を真似しなかったら、それは何もできないよと20年前くらいに言ったのですが、「確かにできてないです」と、この間言われました。
尾原 おもてなしの観点で、そういう闇というかセンシティブな部分を統合しないと、表だけでひょろっとしたデータになるんですね。
清水 今現在でも、多分unerryさんのデータは非常に有用なデータだし、有用なインサイトが得られると思うけれども、やっぱりおきれいなものしか見ていない育ちの良いお坊ちゃんAIみたいなものは、どこかそこで限界が来ると、雑草育ちの僕は思っています。
(続)
【本セッション記事一覧】
- AIの開発に関わるトップランナーたちが集結したシーズン3!
- 「人流データ」から、何がどこまでわかるのか?
- Googleマップの薄い青い円はデータの誤差! 高精度のAIに必要なものとは
- 取得データが多すぎる問題にどう対処する? unerryが上場した目的
- 全国254万箇所の来店検知で「行動DNA」が丸わかり
- 動的データで、人のペルソナ分類から半導体出荷量予測まで明らかに
- イメージと手描きでリアルな画像生成、話題の画像生成AI「Stable Diffusion」
- 長文要約、文章生成…ここまでできる! 日本語の大規模言語モデル「HyperCLOVA」
- 日本のビジネスメールや心削られる謝罪メール、すべてAIにおまかせ
- 天才プログラマー清水 亮が指摘する「検索から生成へ」の変化
- ハイコンテクストな文化こそが参入障壁、日本の「生成系」に勝機あり!
▶新着記事を公式LINEでお知らせしています。友だち申請はこちらから!
▶ICCの動画コンテンツも充実! YouTubeチャンネルの登録はこちらから!
編集チーム:小林 雅/小林 弘美/浅郷 浩子/戸田 秀成