
▶カタパルトの結果速報、ICCサミットの最新情報は公式Twitterをぜひご覧ください!
▶新着記事を公式LINEで配信しています。友だち申請はこちらから!
▶過去のカタパルトライブ中継のアーカイブも見られます! ICCのYouTubeチャンネルはこちらから!
ICC FUKUOKA 2023のセッション「AIの最新ソリューションや技術トレンドを徹底解説(シーズン4)」、全12回の③は、 DROBEが具体的にどのようにAIを鍛えているかを解説します。集まったデータをすべて入れるのではなく、狙い通りのものにするには人間の手が不可欠。そこでDROBEが誇るプロのスタイリストたちが登場します。ぜひご覧ください!
ICCサミットは「ともに学び、ともに産業を創る。」ための場です。そして参加者同士が朝から晩まで真剣に議論し、学び合うエクストリーム・カンファレンスです。次回ICCサミット KYOTO 2023は、2023年9月4日〜 9月7日 京都市での開催を予定しております。参加登録は公式ページをご覧ください。
本セッションのオフィシャルサポーターは ファインディ です。
▼
【登壇者情報】
2023年2月13〜16日開催
ICC FUKUOKA 2023
Session 11C
AIの最新ソリューションや技術トレンドを徹底解説(シーズン4)
Supported by ファインディ
▲
▶「AIの最新ソリューションや技術トレンドを徹底解説(シーズン4)」の配信済み記事一覧
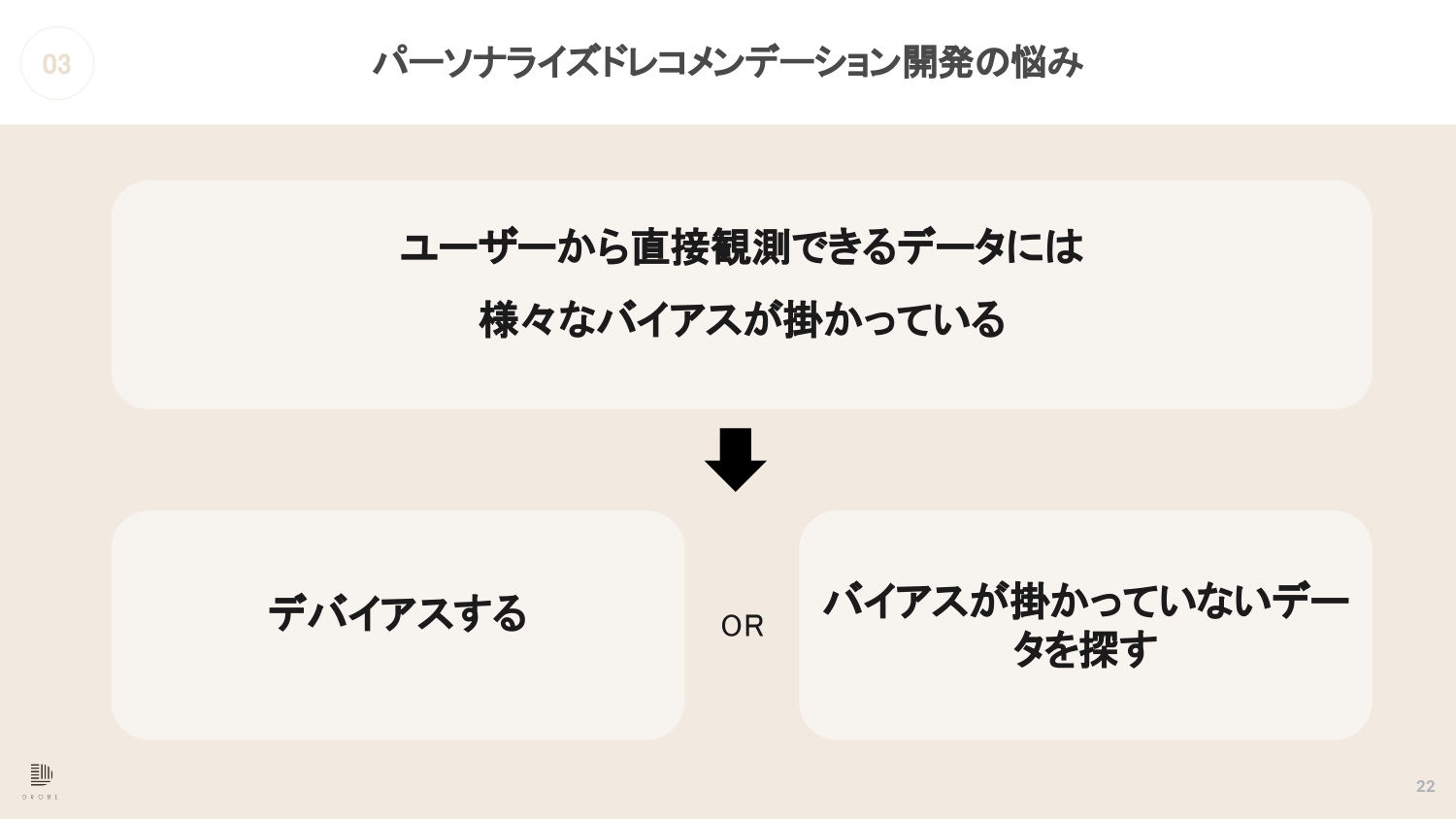
バイアスの掛かったユーザー情報の取り扱い

都筑 ユーザーから直接観測できるデータには、本当にいろいろなバイアスが掛かっています。

ではどうするかというと、大きく2つ道があるかなと思っています。
「デバイアス」という技術領域があります。
尾原 バイアスをどう外していくかということを、AIや機械学習やフィルタリングでやっているということですね。
