
▶カタパルトの結果速報、ICCサミットの最新情報は公式X(旧Twitter)をぜひご覧ください!
▶新着記事を公式LINEで配信しています。友だち申請はこちらから!
▶過去のカタパルトライブ中継のアーカイブも見られます! ICCのYouTubeチャンネルはこちらから!
ICC KYOTO 2023のセッション「AIの最新ソリューションや技術トレンドを徹底解説(シーズン5)」、今回も錚々たるメンバーが集結し、最先端の技術を語り尽くします。全13回の①は、データグリッドの岡田 侑貴さんが登場。数少ないデータから役立つデータを生成するAIについて、ユースケースとともに解説します。聞き手はおなじみ尾原 和啓さんです。ぜひご覧ください!
ICCサミットは「ともに学び、ともに産業を創る。」ための場です。そして参加者同士が朝から晩まで真剣に学び合い、交流します。次回ICCサミット FUKUOKA 2024は、2024年2月19日〜 2月22日 福岡市での開催を予定しております。参加登録は公式ページをご覧ください。
本セッションのオフィシャルサポーターは STREET HOLDINGSです。
▼
【登壇者情報】
2023年9月4〜7日開催
ICC KYOTO 2023
Session 11C
AIの最新ソリューションや技術トレンドを徹底解説(シーズン5)
Supported by STREET HOLDINGS
(スピーカー)
石山 洸
エクサウィザーズ
Chief AI innovator
石井 穣
STUDIO
代表取締役CEO
岡田 侑貴
データグリッド
代表取締役
西脇 資哲
日本マイクロソフト
コーポレート戦略統括本部 業務執行役員 エバンジェリスト
(リングサイド席=質問者)
土田 安紘
AWL
取締役CTO
都筑 友昭
DROBE
執行役員CTO
武藤 悠輔
ALGO ARTIS
取締役 VPoE
(モデレーター)
尾原 和啓
IT批評家
▲
▶「AIの最新ソリューションや技術トレンドを徹底解説(シーズン5)」の配信済み記事一覧
AIのトレンドがわかる人気セッションのシーズン5
尾原 和啓さん(以下、尾原) ICCサミット3日目の朝一のセッション、しかも135分の長尺にご参加いただきましてありがとうございます。

▼
尾原 和啓
IT批評家
作家
京都大学院で人工知能を研究。マッキンゼー、Google、iモード、楽天執行役員、2回のリクルートなど事業立上げ・投資を専門とし、内閣府新AI戦略検討、経産省 対外通商政策委員等を歴任。現在13職目 、近著「アフターデジタル」は11万部、元 経産大臣 世耕氏より推挙。「プロセスエコノミー」はビジネス書グランプリ イノベーション部門受賞。
▲
3日目の朝のちょっと人がまばらな感じだからこそ、徹底的にマニアックに話せる、これがICCサミットの3日目の特徴でして、ありがたいことに、もうシーズン5まで来ました。
<過去のディスカッションはこちら>
▶【一挙公開】AIの最新ソリューションや技術トレンドを徹底解説(全8回)
▶【一挙公開】AIの最新ソリューションや技術トレンドを徹底解説(シーズン3)(全11回)
▶【一挙公開】AIの最新ソリューションや技術トレンドを徹底解説(シーズン4)(全12回)
西脇 資哲さん(以下、西脇) 続いていますね。

▼
西脇 資哲
日本マイクロソフト株式会社
業務執行役員 エバンジェリスト
マイクロソフトの業務執行役員であり、多くの最新テクノロジーを伝え広めるエバンジェリスト。 「エバンジェリスト」とはわかりやすく製品やサービス、技術を紹介する職種。 他にコミュニケーションやデモンストレーションといった分野での講演や執筆活動も行い、製造業、金融業、官公庁、教育機関などでのプレゼンテーション講座を幅広く手がける。 著書に『エバンジェリストの仕事術』、『プレゼンは “目線” で決まる』などがある。
▲
尾原 はい。もともとは1社のAIをぐっと深掘りするところから始まりましたが、シーズン2で好評だったので、3社に話してもらうことになりました。
シーズン3からは、前シーズンで登壇した方々にリングサイドに回っていただいているので、実はリングサイドに質問者として来ている方々も、AIのエキスパートで、どんどん質問していく形で輪が広がっています。
今回は、各企業が事業とその裏側にAIをどう使っているのかを1社30分ぐらいでお話しいただいて、その中でリングサイド、登壇者からもどんどん質問して深掘りしていきます。
もし会場の皆さんから、これはちょっと聞いてみたいということがありましたら、手を挙げていただければ拾っていきますので、ぜひよろしくお願いいたします。
最初に、今日会場に来ていただいている皆さんの、AIのスタンスをちょっと確認させていただきたいですね。
要はAIを作っている側なのか、使っている側なのか、作っている側もAIそのものを事業にしているのか、それとも事業の中のAIを自社で作っているのか、この3つでお聞きしたいと思います。
AIを作っていて、AIそのものを事業にしている方は、どのぐらいいらっしゃいますか? あっ!
