
▶カタパルトの結果速報、ICCサミットの最新情報は公式X(旧Twitter)をぜひご覧ください!
▶新着記事を公式LINEで配信しています。友だち申請はこちらから!
▶過去のカタパルトライブ中継のアーカイブも見られます! ICCのYouTubeチャンネルはこちらから!
ICC KYOTO 2023のセッション「AIの最新ソリューションや技術トレンドを徹底解説(シーズン5)」、全13回の②は、現在の生成AIは半自動のようなもので、結構人の手がかかっているという話題からスタート。データグリッドの工業製品の不良データを自在に作成する「Anomaly Generator」の仕組みや導入のメリットについて、技術サイドから語ります。ぜひご覧ください!
ICCサミットは「ともに学び、ともに産業を創る。」ための場です。そして参加者同士が朝から晩まで真剣に学び合い、交流します。次回ICCサミット FUKUOKA 2024は、2024年2月19日〜 2月22日 福岡市での開催を予定しております。参加登録は公式ページをご覧ください。
本セッションのオフィシャルサポーターは STREET HOLDINGSです。
▼
【登壇者情報】
2023年9月4〜7日開催
ICC KYOTO 2023
Session 11C
AIの最新ソリューションや技術トレンドを徹底解説(シーズン5)
Supported by STREET HOLDINGS
▶「AIの最新ソリューションや技術トレンドを徹底解説(シーズン5)」の配信済み記事一覧

尾原 会場の皆さんは、なぜ細かいところを根掘り葉掘り聞いているのだろうと思うかもしれませんね。
結局ChatGPTがなぜあんなにすごかったのかは、なんとなく皆さん「トランスフォーマーモデルが…」みたいなことを思っているかもしれませんが、実はAIモデルそのものよりも、それができた後にどうチューニングしているのか、しかもそれが人を傷つけたり、ネガティブなことがないように、どうチューニングするかが大事です。
Reinforcement learning from human feedback(人間のフィードバックによる強化学習)という形で、ある程度人間がこういう回答が欲しいんだよ、こういう回答は絶対ダメなんだよというところのチューニングがすごく大事になってきています。
ぶっちゃけOpenAIの強みは、そこが結構あったのではないかという話を、西脇さん、言える範囲でお願いします。
現在の生成AIは結局人間の手がものすごくかかっている

西脇 品質を一番高めたのは、それなんですよね。
AIモデルにできることはそんなに差が無いのですが、結果に対してちゃんとフィードバックしていて、それを人間の手によってしているので、人間が見た感じで最も良いものが得られる仕組みをものすごい勢いで回しています。
実はここに、ものすごく時間とお金がかかっていると思います。
石山 今、さらに「スーパーアライメント」というものを、OpenAIが。
尾原 スーパー…? ああ、要はアライメント、つまり訂正、修正していく。
石山 尾原さんが言ったReinforcement learning from human feedbackは、人間の教師データがまだちょっと必要なので、半自動という感じですが、スーパーアライメントはそれを全自動にしようというので、OpenAIの全体の20%くらいのリソースを、そこに突っ込むんだみたいなことを始めたらしいです。
▶OpenAI、“スーパーインテリジェンス”の人類の敵化防止を目指す新チーム立ち上げ(ITmedia)
これはマイクロソフト的には、どう見てらっしゃるでしょうか?(笑)
西脇 これもそうなんですが、結局めちゃくちゃ人の手がかかるのです。
全部が最終的には全自動になるかもしれませんが、ここに到るまでに人間がめちゃくちゃ動くんですよ。
尾原さんも言ったように、今の生成AIは本当に人間の手によって作られているものなんですよね。
日本人は働いていませんが、ネットでよく言われる非常に貧しい国の人たちが、それを助けているわけなんです。
それが非常に大きな問題になっているので、もっとやり方を考えて進化していかないと。
結局人間の手がものすごくかかっているところ、ここのコストが大きくなっていて、問題になっているのです。
尾原 そうですよね。
だから、一般的には先ほど言った、Reinforcement learning from human feedbackのところで、人間がある程度やって、人間の評価の仕方をラーニングして、自動で評価するようにして、その一部、これはまだ人で評価したほうがいいよね、みたいなものを役割分担する形で、ラーニングしていったりするのですが、それがもう完全にスーパーアライメントだと、自動でやるようにしようと。
石山 それを目指していくという。
西脇 これが難しいのは、マルチモーダルになるとさらに難しくなるのですよね。
テキストだけだったらかなり自動化できますが、音とか映像とか画像とかになってくるとまだまだかなという感じです。
尾原 実はこういうところに、AIを実践投入する際の肝みたいな話があるので、こういうところのプライオリティがわかっていると、ビジネスとして使っていく時にわかるし、だからこそ、そういうのはプロに任せていかないといけないということですよね?