都筑 はい。もう一つは、バイアスが掛かっていないデータを探すという道があります。
尾原 サンプリング的に、バイアスが掛かっていなさそうなユーザーだけから学習するとか、ユーザーの行動の中で、ここはバイアスが掛かるから、そもそも入力データに使わないとか、そういうことをやっていくということですよね。
都筑 はい。おっしゃる通りです。
尾原 これはめちゃくちゃ大事なことを言っていますからね。ここまで話してくれて、ありがとうございます。
都筑 いえいえ、とんでもないです。
土田 1点そこでよろしいですか?
バイアスは時間で変わっていったりするし、地域的にも変わるじゃないですか。
そうなっていったときに、バイアスなのか、そもそも点レベルでしかクラスターができていないのか、どっちだか分からないという状況になってしまうんじゃないかなと思いますが。
都筑 そうですね、結構そこはあると思っています。
その辺りを含めて、ではどうするんだという話が割と単純な話ではあるのですが、この後ちょっとご説明させていただきます。

土田 誘導されちゃいましたね。
(一同笑)
都筑 ありがとうございます。
尾原 あと10分たっぷりありますから。
DROBEのスタイリストはAIを育てる
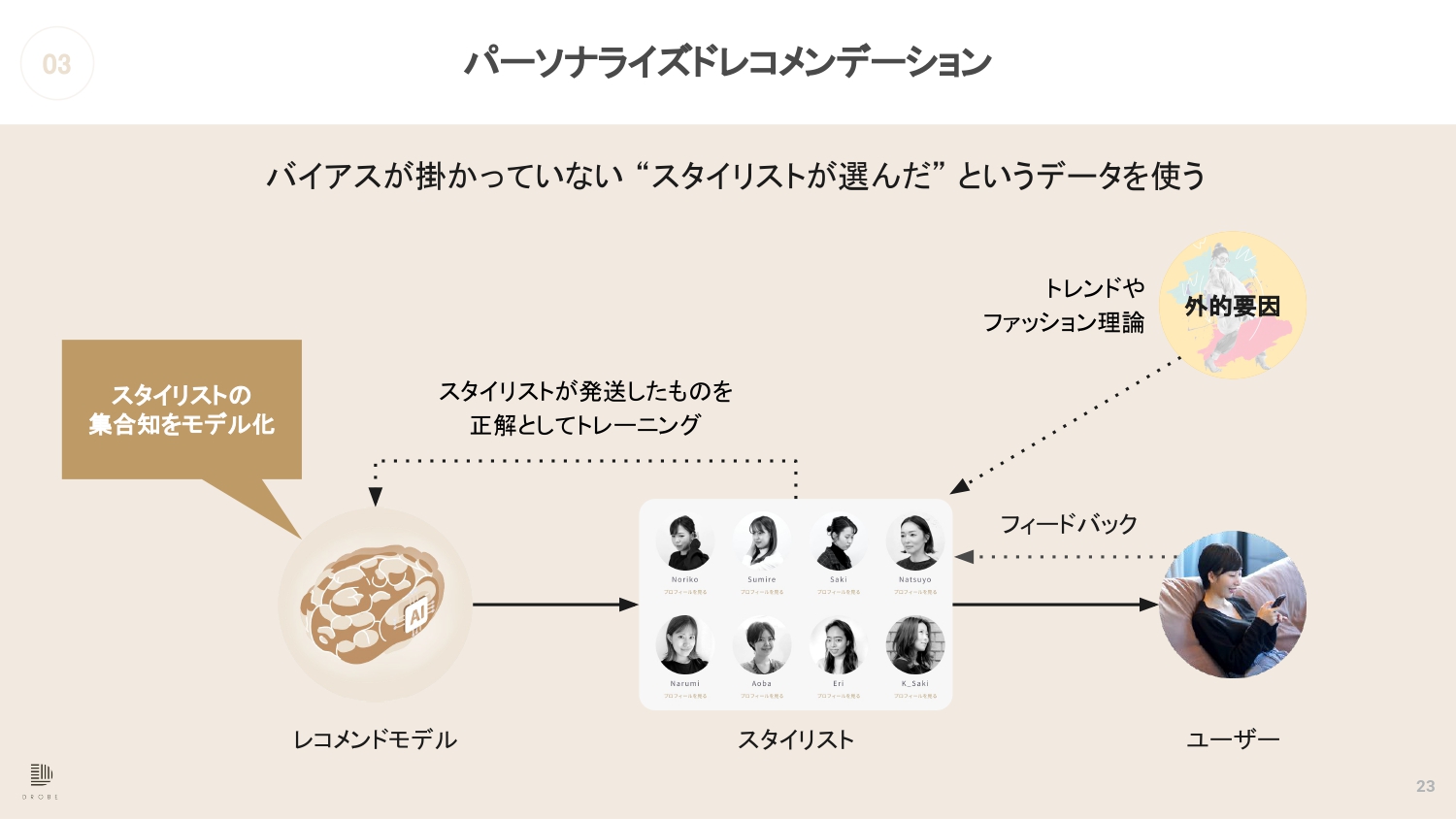
都筑 どうやっているかというと、我々は基本的にはバイアスが掛かっていないと思っているのですが、スタイリストが選んだデータをモデル化しています。
尾原 ああ、そうか。まずはそうですよね。
エキスパートとか、モデルになるベストプラクティスな具象からコントロールした群でトレーニングをするということですね。
都筑 はい。我々のレコメンドモデルはスタイリストの集合知をモデル化しているようなモデルになっています。
先ほど土田さんにおっしゃっていただいた外的要因であるトレンドとか、地理的な要因とか、そういったところは基本的にスタイリストに一旦吸収してもらうような感じですね。