西脇 いらっしゃいますね。
尾原 今回が初ですね! …ヤバい。
西脇 出てきたってことですよね、そろそろ。
尾原 そうですね。ありがたいですね。
では最前列に座っていただいて、ぜひ…、嘘です、嘘です(笑)。
(会場笑)
では、2番目の、AIを開発しているけれども、AIそのものを事業にしているわけではないという方は、どのくらいいらっしゃいますでしょうか?
ああ、ちょっと増えてきましたね。
ということは、他の方々はAIを使いたい、または使っている側ですかね。
ちなみにAIをもうすでに使っているよという方はどのくらい? うぉー!
西脇 ほとんどですね。
尾原 やはりちょっと世の中でAIが当たり前になってきた感じがしますね。
というわけで、今日の手の挙がり方を見ると、ほとんどAIを使っていらっしゃるということですから、マニアックにいって大丈夫と解釈しました(笑)。
ちょっとわからないなという時には首を傾げていただくと、僕が追加で解説をする形でやっていきます。
今日の順番としては、生成AIそのものを事業のコアにおいていらっしゃるので、データグリッド岡田さんから始めていただきます。
次に、STUDIO石井さんからAIを活用するSaaSというポジションでお話しいただいて、エクサウィザーズ石山さんからはワークフローについて、AIがあるからいろいろなものが最適化されていくというお話をしていただきます。
最後は全てのAIをサポートして、全てをエンパワーメントして、アチーブ・モアしていくマイクロソフト西脇さんという順番でいきたいと思いますので、岡田さん、よろしくお願いいたします。
生成AI領域にずっとフォーカス、データグリッド岡田さん
岡田 侑貴さん(以下、岡田) よろしくお願いします。
では、データグリッド岡田から、ご紹介させていただきます。

▼
岡田 侑貴
株式会社データグリッド
代表取締役CEO
京都大学にて機械学習分野を専攻し、京都のAIベンチャーにて金融分野のデータ解析業務に従事。GANに代表される生成AI技術の急速な発展を目の当たりにし、生成を用いたソフトウェアの開発・提供を行うべく2017年に当社を設立。
▲

我々は2017に会社を作りまして、当時は、「生成AIって何? おいしいの?」みたいな感じでしたが、去年(2022年)ぐらいから非常にホットトピックになってきました。
尾原さんからご紹介いただいたように、生成AIの領域にずっとフォーカスしながらやってきた会社です。
この後、いろいろな話が出ると思いますが、生成AIというもの自体の使い方として、私は大きく2つのタイプがあると思っています。
生成AIは、画像生成であれ、言語モデルであれ、結局何かのデータを作るわけです。
その作ったデータを、人がある種コンテンツや何かに使うものとして利用していくのがまず1つです。
もう1つは、コンピュータがそのデータを使う、この2パターンがあると思っています。
我々は紆余曲折、いろいろ生成AI氷河期みたいな時代から取り組んできて、前線で戦ってきましたが、まさにOpenAIやStability AIなどの外資もどんどん出てくる中でグローバルの競争が非常に激しくなってきたため、後者のコンピュータ向けのデータ生成を生成AIを使って取り組んでいます。
尾原 ほう!