岡田 はい。いつでもおっしゃっていただければ参上しますので(笑)。
武藤 悠輔さん(以下、武藤) すみません、ここで時間を延ばしては駄目なんですが、データグリッドさんで取り組まれているのは、画像データだけですか? それ以外にも取り組まれているのですか?

▼
武藤 悠輔
株式会社ALGO ARTIS
取締役 VPoE
慶應義塾大学物理学科を首席で卒業。スマホアプリ制作会社を起業し CTO として従事。2019 年に DeNA 入社。ソフトウェアエンジニアとして、スポーツ事業やエネルギー事業において、認証・認可基盤やユーザ向けサービス、プロトタイプシステムの開発、運用や、チームのマネジメントを行った。ALGO ARTIS では経営から技術方針の策定、開発プロジェクトの進行を行っている。
▲
岡田 最近はLLM自体の開発はしていないのですが、言語周りでも同様の問題はかなり起きてきているので、その言語におけるデータ生成、そこの評価とか学習データを作っていくこともしています。
武藤 今のところメインは画像に対して、この流れをやるというところが?
岡田 はい、そうですね。
武藤 ありがとうございます。
評価データの品質を安定させるには?
土田 安紘さん(以下、土田) よろしいですか?

▼
土田 安紘
AWL株式会社
取締役CTO
北海道勇払郡生まれ。 北海道大学大学院修士課程修了。 2001年4月に松下電器産業株式会社(現パナソニック(株))に入社し、NTTドコモ向け携帯電話のミドルウェア開発に従事の後、本社R&D部門にて幾つもの新規事業開発プロジェクトを牽引。その後、米国シリコンバレーでの社内起業プロジェクトリーダに抜擢され、2012年から2016年まで米国・日本市場向けのモバイルO2Oサービス事業の立ち上げを主導。 AI新時代の到来、AI活用ビジネスの最前線で業界リーダーとして”ふるさと北海道”からグローバル市場を切りひらくための挑戦の場として魅力を感じ、参画。全社技術戦略、知財戦略を統括。2019年9月に取締役就任。
▲
尾原 もちろんですよ。会場の皆さん、こんな感じで延々と続いていきます(笑)。
土田 先ほどの都筑さんの質問に近くて遠い感じなのですが、AIが画像生成するときに、例えば、人間であれば「それっておかしいよね」と気づけるものもあれば、どうしてもCGっぽさみたいな、もしくは機械学習で作られた、だからこそ人間にはわからない変なノイズや変なテクスチャ、要は現実にはありもしない方向のデータバイアスがかかってしまうこともあると思います。
この辺りは、どのような工夫をされていらっしゃいますか?