スタイリストがユーザーのフィードバックを受けたりもしますし、ユーザーのプロフィールを見ていろいろ商品を選ぶのですが、そこの部分で何ならちょっとエゴを出してもらうとか。
尾原 ああ、スタイリストに「あえてこういう選択行動をしてください」と指示を出すことで、トレーニングデータの多様性を増すということですね。
都筑 そうですね。
「最終意思決定をするのはあなたたちです」みたいなことをスタイリストにひたすら伝え続けて、その結果、割と人間臭いAIを作りたいという取り組みをしているのが、我々の1つの特徴かなと思っています。
私はそういう観点で、どうやってドメインエキスパートのナレッジをAIに入れていくか、開発者として頑張っていましたが、ちょっと面白い話というか、すごいなと思ったことがあります。
この間スタイリストたちが話しているのを聞いたときに、「そんなセレクトしちゃダメだよ」みたいな文脈の中で、「私たちがAIを作っているんだから、ダメなセレクトはするな」みたいな感じで言い合っていたんです。

尾原 なるほどね、「私たちがAIの模範にならなくてどうするの?」みたいな。
都筑 そうなんですよ。ちょっとしたことではあるのですが、結構すごいなと思いまして。
もはやアルゴリズムも割と一般的というか、日々新しいものが出てきているのでどんどん試していくのですが、「僕らの競争力の源泉ってデータだよね」という話をしたときに、スタイリストが「AIを作るぞ」という意識でやっているのは、ある意味ちょっと新しいAIと人との関わり方なんじゃないかなと思って、ご紹介させていただきたかったんです。
正解データはスタイリストの集合知
武藤 ちなみに、ユーザープロフィールを、16Personalitiesのような性格診断みたいなイメージで分析するモデルを最初に作って、それを初手にやってからこっちに入るイメージがあるのですが、ユーザー側のバイアスが掛かった意見のモデルとかは作成されないんですか?