岡田 その辺りをお話しできればと思います。
尾原 そうですね、サブタイトルも「スモールデータ時代のAI活用」ということで、ちょっと楽しみですね。
岡田 はい。この下に書いている??(06:55)のがちょっとポイントなんですが、簡単に会社紹介と、今やっているサービスのご紹介もできればと思います。
2017年に会社を設立して、生成AIをずっとやってきました。
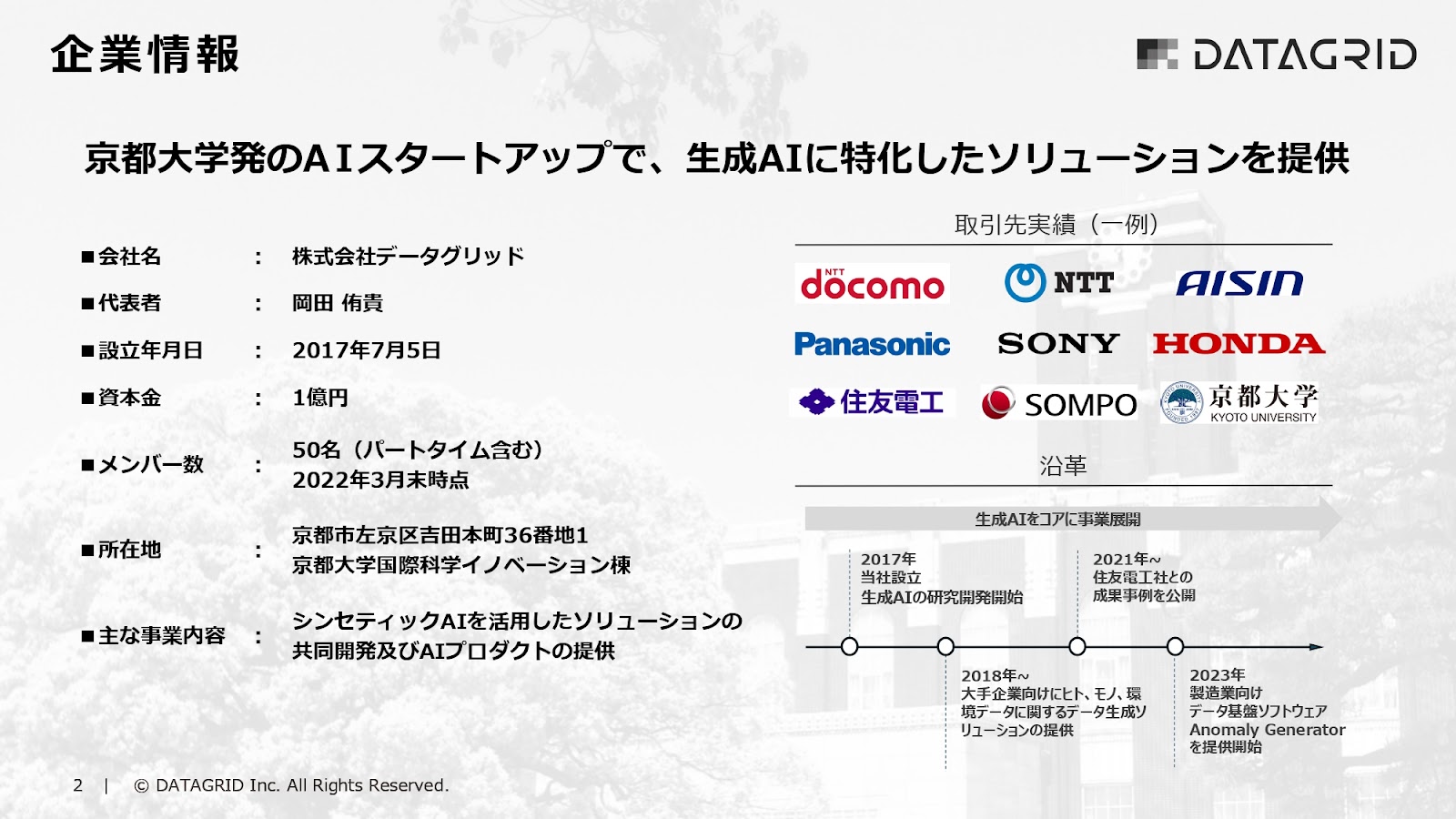
1つの特徴として、今はものづくり系会社の生成AIの活用にフォーカスしています。
実際どんなデータが作れるかというと、一例ですが、こちらのデジタルヒューマンという、非常にリアルな、いそうでいない人を作りました。

一番最初はアイドルを作ったりして、何をやっている会社かよくわからなかったのですが、こういう人のデータを作ったり、この後に紹介するもののデータを作ったり、あるいは環境ですね、街中のデータなどをAIで作っていました。
▶アイドル自動生成AIを開発 Jun 19, 2018(データグリッド)
尾原 今でこそ生成AI、画像系はすごく進化したから当たり前のように思えてきていますが、このシリーズで初めて出していただいたのが2年前かな?