岡田 ノイズみたいなものが出る・出ないというのは、我々も当初ありました。
その辺は技術的に、全部を生成するとノイズが出やすいので、実際に作りたいのは、例えば外観検査だと不良部だけなんですね。ベースのほうが、良品はいっぱいあるので。
不良部だけを生成して、その後にノイズ状況を入れるなどすれば、かなり品質としては安定しますね。
尾原 その辺については、僕らは抽象概念だけでたくさん語れる人ですが、良かったら実例の話に入ってもらったほうがいいかもしれません。
岡田 いいですか? このまま終わるかなと思っていました(笑)。
尾原 そんなことないですよ、ちゃんとフォローしますよ(笑)。
工業製品の不良データを自在に作れる「Anomaly Generator」

岡田 ありがとうございます(笑)。
今、我々は「Anomaly Generator」を提供していまして、これは要はいろいろな工業製品の「不良」と書いていますが、良品あるいは不良の画像をお客様の側で自由に簡単に作れるソフトです。
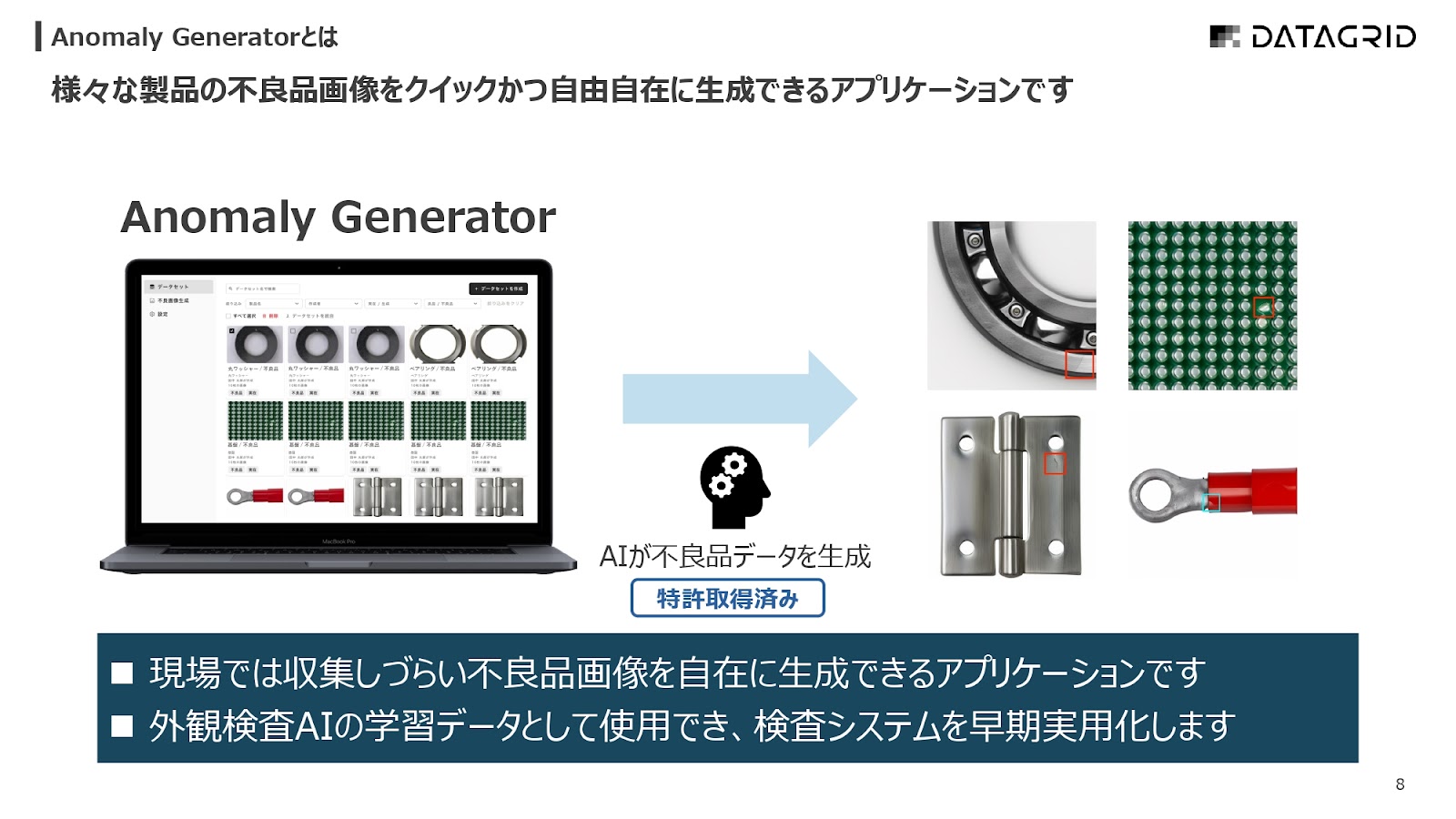
見づらいかもしれませんが、右側の画像に不良部があります。