都筑 トレーニングの正解データをエイッて変えるだけなので、作成することは実際めちゃくちゃ簡単なんですよね。
簡単なのですが、やっても「あまりピンとこない」みたいなことをスタイリストに言われてしまったりするので、あまりやっていないですね。
過去には、これはちょっとスタイリストには申し訳ないですが、トップスタイリストだけのモデルを作るとか、そういうことはいろいろやったのですが、いろいろ試した上で、今はなんかやはり集合知だなみたいなところでやっています
尾原 ちなみに集合知というのが、先ほどの話に引き継ぐと、もともとパネリスト自体に今さっき言った骨格部分とか、もうタグ付けがあって、そのタグの代表データみたいな感じにするのでしょうか?

それとも、このスタイリストとこのユーザーが合うというふうに、ある程度分類するのか、それとも純粋にこの人たちのベストプラクティスのデータの1個として、完全にユーザーに対して1対1でレコメンデーションするかとか、いろいろ迷うじゃないですか、この辺りは。
都筑 ありますね。過去にはやはり、このスタイリストはこういうユーザーが多分得意だとか、そういうことでマッチングアルゴリズムを作ってマッチングさせるみたいなことをしていました。
最終的には彼女らはやはりプロなので「いけます!」という話になって、マッチングなどをしてもあまり意味がなかったんです。
基本的には、個として各ユーザーに向き合っていただいて、本気で提案していただく感じになっています。
尾原 完全にスタイリストが個人個人のスタイリングを選ぶから、そこが完全に教師データとして、その裏側にある服やスタイリストのタグに基づいて、その後のAIの教師データとして完全に1対1対応で、AIを多様性の中で作っていくということですか?
都筑 そうですね。
尾原 結構理想に向かってやっているけれども、……本当にリフトするんですか?
都筑 はい。ただデータとしては、やはりスタイリストの情報は正解として使っているだけですよね。
尾原 ですよね?
都筑 そういった意味では、先ほどちょっとご紹介させていただいた、作られたAIを使って直接ECサイトみたいなもの(ストア)も作っているんですよね(Part.1参照)。
そこでユーザーにある程度「いい並びですね」とか「自分ではちょっと気づけなかったけど、商品に出会えました」みたいなことを言っていただけるので、ある程度やれているんじゃないかなとは思っていますね。

武藤 ちなみに今、正解はスタイリストが選んだ服というお話でした。
イメージで言うと、入力がユーザーのプロフィールとスタイリストが選んだ服で、結果が購入されたかや継続されたかという実績データのKPIなのかなと勝手に思っていたのですが、そうではないという?
都筑 そうですね。入力がユーザーのプロフィールとスタイリストが選んだ商品という感じ…、というか、入力は商品は何でもいいんですよ。
例えばユーザーがサービスに登録したら、ユーザープロフィールと提案する候補の商品のデータを入れてあげて、そうすると、「この商品はスタイリストだったら提案しますか、しませんか?」というのを返してくれるモデルになっていますね。
武藤 じゃあ本当に、真の答えはスタイリストが知っているというモデルということですね。なるほど。
都筑 そうです。我々の大きな仮説は、ドメインエキスパートのほうがユーザーよりも答えを知っているはずだというものです。
武藤 理解しました。ありがとうございます。
土田 すごく腑に落ちたというか。
最近それこそGPTとかがあって、エンタープライズ領域への応用も進んでいます。
そんな中で、よくやられるのが、とにかく世界中のウェブからデータを集めまくってSelf-Supervised Learning(自己教師あり学習)をかけて、そこでおそらく誰よりも世の中のことを知っているという”神様モデル”の作成です。
でもお客さんに提供するときには、やはりちょっとファインチューニングして、お客さんのドメインにちょっと寄せるというか、先ほどのバイアスをちょっと掛けてあげると、あたかもその人にすごく合った、でも一番この世の中を知っている人たちが提案してくれている内容になります。
システムとして、スタイリストさんが作ったAIプラス、先ほどのスタイリストさんに対してレコメンドするというのは、おそらくファインチューニングに相当する部分になっているんじゃないのかなと思います。
そこがすごく上手く動いているなと感じました。
都筑 ありがとうございます。
そうですね。先ほどバイアスを取りたいという話をしたのですが、逆に我々はスタイリストというバイアスを掛けにいっているという見方もできますね。
尾原 そうですよね。バイアスが宝なので、宝としてのバイアスという話と、ユーザーから入ってくるノイズになってしまうバイアスを区別して、ノイズはフィルターしますが、宝としてのバイアスは、むしろそこに集中できるようにしてあげているということですよね。
都筑 はい。
ユーザーのパターン化は大惨敗

尾原 ちなみに、ここに来るまでにアルゴリズム的なとか、モデル的なピボットは結構されたんですよね?