岡田 そうですね。
尾原 あのタイミングで服を含めてここまでナチュラルにというのは、相当我々は驚愕しましたよね。
岡田 結構海外ではバズりました。
この後にどんどん新しいものが出てきて、今やもう普通なので、別にこれ自体誰も驚かないですけれども(笑)、2~3年前だったら「わあ、すごいね!」と。
やはり急激な変化がある領域です。
AI用トレーニングデータ作成がメイン事業
岡田 我々は生成AIの技術をもとに、データソリューションを提供しています。
生成AIによって、いろいろなAIの学習データや評価データに使える、いわゆるトレーニングデータ系を作っていくことに、今かなり力を入れています。
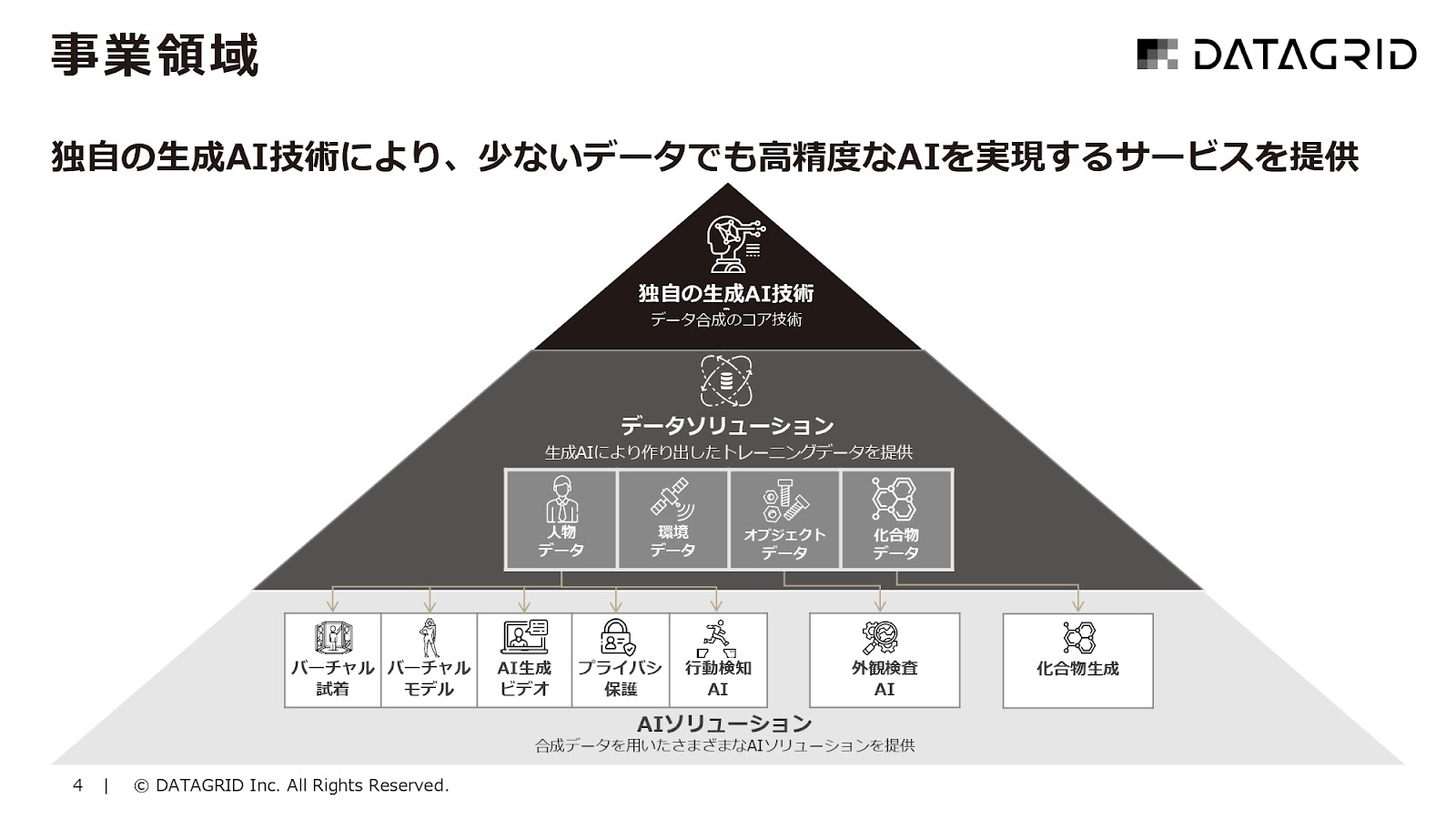
そういうデータを使ったAIソリューションを一部やっていたりしますが、メインはAI向けのデータ生成です。
なぜこんなことをやっているのか、背景についてお話しします。
サブタイトルにも「スモールデータ」と入れましたが、デジタルでのAI活用が2010年代、非常に進んだと思っています。
これから企業のDXなどの文脈の中で、リアルアセットをお持ちの会社さんのAI活用は、どんどん広がっていくだろうと考えています。