実際の不良は本当にものすごく小さいので、パッと見てこのサイズだと見えないのですが、良品と不良の画像から不良部を抽出して、その不良部の情報をもとに多様な不良を発生させて、それを良品に合成するみたいなことができるソフトウェアです。
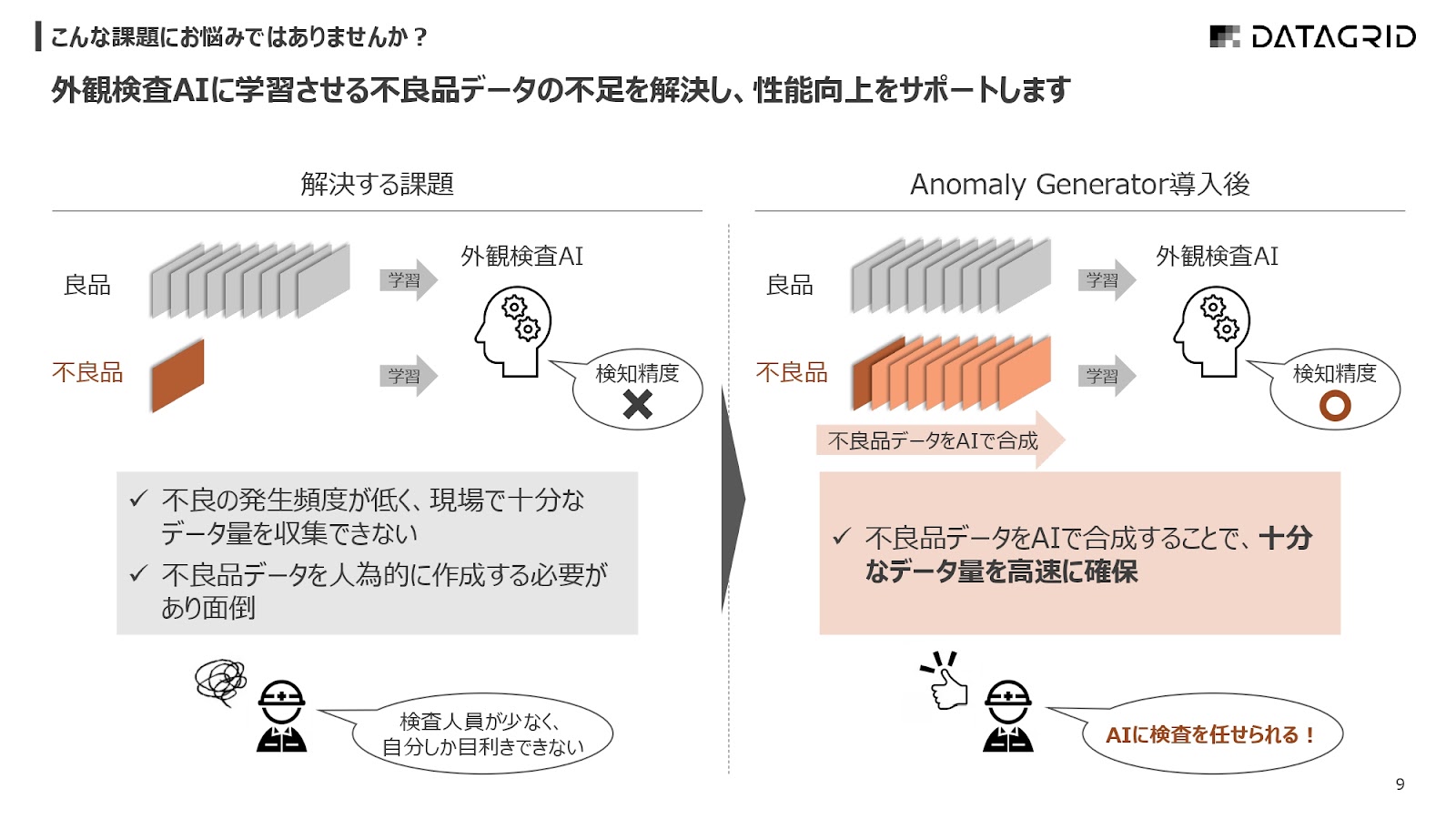
「課題」と書いていますが別に普通の話で、データがアンバランスなのをバランスを整えて精度を上げます。
もともとは、パッと見てわかりやすいアイドルの生成などをしていたのですが、今は超地味なことをやっています(笑)。
「こんなの作れるでしょ?」と思うかもしれませんが、線をいかに自然に作るか、基盤の潰れをどう再現するかとか、金属製品が多いですが、ウィスキーの瓶の製造プロセスにおいて発生する不良を作ったりもします。
かなり汎用的に、お客様のデータをいただければ、カスタムモデルみたいなものを学習させて作る技術を開発して提供しています。
数枚の不良データから様々な不良パターンを生成

西脇 これは素材によって全然出来上がるものが違うんですか? 何によって違うんですか?