都筑 はい、結構しましたね。
やはり最初は普通に協調フィルタリング(※) というところから。
▶編集注:協調フィルタリングとは、多くのユーザーの嗜好情報を蓄積し、あるユーザーと嗜好の類似した他のユーザーの情報を用いて自動的に推論を行う方法論(Wikipedia)。
尾原 いわゆるAmazonのレコメンデーションみたいなものですね。
都筑 はい。それで始まって、そこから出していったりしました。
あとはもっと初期だと、ちょっと怒られそうなんですが、私はファッションをちょっとナメていて、ユーザーを100分類ぐらいして100クラスターに最初から作ってあるマネキンとマッチングさせればいけるんじゃないかみたいに。
尾原 はいはい、どうせ日本人なので、多様性と言っているけれど、パターンを欲しがっているんでしょ?みたいなね。
都筑 はい。それでやったんですけど、もう見事に惨敗しました。
尾原 はー。
都筑 全然ダメでしたね。
尾原 でも逆に言うと、スタイリストを一番のベストプラクティスデータとしながらやっていくと、1回買ってもらうというより継続というところにきちんと効果が出ているので、自信を持ってお伝えできるということですね。
都筑 はい、そうです。
尾原 ちなみに、このパーソナライズは2つの方向性があります。
やはりアメリカだとエキスパート・イン・ザ・ループみたいな形で、今度はこのスタイリストを成長させるために、どういうAIがアシストするのかみたいな話があります。
中国などでは、ユーザーやファンをスコアリングして、ハイセンスなユーザーをスタイリスト側に引き上げるような、AIが人の成長を加速するみたいな側面があります。
あと多分もう1つあると思うのですが、これをMD(商品企画)のほうにどう生かしていくかみたいなところが、多分次のフェーズなのかなと勝手に思うのですが。
都筑 はい、そこも。
尾原 ごめんなさいね。マニアックにどんどん進んでいって(笑)。
【本セッション記事一覧】
- 日進月歩、AIの最新ソリューションやトレンドを語り尽くす135分!
- ファッションAI「DROBE」が目指す究極のレコメンデーションとは
- AIを育成する「DROBE」スタイリストの集合知が最強である理由
- レコメンドの理由は何? AIの「解釈性」がスタイリストのセンスを言語化する
- AI活用により「作る前に販売、廃棄減」が可能になるファッション産業の未来
- 複雑なサプライチェーンの計画策定最適化を行う「ALGO ARTIS」
- 1年あたり数億円のインパクトも! 計画最適化で削減されるコストの内訳
- 人間の考えるプロセスに近い、ヒューリスティック最適化に挑むエンジニアたち
- 人間の高度な知的活動のAI化には価値がある
- “人間の目を超える目”で、何が可能になるのか
- ここまでできる! 1人の客の行動、商品への接触をデータ化する「エッジAI」
- AIはもう飛び道具ではなく、課題を解決するITの技術となる【終】
(続)
▶カタパルトの結果速報、ICCサミットの最新情報は公式Twitterをぜひご覧ください!
▶新着記事を公式LINEで配信しています。友だち申請はこちらから!
▶過去のカタパルトライブ中継のアーカイブも見られます! ICCのYouTubeチャンネルはこちらから!
編集チーム:小林 雅/浅郷 浩子/戸田 秀成/小林 弘美