その時に何がポイントになるかというと、デジタル空間ではユーザーのログデータなどがデータですので、非常に簡単に大量の、ある種質の良いデータが集まりやすい環境になっているので、いわゆるビッグデータをたくさん集めて、それをどのように効率的に処理するアルゴリズムを作るかみたいなことがポイントだったわけです。
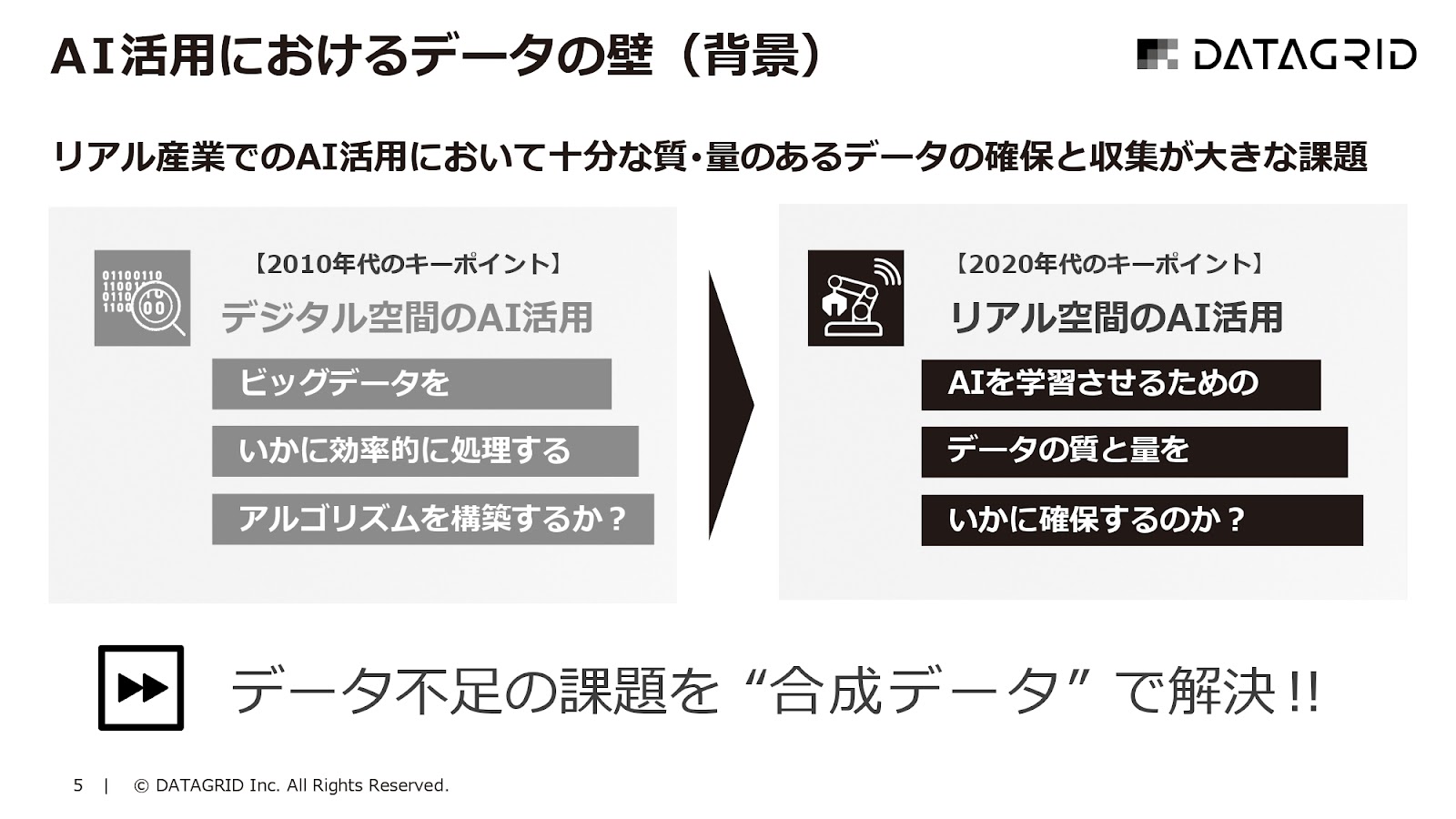
これが現実空間、リアルアセットをお持ちの製造業だとわかりやすいですが、そういうところでAI活用をしようと思うと、そもそもまずデータが発生しません。
物が動かないとデータが取れないので、データが全然出てこないとか、取得にコストがかかるとか、集めてもデータの形式がぐちゃぐちゃみたいな状況がよくあります。
「アルゴリズム」と「データ」がAIの構成要素の2つとしてあるわけですが、今どんどんアルゴリズム側からデータのほうに、課題が移ってきているなと思います。
そういうデータの課題を、ある種AIのためのAIみたいなイメージで、生成AIの技術を使って解決できないかと取り組んでいます。
尾原 石山さん、この辺のdata synthesis(データ合成)は、結構業務の中でも課題などが出てくるケースが増えてきていますよね?