尾原 そうか、クレッシェンド(段々強くしていく)のされ方ですね。
西脇 左側は金属ですが、これがゴムや木だったら出来上がる画像は変わるのですか?
岡田 変わります。
西脇 それは素材によってAIが考えるのですか? 何によって考えますか?
岡田 もともと良品と不良のデータを学習していて、良品はだいたい10〜15枚ぐらい、不良は数枚あればいいです。
ただ、そこで無いような不良パターンは作れませんが、パターンがあれば、その特徴を学習して、位置や形状を自由に変えて…
西脇 そうすると生成に必要な変動要素は画像しかないということですよね?
岡田 そうです。
西脇 要は素材であるとか、他の外的な数字を入れているわけではない?
岡田 ないです。
西脇 へえ!
尾原 一応GPTなどは「few shot」と呼ばれるように、少数の事例ということは言われていますが、こんな工業製品にも、ある程度扱えるくらいのレベル感でもうできているということなんですね?
岡田 そうですね。そういうfew shot learningの技術を主に開発していて、そこは技術的な特徴ではあります。
尾原 これはdiffusion(画像生成AIの現在主流のモデル)ですか?
岡田 GAN(Generative Adversarial Network:敵対的生成ネットワーク)の技術とdiffusionが、両方混じっているようなものを今作っています。
尾原 多分、今言ったことを石山さんが、パッとわかりやすく解説してくれると思います。
石山 (笑)。多分、ほぼ皆さん知っているんじゃないですか。
尾原 知らないですよ、会場の皆さんは。
石山 いや、でも、そんな解説することでもないですよね(笑)。
尾原 単純に言うと、diffusionは画像を作るほうのモデルです。
GANはニセモノ(コピー)を作るほうと、これがニセモノかどうか評価するほうの両方がいて、これはいいニセモノですね、これは悪いニセモノですね、ということをやっていくと、どんどん学習しやすくなっていくものです。
それによって、少数のデータを最初に入れてあげるだけで、普通だったらなかなか起きにくい不良品を評価しやすい精度を作ることができます。

西脇 非常に興味があるので、私から質問していいですか?
右から2つ目は、金属にキズが入っているわけですよね。
でも不良品はキズ以外にも、色やシミや厚みとかありますよね。
そういうものは、不良データがもともとなかったら、生成できないですか?
岡田 色や位置や形状に関してはユーザーインプットを新しく入れるので、その情報をもとに、画像処理なども裏で走るのですが、そこを拡張することはできます。
ただ、クラッチみたいなキズがあった時に、「変色したキズを作りたいんだよね」と言われたら、それはデータが無いとできないので、ある種データの限界も、一定これまではあります。
次のステップでやろうとしているのは、今いろいろな不良データがかなり集まってきているので、データのライブラリを製品ごとに学習させることによって、お客様の側で今不良データが無くてもこういう不良があるというものを、我々が事前に出すようにするということです。
西脇 そうですよね、提示できますよね。
多分それは業種によったり検品するものによって提示できるものがあるので、それはナレッジとしてどんどん増えていきますよね。
生成AI導入で3つのメリット
武藤 このAIが上手く画像生成できるようになると、例えば、もともとデータが無い前提で現場に導入すると、画像を集めるのに期間がかかるからアセスメントが長くなって導入までに時間がかかるという課題を解決できると理解しました。その理解で合っていますか?
岡田 3つあって、1つが開発期間の短縮で、学習データの準備コストが下がります。

2つ目が、先ほど申し上げた、評価のところです。
結局最初の導入時期は信頼性が低いので、サブラインのようなところで謎のテストみたいなことをずっと1年くらいやっていきますが、それを事前に評価することによって、かなり短縮できるのが2つ目です。
3つ目が、運用している中でどんどん精度が下がっていくケースもあると思いますが、継続的な学習の時に、アルゴリズム的な改善は結構大変なので、データを追加することによって弱点を潰すみたいなところでも使っていただいています。
武藤 なるほど。品質も上げつつ期間も短くする、運用時も安定させるというところがあって。
尾原 だから、こういうものってトレーニングしている間は使えないでしょ?みたいなところを、サッと作ってまずは始める。
もしかしたら、人間の検品とセットでやるかもしれませんみたいなところから始まりつつ、でもこういう機械製品は、夏になると膨張率が変わりますよねとか、機械が摩耗してくると、別のタイプのキズが付くかもしれませんねみたいなことが常にあります。
そうすると、それに合わせた追加の異常データもまた作って、どんどん修正していくという話だし、さらに言うと、多分異常データの生成に生成AIを使っているけれど、不良品の検知自体は割と枯れた画像認識ですよね。
岡田 そうですね。
尾原 ということは、エラーデータを作るところはそれなりにGPUリソースを使うけれど、1回モデルを作ってしまえば、検知カメラについては結構安く作ることができます。
その辺はAWLさんは得意ですか? 不良品検知カメラみたいなものは、あまりやっていないですか?
土田 不良品はやっていませんが、例えば、店員さんだけ欲しいみたいな話があります。
お客さんと店員さんは2人組ではわかるのですが、それを分類するようなモデルは、ローソンに持っていった時とセブンイレブンに持っていった時とでは全然違ったりするので、そういう話はあります。
そういう時に、例えば、2〜3枚店員さんだけのデータを入れたら、後は上手くやってくれるよというのはすごくいいなと思いました。
尾原 確かにね。スタッフのエプロンがちょっと変わった時にもちゃんと対応しますよとか、お店に検知カメラを入れて、やたらここが活況だなと思ったら、単に店員が動きまくっているだけだったみたいなことを防ぐこともできるということですよね。
土田 はい、おっしゃる通りです(笑)。
西脇 今、対象は画像データですが、音なども検品できますか? 検品は音もありますよね。
岡田 音や時系列のセンサーなどもやっていますが、まだ汎用化できていないので、それは個別の共同研究みたいな形でやっていたりします。
我々は外観検査のデータを作るために会社を作ったわけではないので、将来的にはこれからのAI社会をしっかり進めていく中で、データの課題を解決することは重要だなと思っています。
▶マクニカ、人間の脳波を使って画像分類AIモデルを学習させられる「InnerEye AI」を販売(IT Leaders)
尾原 ちなみにこの分野では、イスラエルの会社で検品のプロの方の脳波を取って、その脳波の動き方のパターンラーニングをして、不良品を検出するということに取り組んでいる会社があります。
こういうものと組み合わせると、あっという間に脳波データの中から、なぜかよくわからないけれどヒヨコのオス、メス、オス、メス…、と性別の検品ができる人をAI化できるみたいなこともできたりしますよね。
ちなみに、どのぐらいの価格で、どんな感じでできるものなんですか?