石山 洸さん(以下、石山) めちゃくちゃ増えてきていますね。

▼
石山 洸
株式会社エクサウィザーズ
Chief AI Innovator
2006年4月、株式会社リクルートに入社。2015年4月、リクルートのAI研究所であるRecruit Institute of Technologyを設立し、初代所長に就任。2017年3月、デジタルセンセーション株式会社取締役COOに就任。2017年10月の合併を機に、株式会社エクサウィザーズの代表取締役社長に就任。2023年4月より取締役、同6月より執行役員(Chief AI Innovator)。静岡大学客員教授を歴任。
▲
尾原 どういうユースケースが多いですか?
石山 何でもありますよね。
例えば、小売でプロダクトの3Dデータが欲しいとか、スーパーマーケットの中の全体のモデルが欲しいとか、あるいは物流でもデジタルツインでやっていきたいとか、そういうものが死ぬほどたくさんあるので、ニーズはすごく増えてきています。
グローバルも含めて、スタートアップが増えてきている印象がありますね。
岡田 いつかエクサウィザーズさんにも使っていただけると。
尾原 ここで商談が(笑)。
岡田 嬉しいなと、チラッと思っています(笑)。
AI構築における生成データ活用のメリット

岡田 こういう生成データを使うことで、何が嬉しいかというと、データを集める期間がめちゃくちゃかかるケースが多いので、開発期間を相当短縮することができる点です。
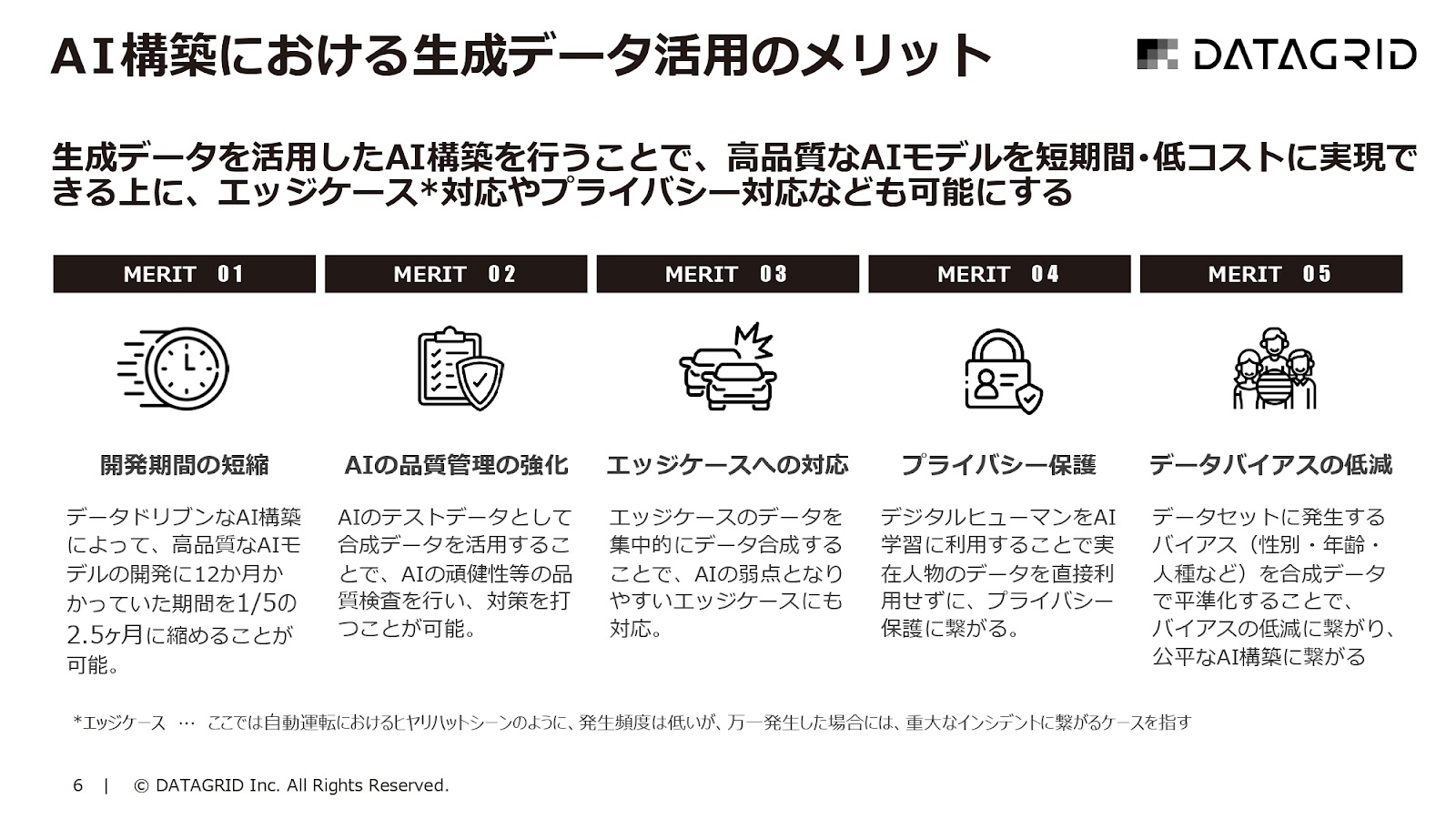
結構今ニーズとして強いのが、最近、「Trusted AI」という概念があって、要は、作ったAIがどれだけ信頼できるかみたいな話です。
この後外観検査のデータ生成の話をするのですが、外観検査の領域ですと、テストデータが、実データでNGが10個しかないみたいなことがあります。
10個で評価して精度100%にしたと言われても、11個目はどうなるのか、20個目がどうなるのか、データが少ないと信頼性をしっかりと担保できません。
そういう意味で、評価データとして網羅的なデータを作ることで、AIの品質管理みたいなところで利用します。
「エッジケース」と書いているのは、「まれにしか発生しないけれども重要なケース」で、わかりやすいのは自動運転のヒヤリハットや事故のシーンです。
そういうシーンは非常に重要だけれども、一番データが発生しづらいためウィークポイントになりやすいので、そこを重点的に作ったりします。
あとは、「プライバシー保護」や「データバイアスの低減」です。
この辺も最近のAI倫理で言われているところですが、プライバシーを保護したデータとして作るというので、実データだけではなくて、シュミレーションのデータを開発に利用することが増えてきています。
データバイアスは、多分マイクロソフトさんや大企業は気にされることが多いと思います。
白人に関してはすごく検知能力が高いAIだけれども、黒人になると検知能力が非常に落ちるとか、よく叩かれることになるわけです。
要は白人ばかりのデータで学習していて、黒人がデータに入っていないのが原因で、別にAIは人種差別をしようと思っているわけではないので、データの面を改善してあげることによってバイアスの低いAIを作ることに使っていけます。
尾原 どうしてもインターネットで中世の絵を描こうとすると、あるファンタジー作家の絵っぽくなってしまうとか、美少女だと日本原型の美少女っぽくなってしまう問題のように、世の中にあるデータ自体が、どうしても偏っていて。
岡田 そうですね。その偏りをなだらかにしてあげるというか、そういうところでも使っていただく会社が出てきています。
外観検査に生成AIを活用して起こりがちなことは?
都筑 友昭さん(以下、都筑) すみません、ちょっと質問をさせていただいても…?

▼
都筑 友昭
株式会社DROBE
執行役員CTO
半導体のエンジニアとしてキャリアをスタート。回路設計や組み込みのソフトウェア開発などを行っていたが、iPhone3GSの発売によりアプリ開発にハマりソフトウェエアエンジニアにキャリアチェンジ。 ソーシャルゲームプラットフォーム運営会社にてKPIの計測基盤やUnityによるゲームの開発などを行った後、EMとしてゲーム開発チームのマネージメントを行う。 その後フリーランスとなりWeb系の案件を複数行いながら自分の会社の運営を行い、2016年よりBCG Digital Venturesに参画。AIなどの先端的な技術を用いたPoC案件などに携わった後、2019年より現職。
▲
尾原 もちろん! ファッションをやっていらっしゃるDROBEさんです。
大好きですよね、この辺のお話は。
都筑 はい(笑)。DROBEの都筑と申します。
黒人が判定されないというのは、ファッションのAIではモデルしか識別しないとか、モデル向けのものしか成さないといったことがすごくあるので、課題がわかるなと思っていました。
それはそれとしつつ、外観検査などで10点しかfail(失敗)というかanomaly(異常)が無いような場合に、クラシックな手法で言うと、いわゆるaugmentation(拡張)みたいな手法でやっていたと思います。
普通のaugmentationではなくて、生成AIを使うことによって逆にhallucination(事実に基づかない情報を生成する現象)とか、本当はfailではないのにfailのデータとして生成されてしまって、AIが勘違いしてしまうとか、その辺りのクラシックな手法との違いみたいなところを教えていただいてもよろしいですか?