岡田 価格体系としては、工場の場合だと、このラインを自動化したい、予算は幾らみたいな感じで、1製品をやる時にいくらみたいな形に設定していて、作る枚数にもよりますが、だいたい数万円から20万円ぐらいです。
尾原 そのぐらいですか。
岡田 まあ1品種という形ですけれど。
高品質が強みの日本でエラーを減らす

尾原 まとめに入っていきたいのですが、なぜこんなに深掘りするかというと、ビジネスの中にAIを入れていくのは、どうしてもAIはトレーニングするまでと精度が上がるまでに時間がかかるので、最初から売上を増やしますみたいな話だったり、人を殺してしまったらシャレにならないよみたいなところには入れにくいのですね。
そういう中で、今も人によってどうしても不良品のエラーが出ていて、そもそも今マイナスになっているところのマイナスをちょっと減らしてあげるだけで、特にエラーを減らすことは利益に直結するので、コスト削減で不良品検品というのは、ものすごく入り込みやすいのです。
しかもこれは1回モデルを作ってしまったら、エラー検知自体のAIはものすごく安く作れて、スマホで写真をピッと見たら、ああ、ここがエラーですみたいなことができます。
だから、極端な話、クリーニング屋さんがお客さんから服を預かった時の状態と、クリーニングで服を汚してしまった時の状態とか、そういうレベルの中小の店舗で使って、ものすごく便利になるというところや、あと職人さんが減ってきているので、職人さんが生きているうちにエラー検知をできるだけAIにしなければいけないところなど、いろいろ強いですよね。
実際に導入されてきていて、どんな反応ですか?
岡田 今導入していただいているのは大手の大企業で、AI化に取り組んで、だいたい1回失敗しましたという会社です。
なぜかというと、データがグチャグチャだったりデータが全然無いのにベンダーさんが入ってやっていて、ベンダーさんは悪くないと思っていますが、データが無いからどうしようもないみたいな。
それで、データが無ければ作ろうと、我々のプロダクトを試してみて、採用している企業もあるので、そういう意味では、データの面の重要性は、1回やられた会社さんほど感じられているのかなと感じています。
尾原 ちなみに差支えなければ、今後の展望としては、どういうところを探求していきますか?
岡田 我々は外観検査のAIを作っているわけではないので、いろいろな会社さんと、まず連携していこうと思っています。
データという領域に特化して、1つは外観検査というユースケースですが、社内では自動運転のデータだったり、店舗や、いまのところ人に関するデータを作ることに取り組んでいます。
あるいは今は画像ドメインが中心ですが、西脇さんにお話しいただいたような、音、センサー、ライダーなども非常にニーズが高いので、そちらにも展開していこうというのが今後のキーワードです。
尾原 なるほどねえ。
ということで、生成AIはどうしてもなんとなく業務効率化の領域に思われがちなところで、実はモデルよりもデータが大事な部分があるし、何よりもデータを作っていくことで、日本は高品質が強みで、その中でネガティブを減らす、リスクを減らすところで使っていくということで、データグリッド岡田さん、ありがとうございました。
岡田 ありがとうございました。
(終)
本セッション記事一覧
- AIの最新トレンドをマニアックに語り尽くすシーズン5!
- 工業製品の不良データを自在に生成できるデータグリッドの「Anomaly Generator」
- プロも活用する、ノーコードのウェブデザインツール「STUDIO」
- 自然言語の指示でウェブデザインができる「STUDIO AI」、世界的な反響
- 生成AIが効くのは、プロダクティビティかクリエイティビティか
- 「STUDIO AI」が目指すのは、指示の実行ではなく、願望の実現
- エクサウィザーズの企業向け生成AIサービス、どんなものがあるのか
- OpenAIが一度諦めたロボット領域への挑戦
- 詳説! マイクロソフトとOpenAIの深い関係
- メーカー、建設、金融大手が導入するChatGPTを実例紹介
- ChatGPTがラジオの台本を作成してみたら…
- ここまでできる! Wordをパワポに変換、不在オンライン会議の内容確認
- 生成AIのプラグインがマーケット化する可能性【終】
▶カタパルトの結果速報、ICCサミットの最新情報は公式X(旧Twitter)をぜひご覧ください!
▶新着記事を公式LINEで配信しています。友だち申請はこちらから!
▶過去のカタパルトライブ中継のアーカイブも見られます! ICCのYouTubeチャンネルはこちらから!
編集チーム:小林 雅/浅郷 浩子/戸田 秀成/小林 弘美