尾原 今都筑さんがおっしゃったのは、要は日本は製造業のレベルが特に高い分、おかしなものが出にくいわけです。
でもおかしなものが出た時は、超変なものが出ます。
そういうものをanomalyと言って、それを学習しようと思ったら、出た超変なものをほんの少しずつずらしていくaugmentation(拡張)をやることで学習させましょうみたいな手法が、通常のやり方だったわけです。
生成AIを使うと、いろいろなバリエーションができる分、ありもしないようなニセモノの失敗が出てしまわないか、そういうHallucination(事実に基づかない情報を生成すること)についてのご質問です。
▶生成AIの大問題 「幻覚」の現状と議論(クラウドWatch)
▶2023年の流行語「ハルシネーション」 人の健康をむしばむAIの欠陥(Forbes)

岡田 ありがとうございます、非常に重要な点だと思います。
まず従来のdata augmentation(データ拡張)との大きな違いは範囲で、基本的にdata augmentationは必要な時に画像を回転させるとか、変形させるとか、色を変えるとか、そんなことをやっていて、ある種変化させている範囲はかなり限定的です。
それに対して我々がやっているのは、例えば、不良部の位置であったり、大きさ、形状などを人間が指定した上で作れるようにするところで、従来の古典的なdata augmentationに比較すると、対応範囲、表現範囲が広いのがまず1つ違うところとしてあります。
もう1つ、非常に重要なのは、生成AIで作るため現実にはできるはずのない不良を作り出してしまって、そんなデータないでしょみたいなことが起こることです。
例えば、皆さんご存知だと思いますが、Stable Diffusionのような画像生成のモデルを使うと、まあまあそういう現象が起こります。
見た目は非常にリアルで、それらしいのですが、現場の方に見せると、「こんなのできるわけないでしょ」みたいなことを言われます。
そういう意味で何が大事かと言うと、実際にこういうデータが発生しうるということが頭の中にある人たちが、その情報をシステムにインプットして、その情報をもとに作り出すプロセスが必要で、我々は、ある種ユーザーの操作性を高めるみたいなところを結構やっています。
外観検査の領域で言うと、不良部の位置、形状、大きさや輝度などの情報を、全部パラメータを指定して作り出すので、そもそもその人が間違っていたらどうしようもないですが、合っているのであれば、「そもそもこういうものはできないよね」というケースにはならないので、そういうところを工夫してやっています。
AIが作成した評価データの品質評価方法は?

都筑 ありがとうございます、いろいろ興味が出てきてしまいました。
それは作った後に評価をちゃんとしないといけないといったプロセスは残ってくるのですか?
AIで作った不良をAIに学習させて、これは確からしいよねとちゃんと言えるのかとか。
結局、最終的に人間がチェックして、AIが作った評価データに対してこの評価データはイケているとか、上手くできたねとか、評価はどうされていますか?
岡田 作ったデータの品質評価という意味では、2段階あります。
1つは、目視における定性評価みたいなことをシステム上でしてもらっています。
これはあり得ない、おかしいみたいなものがあれば除外します。
もう1つは、実際やりたいことは何かというと、きれいな画像を作りたいというよりも、学習評価において、AIにとって良い情報を与えられるデータを作りたいということです。
一番大事なことはAIのモデル、要は精度が上がることなので、まずは実データでも精度を1回測っています。
都筑 ありがとうございます。
モデルを作ってしまって、その結果精度が上がっていたら、データも良かったよねというような考え方ですね。
岡田 まあ工学的にはそうですね。
医療の分野などでもこういうこともやっていますが、医療などはちょっと話が違うんですよね。
都筑 そうですよね。そういうことをやっていいのだっけ?みたいな。
岡田 そういうことになりますね。
尾原 やはりミッションクリティカルなところがありますからね。
都筑 ありがとうございます。
(続)
本セッション記事一覧
- AIの最新トレンドをマニアックに語り尽くすシーズン5!
- 工業製品の不良データを自在に生成できるデータグリッドの「Anomaly Generator」
- プロも活用する、ノーコードのウェブデザインツール「STUDIO」
- 自然言語の指示でウェブデザインができる「STUDIO AI」、世界的な反響
- 生成AIが効くのは、プロダクティビティかクリエイティビティか
- 「STUDIO AI」が目指すのは、指示の実行ではなく、願望の実現
- エクサウィザーズの企業向け生成AIサービス、どんなものがあるのか
- OpenAIが一度諦めたロボット領域への挑戦
- 詳説! マイクロソフトとOpenAIの深い関係
- メーカー、建設、金融大手が導入するChatGPTを実例紹介
- ChatGPTがラジオの台本を作成してみたら…
- ここまでできる! Wordをパワポに変換、不在オンライン会議の内容確認
- 生成AIのプラグインがマーケット化する可能性【終】
▶カタパルトの結果速報、ICCサミットの最新情報は公式X(旧Twitter)をぜひご覧ください!
▶新着記事を公式LINEで配信しています。友だち申請はこちらから!
▶過去のカタパルトライブ中継のアーカイブも見られます! ICCのYouTubeチャンネルはこちらから!
編集チーム:小林 雅/浅郷 浩子/戸田 秀成/小林 弘美